Last updated on 2020-6-24…
很早很早之前的笔记,来自多页的内容,汇总到这篇,所以写的会很乱…
最早之前学开发的时候,只在微博和csdn上写过寥寥几篇,但并没有养成写博客习惯。
后来想做一些回顾的时候,最终还是发现纸质笔记没有博客来的实用,于是就从此开始督促自己养成写博客的习惯。
MVC框架
用户首先在界面中进行人机交互,然后请求发送到控制器,控制器根据请求类型和请求的指令发送到相应的模型,模型可以与数据库进行交互,进行增删改查操作,完成之后,根据业务的逻辑选择相应的视图进行显示,此时用户获得此次交互的反馈信息,用户可以进行下一步交互,如此循环。
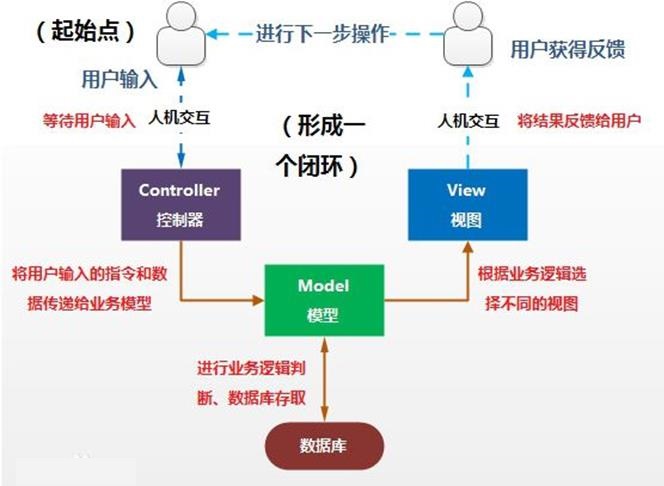
Model模型:模型表示业务规则。在MVC的三个部件中,模型拥有最多的处理任务。被模型返回的数据是中立的,模型与数据格式无关,这样一个模型能为多个视图提供数据,由于应用于模型的代码只需写一次就可以被多个视图重用,所以减少了代码的重复性。
View视图:用户看到并与之交互的界面。比如由html元素组成的网页界面,或者软件的客户端界面。MVC的好处之一在于它能为应用程序处理很多不同的视图。在视图中其实没有真正的处理发生,它只是作为一种输出数据并允许用户操纵的方式。
Controller控制器:控制器接受用户的输入并调用模型和视图去完成用户的需求,控制器本身不输出任何东西和做任何处理。它只是接收请求并决定调用哪个模型构件去处理请求,然后再确定用哪个视图来显示返回的数据。
竟然在面试MSRA算法岗的时候被问到了这个,凭借着自己模模糊糊的印象算是勉强答上来了…
http请求
流程
-
客户端向一个需要https访问的网站
发起请求。 -
服务器将
证书发送给客户端进行校验。证书里面包含了其公钥。 -
校验成功之后,客户端会生成一个
随机串然后使用服务器证书的公钥进行加密之后发送给服务器。 -
服务器通过使用自己的
私钥解密得到这个随机值。 -
服务器从此开始使用这个随机值进行
对称加密开始和客户端进行通信。 -
客户端拿到值用对称加密方式,使用随机值进行
解密。
要点
客户端到底如何来校验对方发过来的数字证书是否有效?
- 首先在本地电脑寻找是否有这个服务器证书上的ca机构的根证书。如果有继续下一步,如果没有弹出警告。
- 使用ca机构根证书的公钥对服务器证书的指纹和指纹算法进行解密。
- 得到指纹算法之后,拿着这个指纹算法对服务器证书的摘要进行计算得到指纹。
- 将计算出的指纹和从服务器证书中解密出的指纹对比看是否一样如果一样则通过认证。
为什么不一直使用非对称进行加密,而是在类似握手之后开始使用对称加密算法进行https通信?
