Last updated on 2018-9-25…
本篇是特征工程和模型之外的技巧篇,方法是增加新样本,即利用半监督代替过采样,以解决样本不平衡问题。(»原文链接)
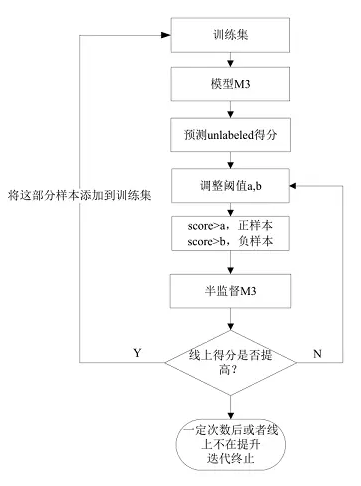
迭代半监督
- 利用最好的模型预测无标签数据,调整阈值 a,b 将样本添加到训练集,其中 01 样本比例为 5:1~9:1。如果线上有提高,将这部分样本添加到训练集继续训练融合来预测无标签数据,重复迭代。
import pandas as pd
import xgboost as xgb
import sys,random
import cPickle
import os
os.mkdir('featurescore')
os.mkdir('model')
os.mkdir('preds')
#设置a和b的值(0~1之间)
a = 0.16
b = 0.80
#离散化特征的计数特征
test_nd = pd.read_csv('../data/test_x_nd.csv')[['uid','n1','n2','n3','n4','n5','n6','n7','n8','n9','n10']]
train_nd = pd.read_csv('../data/train_x_nd.csv')[['uid','n1','n2','n3','n4','n5','n6','n7','n8','n9','n10']]
trainunlabeled_nd = pd.read_csv('../data/train_unlabeled_nd.csv')[['uid','n1','n2','n3','n4','n5','n6','n7','n8','n9','n10']]
#缺失值个数的离散化特征
test_dnull = pd.read_csv('../data/test_x_null.csv')[['uid','discret_null']]
train_dnull = pd.read_csv('../data/train_x_null.csv')[['uid','discret_null']]
trainunlabeled_dnull = pd.read_csv('../data/train_unlabeled_null.csv')[['uid','discret_null']]
#n1~n10,discret_null 这11维特征不做特征选择,先放在一起
eleven_feature = ['n1','n2','n3','n4','n5','n6','n7','n8','n9','n10','discret_null']
test_eleven = pd.merge(test_nd,test_dnull,on='uid')
train_eleven = pd.merge(train_nd,train_dnull,on='uid')
trainunlabeled_eleven = pd.merge(trainunlabeled_nd,trainunlabeled_dnull,on='uid')
del test_dnull,train_dnull,trainunlabeled_dnull
del test_nd,train_nd,trainunlabeled_nd
#离散特征
discret_feature_score = pd.read_csv('./discret_feature_score.csv')
fs = list(discret_feature_score.feature[0:500])
discret_train = pd.read_csv("../data/train_x_discretization.csv")[['uid']+fs]
discret_test = pd.read_csv("../data/test_x_discretization.csv")[['uid']+fs]
discret_train_unlabeled = pd.read_csv("../data/train_unlabeled_discretization.csv")[['uid']+fs]
#排序特征
rank_feature_score = pd.read_csv('./rank_feature_score.csv')
fs = list(rank_feature_score.feature[0:500])
rank_train_x = pd.read_csv("../data/train_x_rank.csv")
rank_train = rank_train_x[fs] / float(len(rank_train_x))
rank_train['uid'] = rank_train_x.uid
rank_test_x = pd.read_csv("../data/test_x_rank.csv")
rank_test = rank_test_x[fs] / float(len(rank_test_x))
rank_test['uid'] = rank_test_x.uid
rank_train_unlabeled_x = pd.read_csv("../data/train_unlabeled_rank.csv")
rank_train_unlabeled = rank_train_unlabeled_x[fs] / float(len(rank_train_unlabeled_x))
rank_train_unlabeled['uid'] = rank_train_unlabeled_x.uid
del rank_train_x,rank_test_x,rank_train_unlabeled_x
#原始特征
raw_feature_score = pd.read_csv('./raw_feature_score.csv')
fs = list(raw_feature_score.feature[0:500])
raw_train_x = pd.read_csv("../data/train_x.csv")[['uid']+fs]
raw_train_y = pd.read_csv("../data/train_y.csv")
raw_train = pd.merge(raw_train_x,raw_train_y,on='uid')
del raw_train_x,raw_train_y
raw_test = pd.read_csv("../data/test_x.csv")[['uid']+fs]
raw_train_unlabel = pd.read_csv('../data/train_unlabeled.csv')[['uid']+fs]
#将原始特征,排序特征,离散特征,以及其他11维特征(n1~n10,discret_null)合并
train = pd.merge(raw_train,rank_train,on='uid')
train = pd.merge(train,discret_train,on='uid')
