Last updated on 2018-7-20…
集成方法是由多个较弱的模型集成模型组,一般的弱分类器可以是DT, SVM, NN, KNN等构成。
其中的模型可以单独进行训练,并且它们的预测能以某种方式结合起来去做出一个总体预测。
该算法主要的问题是要找出哪些较弱的模型可以结合起来,以及如何结合的方法。
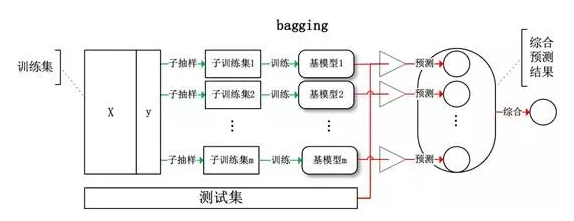
Bagging(划分数据子集并行)例如Random forest
基于数据随机重抽样的分类器构建方法。从训练集从进行子抽样组成每个基模型所需要的子训练集,对所有基模型预测的结果进行综合产生最终的预测结果。
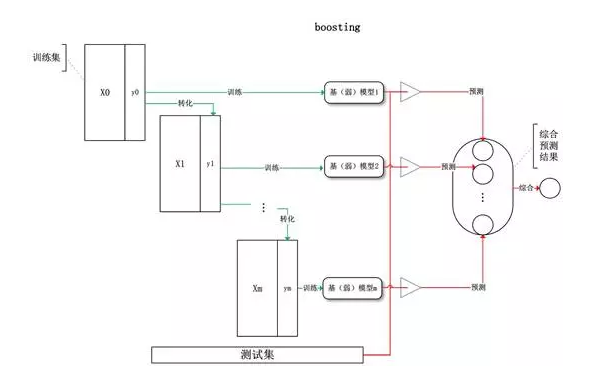
Boosting(每次转化数据全集串行)例如Adaboost、GBM、GBRT
训练过程为阶梯状,基模型按次序一一进行训练(实现上可以做到并行)。
基模型的训练集按照某种策略每次都进行一定的转化,每次都是提高前一次分错了的数据集的权值,最后对所有基模型预测的结果进行线性组合产生最终的预测结果。
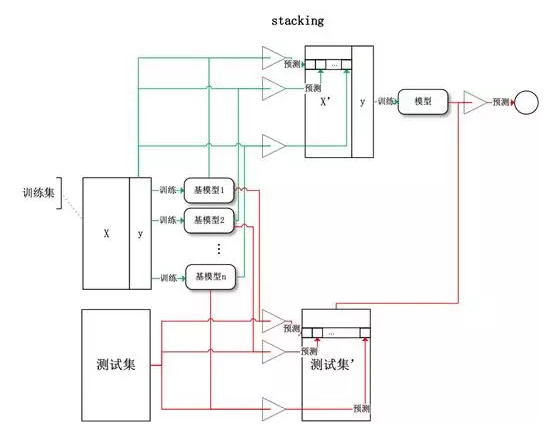
Stacking (双层分类器,第二层仅一个分类器)例如Blending、MLR、BMA
将训练好的所有基模型对训练基进行预测,第j个基模型对第i个训练样本的预测值将作为新的训练集中第i个样本的第j个特征值,最后基于新的训练集进行训练。
同理,预测的过程也要先经过所有基模型的预测形成新的测试集,最后再对测试集进行预测:
结束语
国内,南京大学的周志华教授对集成学习有深入的研究,其在09年发表的一篇概述性论文《Ensemple Learning》对这三种架构做出了明确的定义。