- 非对称加密的消耗和所需的计算以及时间远比对称加密消耗要大,所以在握手和认证之后,服务器和客户端就开始按照约定的随机串,对后续的数据传输进行加密。
Maven组件
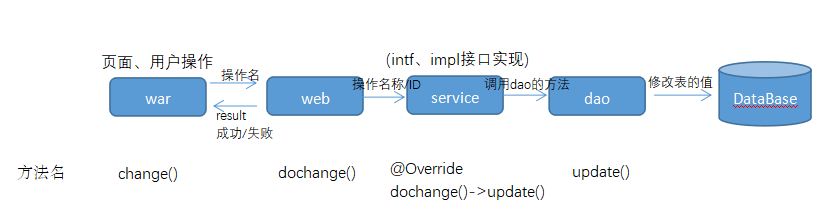
common 公用层:一般公司都会有固定的jar,几个项目通用dao 数据操作层:DB操作都写在这dmo 数据库交互持久层service 基本业务处理层war 页面层:页面、配置文件以及最终发布的war包web 页面交互层- …xml
通信组件
1、socket套接字(协议,IP地址,端口):
- 套接字是平等的,即client与server无差别
- import java.net.Socket
- socket套接字(协议,IP地址,端口)
- socket是对TCP/IP协议的封装,本身不是协议,而是一个API
2、netty网络通讯框架
- 三层式架构:Reactor通信调度层(不同的Reactor Pool和Channel)、Pipeline职责链(不同的handler)、Service业务逻辑层(各种协议)
- socket + TCP + NIO + 职责链 + java并发包(阻塞队列)
- client发起请求到Reactor Thread Accepter,由它Dispatcher到Reactor Thread Pool线程池,然后队列由Handler负责read/write/decode
关于通信组件,大公司都会有自己的框架,本科实习的时候接触过,但是不能透露哈
JMS 消息中间件
Java消息服务即JMS(Java Message Service),是一个java平台中关于面向消息中间件的API,用于在两个应用程序之间或分布式系统中发送消息,进行异步通信。

- 优点:系统与服务调用的
解耦、异步调用、可横向扩展、安全可靠、顺序保证(kafka)、… - 定义了2种消息模式:队列模型(p2p)、主题模型(pub/sub)
- 定义了6种消息类型:TextMessage、MapMessage、BytesMessage、StreamMessage、ObjectMessage、Message
队列模型:客户端包括生产者和消费者。队列中的每一条消息只能被一个消费者消费,不会被其他消费者重复消费。消费者可以随时消费队列中的消息。
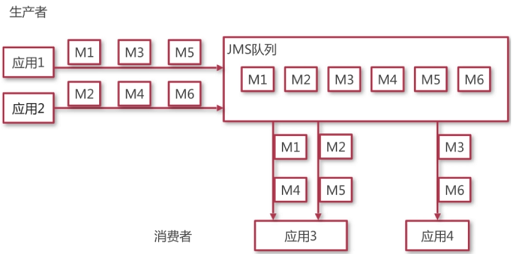
主题模型:客户端包括发布者和订阅者。主题中的所有消息能被任一订阅者消费。消费者不能消费订阅之前就发送到主题中的消息。
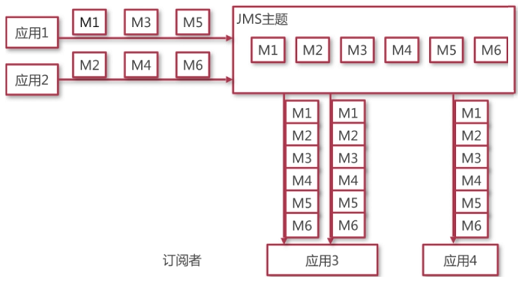
ActiveMQ、RabbitMQ、Kafka

Redis缓存
key-value内存数据库,在我们往redis上写数据的时候,redis服务也会定时的往文件中写数据。
支持5种数据类型:strings 字符串、lists 字符串列表、sets 字符串集合、 sorted sets 有序字符串集合、 hashes 哈希
支持2种持久化:RDB快照方式(Redis DataBase)、AOF指令复行方式(Append Only File)
3种集群方案:
- Redis Cluster(官方):主从分离+选举算法
- Redis sharding 集群(Cluster之前):哈希散列+一致性哈希算法
- Redis 代理中间件 twemproxy:request -> key-value -> Redis -> database
SQL
1、SQL语句的4个处理阶段:(始末包含创建游标open和关闭游标close)
Prase 解析:查共享池、检查语法/语义/权限、合并视图、子查询、确定执行计划Bind 绑定:查找绑定变量、赋值Execute 执行:执行、I/O、排序Fetch 提取:返回结果、排序、使用Array Fetch机制
