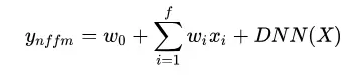Last updated on 2019-10-22…
不久前参加了2018腾讯广告算法大赛,就顺手简单整理了一下学术界推荐系统的发展,以及作为推荐系统主要分支——CTR在工业界的发展。
学术界
学术界经历了“内容过滤->协同过滤->矩阵分解->深度神经网络模型”这样的一个发展历程:
内容过滤
使用关于item(例如产品类别,item内容,评论,价格)和用户(例如年龄,性别,位置)的信息来将用户与item进行匹配。
协同过滤(CF)
使用过去的用户item评级来预测未来的评级。用于执行协同过滤的最流行的技术是通过潜在因子模型,其中物品和用户在共同的潜在空间中被表示,并且评级被计算为用户和物品表示之间的内积。
矩阵分解(MF)
潜在因子模型最流行的实例,并已用于产品,电影和新闻的大规模推荐。传统MF方法的一个重要问题是它们遭受冷启动问题,即它们不能应用于新物品或用户。
为了解决冷启动问题,有相关的工作扩展了MF模型,以便用户和item特定的术语可以包含在它们各自的表示中。这些方法被称为混合方法。
深度学习
考虑到深度神经网络学习图像和文本表示的能力,许多新的混合方法使用了深度神经网络来学习item表示。基于ID嵌入的深度学习模型(与内容嵌入相对)也被用于执行于大规模视频推荐。
之后我会单独列出来一篇《基于深度学习的推荐系统综述的笔记》
工业界
工业界经历了“LR->GBDT等树类模型->FM/FFM等交叉模型->DNN模型”这样的一个发展历程:
LR模型
传统的LR模型相当于单节点的DNN,简单可控。
- 优点在处理离散化特征,其效果的好坏直接取决于特征工程的程度。
- 该模型默认特征与特征之间是独立的,对于一些存在交叉可能性的特征(比如: 衣服类型与性别,这两个特征交叉很有意义),需要进行大量的人工特征工程进行交叉。
GBDT模型
这是一种表达能力比较强的非线性模型。
- 优势在于处理
连续值特征,而且由于树的分裂算法,它具有一定的组合特征的能力,模型的表达能力要比LR强。 - 但是推荐系统的绝大多数场景中,出现的都是大规模离散化特征,如果我们需要使用GBDT的话,则需要将很多特征统计成连续值特征(或者embedding),需要耗费比较多的时间。
- 同时,因为GBDT模型特点,它具有很强的记忆行为,不利于挖掘长尾特征,而且GBDT虽然具备一定的组合特征的能力,但是组合的能力十分有限,远不能与dnn相比。
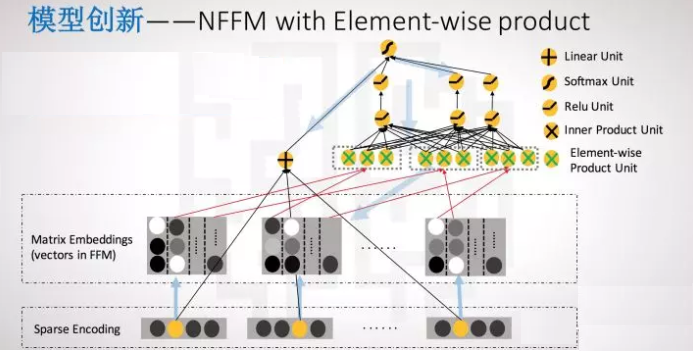
FM和FFM模型
- FM引入了交叉特征,增加了模型的非线性
- FFM把n个特征归属到f个field里,得到nf个隐向量的二次项
DNN模型
该类的模型拥有很强的模型表达能力,而且其结构也是“看上去”天然具有特征交叉的能力。
- 利用基于dnn的模型做推荐问题主要有两个优势:一是模型表达能力强,能够学习出高阶非线性特征;二是容易扩充其他类别的特征,比如在特征拥有图片,文字类特征的时候。
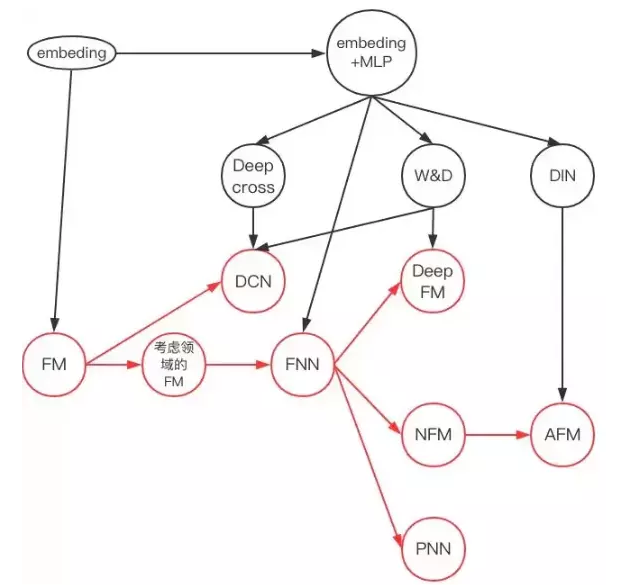
- 陆续出现了大约4种模型:
FNN(FM预训练后与NN串行)、PNN(embedding后FM与乘积层并行输入到NN)、Wide & Deep(FNN与LR并行最后一起sigmoid)、DeepFM(embedding后FM与NN并行)。
DNN模型发展关系图:
模型具体讲解
从LR到NFFM推演
这里,我们定义一下:
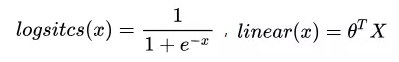
LR:
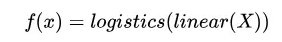
GBDT:
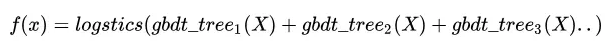
FM:
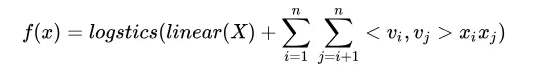
FFM:
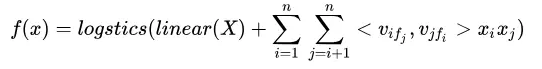
NFFM: