Last updated on 2019-11-8…
《细讲Attention Is All You Need》、《Attention is All You Need》浅读(简介+代码)、Self-Attention与Transformer、【NLP】Transformer详解
前言
Attention机制最早是在视觉图像领域提出来的(上世纪90年代),但是真正热门起来是由google mind团队于2014年的论文《Recurrent Models of Visual Attention》,他们在RNN模型上使用了Attention机制来进行图像分类。
随后,Bahdanau等人在论文《Neural Machine Translation by Jointly Learning to Align and Translate》中,使用类似attention的机制在机器翻译任务上将翻译和对齐同时进行,他们的工作算是第一个将Attention机制应用到NLP领域中。
接着Attention机制被广泛应用在基于RNN/CNN等神经网络模型的各种NLP任务中。2017年,google机器翻译团队发表的《Attention is all you need》中大量使用了自注意力(self-attention)机制来学习文本表示。
自注意力机制也成为了大家近期的研究热点,并在各种NLP任务上进行探索。下图展示了Attention研究进展的大概趋势:
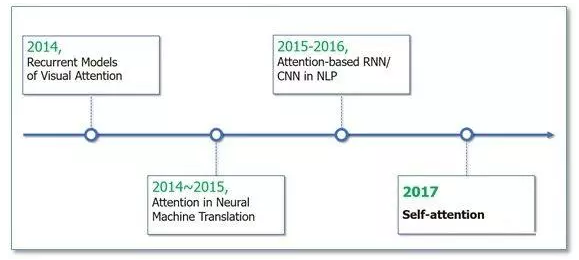
Attention
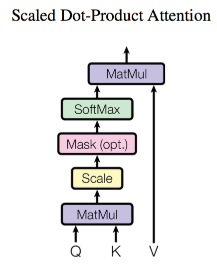
Google 2017年论文《Attention is All you need》中,为Attention做了如下定义:
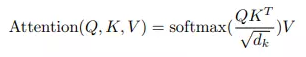
其中Q代表query、K代表key、V代表value,d为缩放因子
计算Attention Weighted Value的流程图:
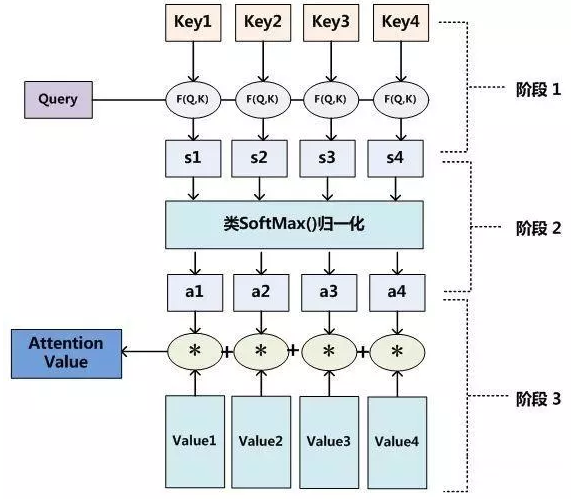
计算Q、K相似度 -> 得分归一化(Attention Weight) -> 根据得分对V进行加权
如果将输入的所有向量合并为矩阵形式(把Q,K,V通过
参数矩阵映射一下),则所有query, key, value向量也可以合并为矩阵形式表示
Multi-Head Attention
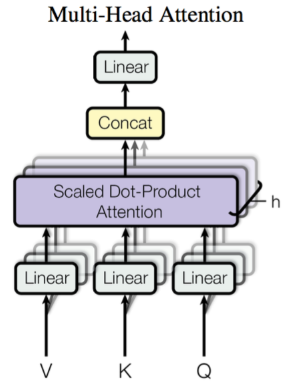
这个是Google提出的新概念,是Attention机制的完善。Multi-Head就是我们可以有不同的Q,K,V表示,最后再将其结果结合起来。
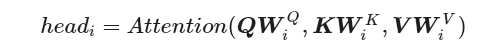
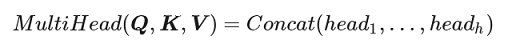
所谓 Multi-Head,就是只多做几次同样的事情(参数不共享),然后把结果拼接。
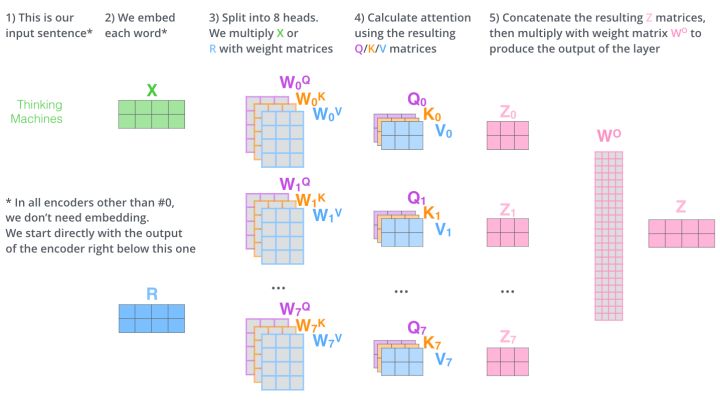
Self Attention
到目前为止,对Attention层的描述都是一般化的,我们可以落实一些应用。 例如,阅读理解场景,Q可以是篇章的向量序列,取K=V为问题的向量序列,那么输出就是所谓的Aligned Question Embedding。
而在Google的论文中,大部分的Attention都是Self Attention,即“自注意力”,或者叫内部注意力。
所谓Self Attention,其实就是Attention(X,X,X),X就是前面说的输入序列。也就是说,在序列内部做Attention,寻找序列内部的联系。
Google论文的主要贡献之一是它表明了内部注意力在机器翻译(甚至是一般的Seq2Seq任务)的序列编码上是相当重要的,而之前关于Seq2Seq的研究基本都只是把注意力机制用在解码端。类似的事情是,目前SQUAD阅读理解的榜首模型R-Net也加入了自注意力机制,这也使得它的模型有所提升。
当然,更准确来说,Google所用的是Self Multi-Head Attention:
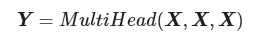
Attention分类
1、按输出:
- soft attention:保留所有分量均做加权,输出注意力分布的概率值