2、SQL共享原理:
- Oracle将执行过的SQL语句存放在共享池内存中,再次访问时,先在内存池中找相同语句,从而用最好的执行方案执行操作。
可是,该功能并不适用于多表连接查询。
3、重编译问题:
- SQL访问一次,就要在内存中硬解析一次。
解决:绑定变量(硬解一次,重复调用) EXEC SQL PREPARE/EXECUTE/COMMIT …
4、调优领域:(设计 > SQL语句 > 环境 > 实例)
- 应用程序级:SQL语句、管理变化 (应用程序开发人员)
- 实例级:内存、数据结构、实例配置(数据库管理员)
- 操作系统级:I/O、SWAP、Parameters(系统管理员)
5、好的SQL语句:简单&模块化、易读&易维护、节省资源、不造成死锁
数据库建表
1、xxID/xx号:VARCHAR2(32),手机号(16),电话(16)
2、所在省份/城市:VARCHAR2(32),所在地/地址(64)
3、学校名称/院系/校区/专业/班级:VARCHAR2(128)
4、xx标识:NUMBER(1),xx状态:VARCHAR2(2)
5、姓名/用户名 VARCHAR2(32),性别(4),邮箱(64)
6、xx原因:VARCHAR2(256),xx附件(512)
7、xx次数:NUMBER
8、xx收入/费用:INTEGER
9、xx率:NUMBER(8,5)
10、xx额度/金额:NUMBER(14,2)
11、xx时间:DATE
12、是否xx:VARCHAR2(2)
字段赋值设计
假设要创建A字段,并且参考来源a字段:
- 没有a字段,赋值 -1
- 有a字段,但是类型是null,赋值为 99
- 有a字段,类型是String,类型转换为int并赋值;如果类型转换失败,赋值-2
- 有a字段,字段类型非null、非String,赋值为-3
- A字段如果json解析异常,赋值-4
HTML
1、标签
标题:<h1>...</h1>,h1到h6为从大到小
段落:<p></p>
链接:<a href="http://...">XX网站</a>
图像:<img src="img/title.png"/>
换行:<br/>
水平:线<hr/>
...
2、块元素
body, div, span, p, table, form
3、表格
<table>
<tr>
<td>...</td>
<tr>
<table>
4、列表
ol有序列表、ul无序列表、li列表元素
5、布局
div、table
6、动作属性
<form name="input" action="xx.jsp" method="post">
Username:
<input type="text" name="user"/>
</form>
其他知识
分布式算法
内容太多,这里只挑一部分简单罗列一下。
- 时钟:
物理时钟Physical Clocks(实际应用)、逻辑时钟Logical Clocks、向量时钟Vector Clocks(学术理想) - 以数据为中心的一致性模型:
- 不使用同步操作的一致性:
顺序一致性、因果一致性、FIFO队列一致性、严格一致性、线性一致性 - 使用同步操作的一致性:
弱一致性、释放一致性、入口一致性
- 不使用同步操作的一致性:
- 以客户为中心的一致性模型:
- 最终一致性:
单调读(分布式电子邮件数据库)、单调写(windows 更新)、写后读(分布式web站点的页面更新问题)、读后写(分布式bbs系统的回帖问题)
- 最终一致性:
- Mutual exclusion互斥:基于令牌、基于许可
- Fault Tolerance容错性:
Availability可用性、Reliability可靠性、Safety安全性、Maintainability可维护性
设计题: 我们有一个业务系统,每天要处理1000万次服务请求,如何设计这个系统?