train = pd.merge(train,train_eleven,on='uid')
test = pd.merge(raw_test,rank_test,on='uid')
test = pd.merge(test,discret_test,on='uid')
test = pd.merge(test,test_eleven,on='uid')
test_uid = test.uid
#从无标签数据里选取预测score<a的样本作为负样本,选取预测score>b的样本作为正样本,添加到训练集合
m3_predict_trainunlabeled_data = pd.read_csv('./m3_predict_trainunlabeled_data.csv')
unlabeldata_0 = m3_predict_trainunlabeled_data[m3_predict_trainunlabeled_data.score<a]
tmp = pd.merge(unlabeldata_0,raw_train_unlabel,on="uid",how="left")
tmp1 = pd.merge(tmp,rank_train_unlabeled,on="uid",how="left")
tmp2 = pd.merge(tmp1,trainunlabeled_eleven,on="uid",how="left")
neg_sample = pd.merge(tmp2,discret_train_unlabeled,on="uid",how="left")
neg_sample = neg_sample.drop(["score","uid"],axis=1)
neg_sample['y'] = [0 for _ in range(len(neg_sample))]
unlabeldata_1 = m3_predict_trainunlabeled_data[m3_predict_trainunlabeled_data.score>b]
tmp = pd.merge(unlabeldata_1,raw_train_unlabel,on="uid",how="left")
tmp1 = pd.merge(tmp,rank_train_unlabeled,on="uid",how="left")
tmp2 = pd.merge(tmp1,trainunlabeled_eleven,on="uid",how="left")
pos_sample = pd.merge(tmp2,discret_train_unlabeled,on="uid",how="left")
pos_sample = pos_sample.drop(["score","uid"],axis=1)
pos_sample['y'] = [1 for _ in range(len(pos_sample))]
samples_from_unlabel = pd.concat([neg_sample,pos_sample])
print "select {0} samples from train_unlabel.csv".format(len(samples_from_unlabel))
del unlabeldata_0,unlabeldata_1,tmp,tmp1,tmp2
#将缺失值个数在区间5(即缺失值个数大于194的)的样本去掉。这个对结果的提升很大,从0.723提高到接近0.725
train = train[train.discret_null!=5]
samples_from_unlabel = samples_from_unlabel[samples_from_unlabel.discret_null!=5]
def pipeline(iteration,random_seed,feature_num,rank_feature_num,discret_feature_num,gamma,max_depth,lambd,subsample,colsample_bytree,min_child_weight):
raw_feature_selected = list(raw_feature_score.feature[0:feature_num])
rank_feature_selected = list(rank_feature_score.feature[0:rank_feature_num])
discret_feature_selected = list(discret_feature_score.feature[0:discret_feature_num])
train_xy = train[eleven_feature+raw_feature_selected+rank_feature_selected+discret_feature_selected+['y']]
train_xy[train_xy<0] = -1
test_x = test[eleven_feature+raw_feature_selected+rank_feature_selected+discret_feature_selected]
test_x[test_x<0] = -1
neg_pos = samples_from_unlabel[eleven_feature+raw_feature_selected+rank_feature_selected+discret_feature_selected+['y']]
neg_pos[neg_pos<0] = -1
#将从无标签数据中选取出的负样本和原始训练数据合并
train_xy = pd.concat([train_xy,neg_pos])
y = train_xy.y
X = train_xy.drop(['y'],axis=1)
#xgboost start
dtest = xgb.DMatrix(test_x)
dtrain = xgb.DMatrix(X, label=y)
params={
'booster':'gbtree',
'objective': 'binary:logistic',
'scale_pos_weight': float(len(y)-sum(y))/float(sum(y)),
'eval_metric': 'auc',
'gamma':gamma,
'max_depth':max_depth,
'lambda':lambd,
'subsample':subsample,
'colsample_bytree':colsample_bytree,
'min_child_weight':min_child_weight,
'eta': 0.08,
'seed':random_seed,
'nthread':8
}
watchlist = [(dtrain,'train')]
model = xgb.train(params,dtrain,num_boost_round=1500,evals=watchlist)