- hard attention:在分布中以某种采样策略选取部分分量,输出onehot向量(强化学习)
2、按关注的范围:
- Globle attention:全局注意力顾名思义对整个feature mapping进行注意力加权
- Local attention:局部注意力有两种,第一种首先通过一个hard-globle-attention锁定位置,在位置上下某个local窗口进行注意力加权
3、按score函数:
- 点 积:Similarity(Query,Keyi) = Query*Keyi
- Cosine相似性:Similarity(Query,Keyi) = Query*Keyi / ||Query|| * ||Keyi||
- M L P 网 络:Similarity(Query,Keyi) = Query*Keyi MLP(Query,Keyi)
Transformer

基本的Multi-head Attention单元,对于encoder来说就是利用这些基本单元叠加,其中key, query, value均来自前一层encoder的输出,即encoder的每个位置都可以注意到之前一层encoder的所有位置。
对于decoder来讲,我们注意到有两个与encoder不同的地方,一个是第一级的Masked Multi-head,另一个是第二级的Multi-Head Attention不仅接受来自前一级的输出,还要接收encoder的输出。
Transformer模型的整体结构如下图所示:
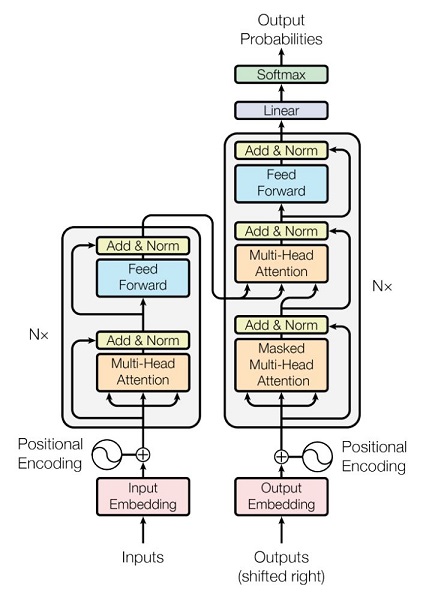
总结一下,k和v的来源总是相同的,q在encoder及第一级decoder中与k,v来源相同,在encoder-decoder attention layer中与k,v来源不同。
Position Embedding
稍微思考一下就会发现,Attention模型并不能捕捉序列的顺序! 换句话说,如果将K,V按行打乱顺序(相当于句子中的词序打乱),那么Attention的结果还是一样的。 这就表明了,到目前为止,Attention模型顶多是一个非常精妙的“词袋模型”而已。
于是Google再祭出了一招:Position Embedding,也就是“位置向量”,将每个位置编号,然后每个编号对应一个向量,通过结合位置向量和词向量,就给每个词都引入了一定的位置信息,这样Attention就可以分辨出不同位置的词了。
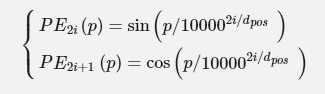
这里的意思是将id为p的位置映射为一个dpos维的位置向量,这个向量的第i个元素的数值就是PEi(p)。Google在论文中说到他们比较过直接训练出来的位置向量和上述公式计算出来的位置向量,效果是接近的。因此显然我们更乐意使用公式构造的Position Embedding了。
Position Embedding本身是一个绝对位置的信息,但在语言中,相对位置也很重要,Google选择前述的位置向量公式的一个重要原因是:由于我们有sin(α+β)=sinαcosβ+cosαsinβ以及cos(α+β)=cosαcosβ−sinαsinβ,这表明位置p+k的向量可以表示成位置p的向量的线性变换,这提供了表达相对位置信息的可能性。
该论文中选取了三角函数的encoding方式,其他方式也可以,该研究组最近还有relation-aware self-attention机制,可参考这篇论文《Self-Attention with Relative Position Representations》。
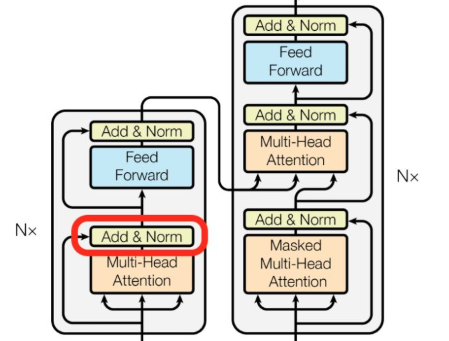
Add代表Residual Connection,是为了解决多层神经网络训练困难的问题,通过将前一层的信息无差地传递到下一层,可以有效的仅关注差异部分,这一方法之前在图像处理结构如ResNet等中常常用到。
Norm代表Layer Normalization,通过对层的激活值的归一化,可以加速模型的训练过程,使其更快的收敛,可参考这篇论文《Layer Normalization》。
结束语
Attention层的好处是能够一步到位捕捉到全局的联系,因为它直接把序列两两比较(代价是计算量变为O(n^2),当然由于是纯矩阵运算,这个计算量相当也不是很严重)。
相比之下,RNN需要一步步递推才能捕捉到,而CNN则需要通过层叠来扩大感受野,这是Attention层的明显优势。