系统设计方面:- 采用分布式系统设计,一个或层次组合的master节点负责分发服务请求,多个worker节点负责处理请求,通过RPC等远程框架实现功能。
- 保证一定的冗余性(backup、多余机器)和节点间的负载均衡。
- 如果服务请求涉及的数据量或计算量太大,需要考虑hadoop,spark这种平台。
安全方面:- 要通过防火墙、蜜罐等方式防止DDOS和渗透类的攻击。
大数据计算框架
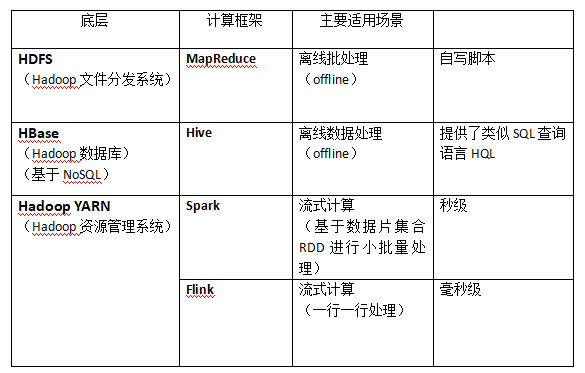
1、批处理框架:重点关心数据处理的吞吐量
- Map/Reduce(Hadoop)、DAG(Spark)、图计算(PowerGraph)
MR 基于任务调度,主要应用于一次性的计算,
不适合机器学习等需要迭代计算的场景,因此在2013年发布了Hadoop2.x YARN版本,将Hadoop(集群资源)与MR(计算任务)解耦开来。同期早4个月,基于Scala语言开发的Spark发布了,和YARN在架构上很相似。
2、流计算框架:重点关心处理的实时性
- 实时(Storm、Flink)、小批量(Strom Trident、Spark Streaming)
storm保证消息可靠性的过程:为每条消息分派一个ID作为唯一性标识,在生成和处理时
分别被异或一次,则成功执行所有消息均被异或两次,因此最后状态为0,若不为0则中间出了问题。
3、增量计算框架:重点关心如何避免重复计算(如何只对部分新增数据进行计算,来极大提升计算过程的效率)
- Percolator、Kineograph、Galaxy
4、交互式分析框架:UI使用的方便性
- Hive、Kylin、Spark SQL、Flink Table
Hadoop
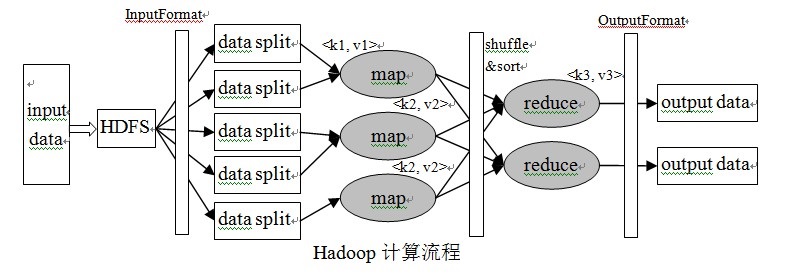
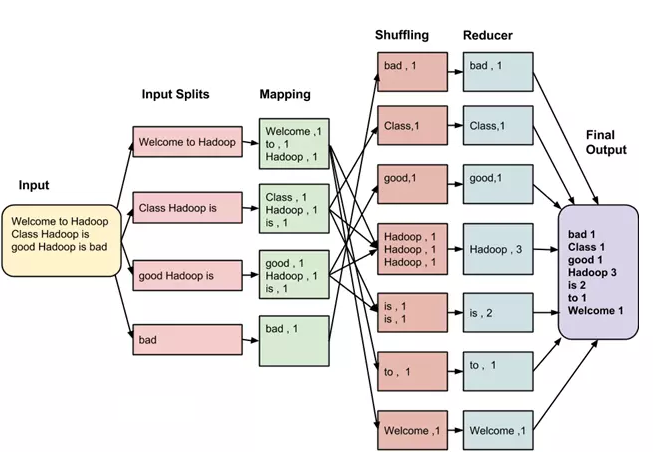