model.save_model('./model/xgb{0}.model'.format(iteration))
#predict test set
test_y = model.predict(dtest)
test_result = pd.DataFrame(test_uid,columns=["uid"])
test_result["score"] = test_y
test_result.to_csv("./preds/xgb{0}.csv".format(iteration),index=None,encoding='utf-8')
#save feature score
feature_score = model.get_fscore()
feature_score = sorted(feature_score.items(), key=lambda x:x[1],reverse=True)
fs = []
for (key,value) in feature_score:
fs.append("{0},{1}\n".format(key,value))
with open('./featurescore/feature_score_{0}.csv'.format(iteration),'w') as f:
f.writelines("feature,score\n")
f.writelines(fs)
if __name__ == "__main__":
"""
random_seed = range(1000,2000,10)
feature_num = range(300,500,2)
rank_feature_num = range(300,500,2)
discret_feature_num = range(64,100,1)
gamma = [i/1000.0 for i in range(0,300,3)]
max_depth = [6,7,8]
lambd = range(500,700,2)
subsample = [i/1000.0 for i in range(500,700,2)]
colsample_bytree = [i/1000.0 for i in range(250,350,1)]
min_child_weight = [i/1000.0 for i in range(250,550,3)]
random.shuffle(rank_feature_num)
random.shuffle(random_seed)
random.shuffle(feature_num)
random.shuffle(discret_feature_num)
random.shuffle(gamma)
random.shuffle(max_depth)
random.shuffle(lambd)
random.shuffle(subsample)
random.shuffle(colsample_bytree)
random.shuffle(min_child_weight)
with open('params.pkl','w') as f:
cPickle.dump((random_seed,feature_num,rank_feature_num,discret_feature_num,gamma,max_depth,lambd,subsample,colsample_bytree,min_child_weight),f)
"""
with open('params_for_reproducing.pkl','r') as f:
random_seed,feature_num,rank_feature_num,discret_feature_num,gamma,max_depth,lambd,subsample,colsample_bytree,min_child_weight = cPickle.load(f)
for i in range(36):
print "iter:",i
pipeline(i,random_seed[i],feature_num[i],rank_feature_num[i],discret_feature_num[i],gamma[i],max_depth[i%3],lambd[i],subsample[i],colsample_bytree[i],min_child_weight[i])
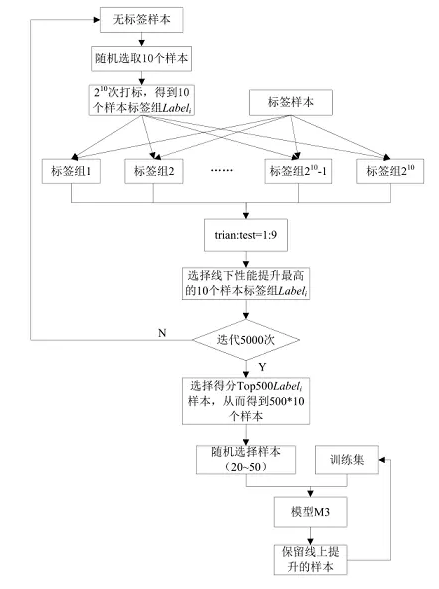
暴力半监督
虽然效率低,但是能有效提高线上得分,充分利用了无标签样本的分布信息来改善分类器性能。虽然效率低,但是能有效提高线上得分,充分利用了无标签样本的分布信息来改善分类器性能。
- 每次从无标签样本中选择,10 个样本,有1024 种打标签方式。使用单模型(多模型融合复杂度太高)训练1024 次并在测试集上测试,选择线下(train:test 为1:9 的比例)性能提升最多的那组标签
- 这里选择10个样本和1:9的划分是因为:如果添加少量样本不能引起模型性能的明显改变,如果11个样本计算时间又成倍增加。所以就选择了一次10个样本(比如10折交叉验证,也不一定非要选10折的,但是经验来说10折靠谱)
- 训练集和测试集1:9划分是因为:少量训练集可以迭代更快,大量测试集可以更好的验证新添加的样本带来的性能
选择样本添加到训练集
select.py
"""
对label.csv里的数据按照bset_auc排序,然后选取top5000个无标签样本(即线下auc提升最大的无标签样本)
每次从这top5000个样本里随机选取50个样本
"""
import pandas as pd
import random,os
labels = pd.read_csv('label.csv',header=None)
labels.columns = ['ind','sample1','sample2','sample3','sample4','sample5','sample6','sample7','sample8','sample9','sample10','auc']
#对auc排序
labels['rk'] = labels.auc.rank(ascending=False)
#选取top5000的样本,注意每组10个样本,top5000即选取rank值小于500的组合
labels = labels[labels.rk<=500]
#每次随机取50个样本,即随机取5组样本
#相当于随机打乱,生成一百份文件
inds = list(labels.ind)
random.shuffle(inds)
os.mkdir('samples_selected')
for i in range(100):
y = ['sample1','sample2','sample3','sample4','sample5','sample6','sample7','sample8','sample9','sample10']
