Last updated on 2019-10-4…
字符串常用技巧:
- 查找表:标记字符最新的位置 int table[256]={0}; table[s[i]] = i;
- 标记各单词中字符出现位置 vector<vector
> pos(128) - 滑动窗口 if(i>=l1) c2[s2[i-l1]-‘a’]–; memcmp(c1,c2,sizeof(c1);
- 反转字符串(左闭右开)reverse(s.begin(), s.end())
- 对撞指针int left = 0, right = s.size()-1
- 分词stringstream ss(str); while(getline(ss,word,’ ‘)){}
- 计数unordered_map<char,int>
- 去标点unordered_set
punctuations = {'!','?',',','\',';','.'}
查找问题
用数组作查找表
题目:给定一个字符串,请你找出其中不含有重复字符的 最长子串 的长度。(leetcode 3 无重复最长子串)
- 例如:
- 输入: "abcabcbb"
- 输出: 3
- 解释: 因为无重复字符的最长子串是 "abc",所以其长度为 3。(在遍历完第一个c的时候,子串是"abc",下一个遍历第二个a,结果应该是"bca"。即要把第一个a,以及之前的字符全去掉。)
思路:双指针,用m[s[i]]代表当前字符的上一位置,left代表当前无重复字符串的最左位置。
int lengthOfLongestSubstring(string s) {
int m[256]={0},res=0,left=0,len;
for(int i=0;i<s.size();i++){
len = i-left+1;
if(m[s[i]]==0 || m[s[i]]<left)
res = max(res,len);
else
left=m[s[i]]; //这里相当于取i+1了
m[s[i]]=i+1;
}
return res;
}
滑动窗口
题目:给定两个字符串 s1 和 s2,写一个函数来判断 s2 是否包含 s1 的排列。(leetcode 567 字符串中的全排列)
例如:
- 输入: s1 = "aab" s2 = "eidbaaooo"
- 输出: True
- 解释: s2 包含 s1 的排列之一 ("baa").
思路:无需关注排列的形式,而是关注排列中元素的数量关系,比如aab,那么,转换为数量关系就是{a:2,b:1}, 所以窗口长度定为3
bool checkInclusion(string s1, string s2) {
int l1 = s1.length();
int l2 = s2.length();
int c1[26]={0}, c2[26]={0};
for(char c : s1)
c1[c-'a']++;
for(int i=0;i<l2;i++){
if(i>=l1)
c2[s2[i-l1]-'a']--;
c2[s2[i]-'a']++;
if(memcmp(c1,c2,sizeof(c1))==0)
return true;
}
return false;
}
其中memcmp为内存比较函数,在头文件string.h中,其中最后一个参数是以字节为单位的。
int memcmp(const void *str1, const void *str2, size_t n));
- 如果返回值 < 0,则表示 str1 小于 str2
- 如果返回值 > 0,则表示 str2 小于 str1
- 如果返回值 = 0,则表示 str1 等于 str2
替换问题
题目:以 Unix 风格给出一个文件的绝对路径,你需要简化它。或者换句话说,将其转换为规范路径。(leetcode 71)
输入:"/a//b////c/d//././/.."
输出:"/a/b/c"
利用stringstream分词
class Solution {
public:
string simplifyPath(string path) {
string res, tmp;
stringstream ss(path);
vector<string> v;
while(getline(ss,tmp,'/')){
if(tmp=="" || tmp==".") continue;
if(tmp==".." || !v.empty()) v.pop_back();
else if(tmp!="..") v.push_back(tmp);
}
for(string s : v) res += "/" + s;
return res.empty() ? "/" : res;
}
};
全排列问题
输入一个字符串,按字典序打印出该字符串中字符的所有排列。
例如输入字符串abc,则打印出由字符a,b,c所能排列出来的所有字符串:abc,acb,bac,bca,cab,cba。
不带重复元素的递归方法
分别将每个位置交换到最前面位,之后全排列剩下的位。
//调用示例:string s = "abc"; permutation1(s, 0);
void permutation1(string s, int begin){
if(s.length()-1 == begin) cout<<s<<endl;
else{
for(int i=begin;i<s.length();i++){
swap(s[begin],s[i]);
permutation1(s,begin+1);
}
}
}
带重复元素的递归方法
比上面的方法多个判断前缀是否与当前s[i]重复。
//调用示例:string s = "abc"; permutation2(s, 0);
bool isRepeat(string s,int begin,int end){
for(int i=begin;i<end;i++)
if(s[end]==s[i]) return true;
return false;
}
void permutation2(string s, int begin){
if(s.length()-1 == begin) cout<<s<<endl;
else{
for(int i=begin;i<s.length();i++){
if(!isRepeat(s,begin,i)){
swap(s[begin],s[i]);
permutation2(s,begin+1);
}
}
}
}
不带重复元素的非递归方法
例如:p=839647521是数字1~9的一个排列。下面生成下一个排列的步骤如下:
- 自右至左找出排列中第一个比右边数字小的数字4
- 在该数字后的数字中找出比4大的数中最小的一个5
- 将5与4交换,得到839657421
- 将7421反转,得到839651247。这就是排列p的下一个排列。
归纳为:一找、二找、三交换、四翻转。
- 从尾部往前找第一个s[i]<s[i+1]的数,位置标为fromIndex
- 从fromIndex位置往后找到最后一个大于s[fromIndex]的数,位置标为changeIndex
- 交换位置fromIndex和changeIndex的值
- 倒序fromIndex位置后的所有数据
//调用示例:string s = "abc"; permutation3(s);
void permutation3(string s){
if(s=="") return;
sort(s.begin(),s.end());
