Last updated on 2020-3-12…
本篇是上一篇《python特征工程篇》的一个子集,由于内容较多而单独出一篇。(»原文链接)
特征选择
特征选择是特征工程里的一个重要问题,其目标是寻找最优特征子集。
多维特征一方面可能会导致维数灾难,另一方面很容易导致过拟合,因此需要做降维处理,常见的降维方法有 PCA,t-SNE(计算复杂度很高)。 比赛中使用PCA效果通常并不好,因为大多数特征含有缺失值且缺失值个数太多,而 PCA 前提假设数据呈高斯分布,赛题数据很可能不满足。
- Filter:过滤法,按照发散性或者相关性对各个特征进行评分,设定阈值或者待选择阈值的个数,选择特征。
- Wrapper:包装法,根据目标函数(通常是预测效果评分),每次选择若干特征,或者排除若干特征。
- Embedded:嵌入法,先使用某些机器学习的算法和模型进行训练,得到各个特征的权值系数,根据系数从大到小排序选择特征。类似于Filter方法,但是是通过训练来确定特征的优劣。
常见方法:
- 最大信息系数(MIC):画热力图,取相关性小的用于模型融合
- 皮尔森相关系数(衡量变量间的线性相关性)
- 正则化方法(L1,L2)
- 基于模型的特征排序方法(这种比较高效:模型学习的过程和特征选择的过程是同时进行的)
概率密度图
import matplotlib.pyplot as plt
import seaborn as sns
def plot_kde(train, test, col, values=True):
fig,ax =plt.subplots(1,2,figsize=(15,5))
sns.kdeplot(train[col][train['label']==0],color='g',ax=ax[0])
sns.kdeplot(train[col][train['label']==1],color='r',ax=ax[0])
sns.kdeplot(train[col][train['label']==-1],color='y',ax=ax[0])
sns.kdeplot(train[col],color='y',ax=ax[1])
sns.kdeplot(test[col],color='b',ax=ax[1])
plt.show()
del train, col,test
for one_col in train.columns:
plot_kde(train,test,one_col)
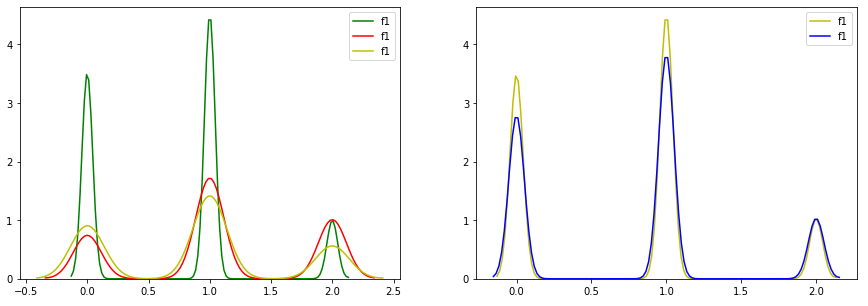
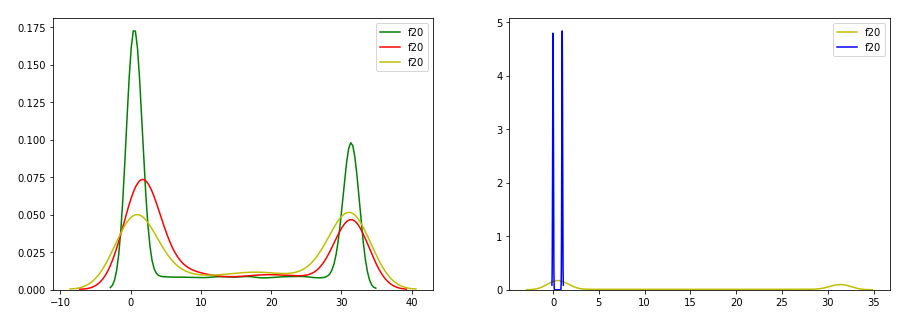
可见特征f1是要保留的,特征f20是要舍弃的
热力图
def corr_heatmap(data):
correlations = data.corr()
# Create color map ranging between two colors
cmap = sns.diverging_palette(220, 10, as_cmap=True)
fig, ax = plt.subplots(figsize=(10,10))
sns.heatmap(correlations, cmap=cmap, vmax=1.0, center=0, fmt='.2f',
square=True, linewidths=.5, annot=True, cbar_kws={"shrink": .75})
plt.show()
corr_heatmap(v)
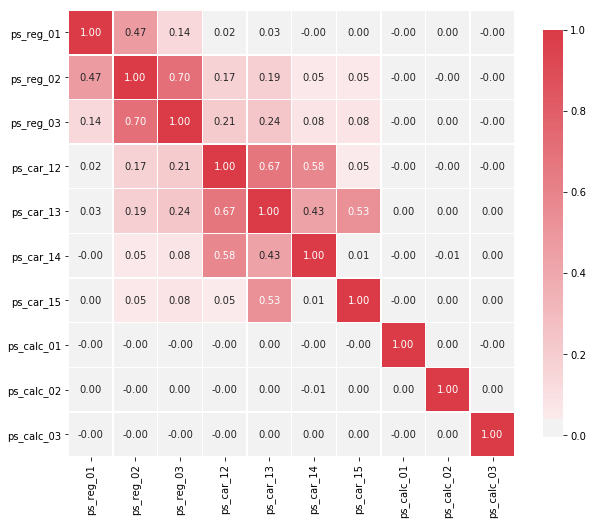
以下变量之间存在很强的相关性:
- ps_reg_02 and ps_reg_03 (0.7)
- ps_car_12 and ps_car13 (0.67)
- ps_car_12 and ps_car14 (0.58)
- ps_car_13 and ps_car15 (0.67)
Seaborn有一些方便的图表可视化变量之间的(线性)关系。我们可以使用配对图来可视化变量之间的关系。但由于热图已显示有限数量的相关变量,我们将分别查看每个高度相关的变量。注意:我采用训练数据的采样来加快过程。
卡方检验
from sklearn.feature_extraction.text import CountVectorizer
train_new = pd.DataFrame()
test_new = pd.DataFrame()
cntv = CountVectorizer()
cntv.fit(data['user_tags'])
train_a = cntv.transform(train['user_tags'])
test_a = cntv.transform(test['user_tags'])
train_new = sparse.hstack((train_new, train_a), 'csr', 'bool')
test_new = sparse.hstack((test_new, test_a), 'csr', 'bool')
# 卡方检验
SKB = SelectPercentile(chi2, percentile=95).fit(train_new, train_y)
train_new = SKB.transform(train_new)
test_new = SKB.transform(test_new)
比赛通常基于 xgboost 来做,训练 xgboost 的过程就是对特征重要性进行排序的过程。
xgboost特征排序
利用model.get_fscore()来获得特征得分,然后排序成表
import xgboost as xgb
import os
os.mkdir('model')
os.mkdir('featurescore')
y = train.label
X = train.drop(['uid','label'],axis=1)
dtrain = xgb.DMatrix(X, label=label)
params={
'booster':'gbtree',
'objective': 'rank:pairwise',
'scale_pos_weight': float(len(y)-sum(y))/float(sum(y)),
'eval_metric': 'auc',
'gamma':gamma,
'max_depth':max_depth,
'lambda':lambd,
'subsample':subsample,
'colsample_bytree':colsample_bytree,
'min_child_weight':min_child_weight,
'eta': 0.04,
'seed':random_seed
}
watchlist = [(dtrain,'train')]
model = xgb.train(params,dtrain,num_boost_round=num_boost_round,evals=watchlist)
model.save_model('./model/xgb{0}.model'.format(iteration))
#get feature score