five_inds = inds[(5*i):(5*(i+1))]
five_inds_label = [labels[labels.ind==this_ind][y].values.tolist() for this_ind in five_inds]
five_inds_label_ = []
[five_inds_label_.extend(j[0]) for j in five_inds_label]
temp = [range(ind*10,(ind+1)*10) for ind in five_inds]
uid_index = []
[uid_index.extend(t) for t in temp]
#无标签样本的uid
train_unlabel_uid = pd.read_csv('train_unlabeled.csv')
sample50 = train_unlabel_uid.loc[uid_index]
sample50['y'] = five_inds_label_
sample50[['uid','y']].to_csv('samples_selected/{0}.csv'.format(i),index=None)
给无标签数据打标签
label.py
"""
给无标签数据打标签,每10个样本有1024种标签组合,运行1024次xgboost,选取auc提升最大的组合。
详细:10个无标签样本,有01两种打标方式。所以就是2^10=1024 。具体打标是利用一个位移。比如0位移9次就是000000000,1023位移9次就是1111111111这种
"""
from sklearn.cross_validation import train_test_split
from sklearn import metrics
import pandas as pd
import xgboost as xgb
import sys,random,cPickle
train_xy = pd.read_csv('train_xy.csv')
train,val = train_test_split(train_xy,test_size=0.85,random_state=1024)
val_y = val.y
val_X = val.drop(['y'],axis=1)
dval = xgb.DMatrix(val_X)
train_unlabel = pd.read_csv('train_unlabeled.csv')
def pipeline(unlabel_data):
"""
unlabel_data:
columns=['uid','y',features]
"""
this_train = pd.concat([train,unlabel_data])
y = this_train.y
X = this_train.drop(['y'],axis=1)
dtrain = xgb.DMatrix(X, label=y)
params={
'booster':'gbtree',
'objective': 'rank:pairwise',
'scale_pos_weight': float(len(y)-sum(y))/float(sum(y)),
'eval_metric': 'auc',
'gamma':0.1,
'max_depth':8,
'lambda':600,
'subsample':0.6,
'colsample_bytree':0.3,
'min_child_weight':0.3,
'eta': 0.04,
'seed':1024,
'nthread':20
}
model = xgb.train(params,dtrain,num_boost_round=256,verbose_eval=False)
val_y_pred = model.predict(dval)
fpr,tpr,thresholds = metrics.roc_curve(val_y,val_y_pred,pos_label=1)
return metrics.auc(fpr,tpr)
labels = []
get_bin = lambda x: format(x, 'b').zfill(10)
for i in range(1024):
label_str = get_bin(i)
label = []
for c in label_str:
label.append(int(c))
labels.append(label)
for i in range(5000):
uid_index = range(i*10,(i+1)*10)
samples_selected = train_unlabel.loc[uid_index]
best_auc = 0
best_label = []
for label in labels:
samples_selected['y'] = label
this_auc = pipeline(samples_selected)
print this_auc
if this_auc>best_auc:
best_auc = this_auc
best_label = label
with open('label.csv','a') as f:
f.writelines(str(i)+','+','.join([str(i) for i in best_label])+','+str(best_auc)+'\n')
生成半监督所用的训练数据和无标签数据
gen_samples.py
from sklearn.cross_validation import train_test_split
import pandas as pd
import xgboost as xgb
import sys,random
import cPickle
#离散特征,特征名称与rank特征重了,需要重命名,统一在之前加‘d’
discret_feature_score = pd.read_csv('./discret_feature_score.csv')
fs = list(discret_feature_score.feature[0:500])
discret_train = pd.read_csv("../data/train_x_discretization.csv")
discret_test = pd.read_csv("../data/test_x_discretization.csv")
discret_train_unlabeled = pd.read_csv("../data/train_unlabeled_discretization.csv")
#discret_null feature
test_dnull = pd.read_csv('../data/test_x_null.csv')[['uid','discret_null']]