int fromIndex, endIndex, changeIndex;
int len = s.length();
while(true){
cout<<s<<endl;
fromIndex = endIndex = len - 1;
while (fromIndex > 0 && s[fromIndex] < s[fromIndex - 1]) --fromIndex;
if (fromIndex == 0) return;
changeIndex = fromIndex;
while (changeIndex + 1 < len && s[changeIndex + 1] > s[fromIndex - 1]) ++changeIndex;
swap(s[fromIndex - 1], s[changeIndex]);
reverse(s.begin()+fromIndex,s.end());
}
}
组合问题
题目:输入一个字符串,输出该字符串中字符的所有组合。举个例子,如果输入abc,它的组合有a、b、c、ab、ac、bc、abc。
使用位运算
思路:一个长度为n的字符串,它的组合有2^n-1中情况,我们用1 ~ 2^n-1的二进制来表示,每种情况下输出当前位等于1的字符。
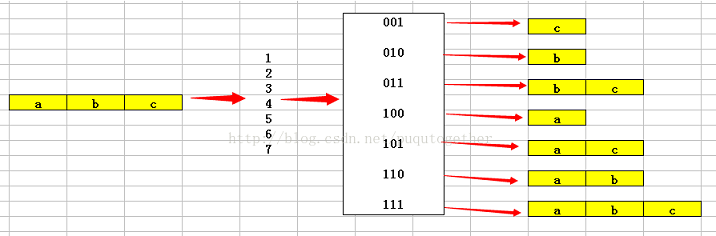
//调用示例;char str[] = "abc"; Combination(str);
void Combination(char *str){
int len=strlen(str);
for(int cur=1; cur < (1<<len); cur++){ //遍历所有的情况,1<<len就等于2^len,遍历1 ~ 2^len-1
for(int j=0; j < len; j++){ //遍历所有的字符
if(cur & (1 << j)) //判断哪一位为1,即输出该位
cout << str[j];
}
cout << endl; //一种情况结束
}
}
划分问题
题目:给定一个只包含数字的字符串,复原它并返回所有可能的 IP 地址格式。(leetcode 93 复原IP地址)
输入: "25525511135"
输出: ["255.255.11.135", "255.255.111.35"]
递归求解
vector<string> restoreIpAddresses(string s) {
vector<string> res;
helper(s, 0, "", res);
return res;
}
void helper(string s, int n, string out, vector<string>& res) {
if (n == 4) {//n代表有几个点
if (s.empty()) res.push_back(out);
} else {
for (int k = 1; k < 4; ++k) {//k代表几位数字
if (s.size() < k) break;
int val = stoi(s.substr(0, k));
if (val > 255 || k != to_string(val).size()) continue;
helper(s.substr(k), n + 1, out + s.substr(0, k) + (n == 3 ? "" : "."), res);
}
}
}
动态规划
最长公共子串(连续)
Longest Common Substring
假设两个字符串分别为x和y,x[i]和y[j]分别表示其第i和第j个字符(字符顺序从0开始),
再令dp[i][j]表示以x[i]和y[j]为结尾的相同子串的最大长度。
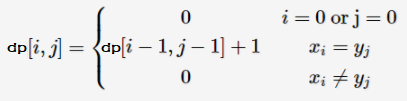
int LCSubstring(string x, string y) {
vector<vector<int> > dp(x.size()+1, vector<int>(y.size()+1, 0));
int max_len = -1;
for (int i=1; i<=x.size(); i++) {
for (int j=1; j<=y.size(); j++) {
if (x[i-1] != y[j-1])
dp[i][j] = 0;
else if (x[i-1] == y[j-1])
dp[i][j] = dp[i-1][j-1] + 1;
if (max_len < dp[i][j])
max_len = dp[i][j];
}
}
return max_len;
}
最长公共子序列(不连续)
Longest Common Sequence
假设两个字符串分别为x和y,x[i]和y[j]分别表示其第i和第j个字符(字符顺序从0开始),
再令dp[i][j]表示以x[i]和y[j]为结尾的相同子序列的最大长度。

int LCSequence(string x, string y) {
vector<vector<int> > dp(x.size()+1, vector<int>(y.size()+1, 0));
for (int i=1; i<=x.size(); i++) {
for (int j=1; j<=y.size(); j++) {
if (x[i] == y[j]) {
dp[i][j] = dp[i-1][j-1] + 1;
}
else {
dp[i][j] = dp[i-1][j] > dp[i][j-1] ? dp[i-1][j] : dp[i][j-1];
}
}
}
return dp[x.size()][y.size()];
}
其他基础技巧
用map统计字符数
string s = "abadc";
unordered_map<char,int> mp;
for(int i=0;i<s.size();i++){
mp[s[i]]++;
}
标记各字符出现位置
第一维是字符对应的ascii数值,第二维是其出现位置的int序列
string s = "abadc";
vector<vector<int>> pos(128);
for (int i = 0; i < s.length(); ++i)
pos[S[i]].push_back(i);
分词
使用stringstream 实现字符串split, 如果有boost库可以直接使用boost的split
string paragraph = "Bob hit a ball, the hit BALL flew far after it was hit."
stringstream ss(paragraph);
string word;
unordered_map<string,int> word_count_map; //各单词出现次数统计
while(getline(ss,word,' '))
word_count_map[word]++;
去除标点符号
string paragraph = "Bob hit a ball, the hit BALL flew far after it was hit."
unordered_set<char> punctuations = {'!','?',',','\'',';','.'};
for (auto it = paragraph.begin(); it != paragraph.end();){
if (punctuations.count(*it))
paragraph.erase(it);
}