输入到每一个阶段均是键 - 值对。此外,每一个程序员需要指定两个函数:map函数和reduce函数,整个过程要经历三个阶段执行。
1、拆分 - Split
- 输入到MapReduce工作被划分成固定大小的块叫做 input splits ,输入折分是由单个映射消费输入块。
2、映射 - Mapping
- 这是在 map-reduce 程序执行的第一个阶段。在这个阶段中的每个分割的数据被传递给映射函数来产生输出值。在我们的例子中,映射阶段的任务是计算输入分割出现每个单词的数量(更多详细信息有关输入分割在下面给出)并编制以某一形式列表<单词,出现频率>
3、重排 - Shuffing
- 这个阶段消耗映射阶段的输出。它的任务是合并映射阶段输出的相关记录。在我们的例子,同样的词汇以及它们各自出现频率。
4、合并 - Reducing
- 在这一阶段,从重排阶段输出值汇总。这个阶段结合来自重排阶段值,并返回一个输出值。总之,这一阶段汇总了完整的数据集。在我们的例子中,这个阶段汇总来自重排阶段的值,计算每个单词出现次数的总和。
Hadoop常用命令:(第一个…为源路径,后一个为目标路径,一般是本地路径)
- 访问:/hadoop fs
-ls… - 合并拷贝至本地:/hadoop fs
-getmerge… … - 拷贝单文件:/hadoop fs
-get…/part1 … - 访问并摘取一部分(100行):/hadoop fs
-text…/all_host_data/* | head -n 100>>sample.txt
本地调试命令: cat input.txt | python mapper.py | sort | reducer.py »output.txt
kill掉指定字符的多个进程: ps -ef | grep 进程名 | grep -v grep | cut -c 9-15 | xargs kill -s 9
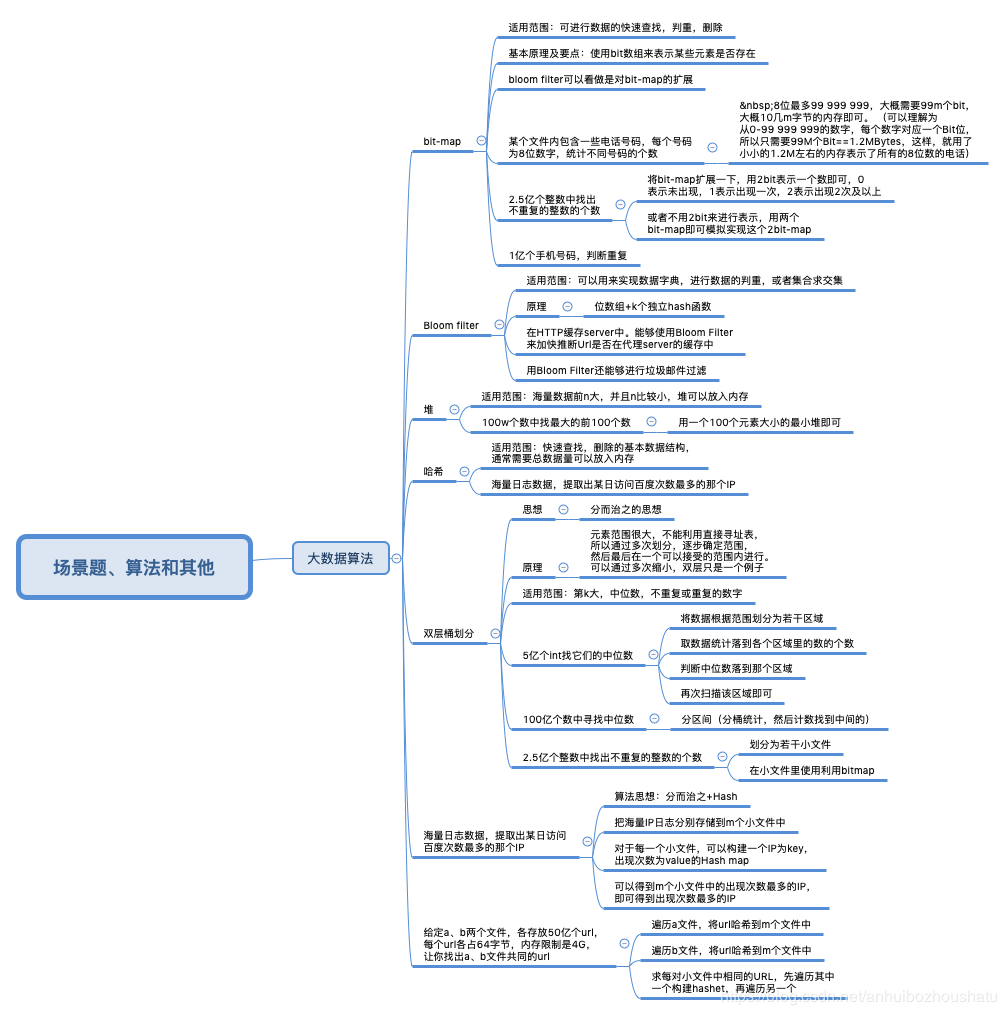
大数据算法面试题