train_dnull = pd.read_csv('../data/train_x_null.csv')[['uid','discret_null']]
trainunlabeled_dnull = pd.read_csv('../data/train_unlabeled_null.csv')[['uid','discret_null']]
#n_discret feature
test_nd = pd.read_csv('../data/test_x_nd.csv')[['uid','n1','n2','n3','n4','n5','n6','n7','n8','n9','n10']]
train_nd = pd.read_csv('../data/train_x_nd.csv')[['uid','n1','n2','n3','n4','n5','n6','n7','n8','n9','n10']]
trainunlabeled_nd = pd.read_csv('../data/train_unlabeled_nd.csv')[['uid','n1','n2','n3','n4','n5','n6','n7','n8','n9','n10']]
discret_feature = ['n1','n2','n3','n4','n5','n6','n7','n8','n9','n10','discret_null']
test_d = pd.merge(test_nd,test_dnull,on='uid')
train_d = pd.merge(train_nd,train_dnull,on='uid')
trainunlabeled_d = pd.merge(trainunlabeled_nd,trainunlabeled_dnull,on='uid')
del test_dnull,train_dnull,trainunlabeled_dnull
del test_nd,train_nd,trainunlabeled_nd
#rank_feature
rank_feature_score = pd.read_csv('./rank_feature_score.csv')
fs = list(rank_feature_score.feature[0:500])
#load data
rank_train_x = pd.read_csv("../data/train_x_rank.csv")
rank_train = rank_train_x[fs] / float(len(rank_train_x))
rank_train['uid'] = rank_train_x.uid
rank_test_x = pd.read_csv("../data/test_x_rank.csv")
rank_test = rank_test_x[fs] / float(len(rank_test_x))
rank_test['uid'] = rank_test_x.uid
rank_train_unlabeled_x = pd.read_csv("../data/train_unlabeled_rank.csv")
rank_train_unlabeled = rank_train_unlabeled_x[fs] / float(len(rank_train_unlabeled_x))
rank_train_unlabeled['uid'] = rank_train_unlabeled_x.uid
del rank_train_x,rank_test_x,rank_train_unlabeled_x
#raw data
feature_score_717 = pd.read_csv('./raw_feature_score.csv')
fs = list(feature_score_717.feature[0:500])
train_x = pd.read_csv("../data/train_x.csv")[['uid']+fs]
train_y = pd.read_csv("../data/train_y.csv")
train_xy = pd.merge(train_x,train_y,on='uid')
del train_x,train_y
train = pd.merge(train_xy,rank_train,on='uid')
train = pd.merge(train,train_d,on='uid')
train = pd.merge(train,discret_train,on='uid')
test = pd.read_csv("../data/test_x.csv")[['uid']+fs]
test = pd.merge(test,rank_test,on='uid')
test = pd.merge(test,test_d,on='uid')
test = pd.merge(test,discret_test,on='uid')
test_uid = test.uid
train_unlabel = pd.read_csv('../data/train_unlabeled.csv')[['uid']+fs]
tmp1 = pd.merge(train_unlabel,rank_train_unlabeled,on="uid",how="left")
tmp2 = pd.merge(tmp1,trainunlabeled_d,on="uid",how="left")
newdata = pd.merge(tmp2,discret_train_unlabeled,on="uid",how="left")
newdata[newdata<0] = -1
print "select {0} sample from train_unlabel.csv".format(len(newdata))
feature_selected = list(feature_score_717.feature[0:500])
rank_feature_selected = list(rank_feature_score.feature[0:500])
discret_feature_selected = list(discret_feature_score.feature[0:100])
train_xy = train[['uid']+discret_feature+feature_selected+rank_feature_selected+discret_feature_selected+['y']]
train_xy[train_xy<0] = -1
train_xy.to_csv('train_xy.csv',index=None)
n = newdata[['uid']+discret_feature+feature_selected+rank_feature_selected+discret_feature_selected]
n.to_csv('train_unlabeled.csv',index=None)