feature_score = model.get_fscore()
feature_score = sorted(feature_score.items(), key=lambda x:x[1],reverse=True)
fs = []
for (key,value) in feature_score:
fs.append("{0},{1}\n".format(key,value))
with open('./featurescore/feature_score_{0}.csv'.format(iteration),'w') as f:
f.writelines("feature,score\n")
f.writelines(fs)
实践代码
实际需要随机设置不同参数,跑若干次xgb模型
import pandas as pd
import xgboost as xgb
import sys,random
import cPickle
import os
os.mkdir('featurescore')
os.mkdir('model')
os.mkdir('preds')
#load data
train_x = pd.read_csv("../../data/train_x_rank.csv")
train_y = pd.read_csv("../../data/train_y.csv")
train_xy = pd.merge(train_x,train_y,on='uid')
y = train_xy.y
train_x= train_xy.drop(["uid",'y'],axis=1)
X = train_x/15000.0
dtrain = xgb.DMatrix(X, label=y)
test = pd.read_csv("../../data/test_x_rank.csv")
test_uid = test.uid
test = test.drop("uid",axis=1)
test_x = test/5000.0
dtest = xgb.DMatrix(test_x)
def pipeline(iteration,random_seed,gamma,max_depth,lambd,subsample,colsample_bytree,min_child_weight):
params={
'booster':'gbtree',
'objective': 'binary:logistic',
'scale_pos_weight': float(len(y)-sum(y))/float(sum(y)),
'eval_metric': 'auc',
'gamma':gamma,
'max_depth':max_depth,
'lambda':lambd,
'subsample':subsample,
'colsample_bytree':colsample_bytree,
'min_child_weight':min_child_weight,
'eta': 0.04,
'seed':random_seed,
'nthread':8
}
watchlist = [(dtrain,'train')]
model = xgb.train(params,dtrain,num_boost_round=1350,evals=watchlist)
model.save_model('./model/xgb{0}.model'.format(iteration))
#predict test set
test_y = model.predict(dtest)
test_result = pd.DataFrame(columns=["uid","score"])
test_result.uid = test_uid
test_result.score = test_y
test_result.to_csv("./preds/xgb{0}.csv".format(iteration),index=None,encoding='utf-8')
#save feature score
feature_score = model.get_fscore()
feature_score = sorted(feature_score.items(), key=lambda x:x[1],reverse=True)
fs = []
for (key,value) in feature_score:
fs.append("{0},{1}\n".format(key,value))
with open('./featurescore/feature_score_{0}.csv'.format(iteration),'w') as f:
f.writelines("feature,score\n")
f.writelines(fs)
if __name__ == "__main__":
random_seed = range(1000,2000,10)
gamma = [i/1000.0 for i in range(100,200,1)]
max_depth = [6,7,8]
lambd = range(100,200,1)
subsample = [i/1000.0 for i in range(500,700,2)]
colsample_bytree = [i/1000.0 for i in range(250,350,1)]
min_child_weight = [i/1000.0 for i in range(200,300,1)]
random.shuffle(random_seed)
random.shuffle(gamma)
random.shuffle(max_depth)
random.shuffle(lambd)
random.shuffle(subsample)
random.shuffle(colsample_bytree)
random.shuffle(min_child_weight)
#save params for reproducing
with open('params.pkl','w') as f:
cPickle.dump((random_seed,gamma,max_depth,lambd,subsample,colsample_bytree,min_child_weight),f)
#to reproduce my result, uncomment following lines
"""
with open('params_for_reproducing.pkl','r') as f:
random_seed,gamma,max_depth,lambd,subsample,colsample_bytree,min_child_weight = cPickle.load(f)
"""
#train 100 xgb
for i in range(100):
pipeline(i,random_seed[i],gamma[i],max_depth[i%3],lambd[i],subsample[i],colsample_bytree[i],min_child_weight[i])