Last updated on 2018-10-1…
1.从整体框架的角度看,当用户每次请求时,系统就会将当前请求的数据写入到日志当中,利用各种数据处理工具对原始日志进行清洗,格式化,落地到不同类型的存储系统中。
2.在训练时,我们利用特征工程,从处理过后的数据集中选出训练、测试样本集,并借此进行线下模型的训练和预估。
3.我们采用多种机器学习算法,并通过线下AUC、NDCG、Precision等指标来评估他们的表现。线下模型经过训练和评估后,如果在测试集有比较明显的提高,会将其上线进行线上AB测试。同时,我们也有多种维度的报表对模型进行数据上的支持。
特征建模
推荐业务作为整个App首页核心模块,对于新颖性以及多样性的需求是很高的。在点评推荐系统的实现中,首先要确定应用场景的数据,美团点评的数据可以分为以下几类:
- 用户画像:性别、常驻地、价格偏好、Item偏好等。
- Item画像:包含了商户、外卖、团单等多种Item。其中商户特征包括:商户价格、商户好评数、商户地理位置等。外卖特征包括:外卖平均价格、外卖配送时间、外卖销量等。团单特征包括:团单适用人数、团单访购率等。
- 场景画像:用户当前所在地、时间、定位附近商圈、基于用户的上下文场景信息等。
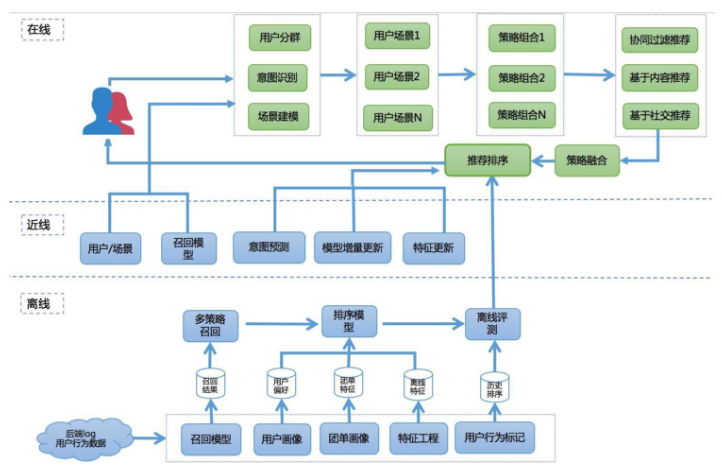
推荐系统
推荐系统的策略主要分为召回和排序两个过程,召回主要负责生成推荐的候选集,排序负责将多个算法策略的结果进行个性化排序。
召回层
我们通过用户行为、场景等进行实时判断,通过多个召回策略召回不同候选集。再对召回的候选集进行融合。
候选集融合和过滤层有两个功能,一是提高推荐策略的覆盖度和精度;另外还要承担一定的过滤职责,从产品、运营的角度制定一些人工规则,过滤掉不符合条件的Item。
下面是一些我们常用到的召回策略:
User-Based 协同过滤
找出与当前User X最相似的N个User,并根据N个User对某Item的打分估计X对该Item的打分。在相似度算法方面,我们采用了Jaccard Similarity。
Model-Based 协同过滤
用一组隐含因子来联系用户和商品。其中每个用户、每个商品都用一个向量来表示,用户u对商品i的评价通过计算这两个向量的内积得到。
算法的关键在于根据已知的用户对商品的行为数据来估计用户和商品的隐因子向量。
Item-Based 协同过滤
我们先用word2vec对每个Item取其隐含空间的向量,然后用Cosine Similarity计算用户u用过的每一个Item与未用过Item i之间的相似性。最后对Top N的结果进行召回。
Query-Based
是根据Query中包含的实时信息(如地理位置信息、WiFi到店、关键词搜索、导航搜索等)对用户的意图进行抽象,从而触发的策略。
Location-Based
移动设备的位置是经常发生变化的,不同的地理位置反映了不同的用户场景,可以在具体的业务中充分利用。
在推荐的候选集召回中,我们也会根据用户的实时地理位置、工作地、居住地等地理位置触发相应的策略。
排序层
每类召回策略都会召回一定的结果,这些结果去重后需要统一做排序。点评推荐排序的框架大致可以分为以下三块。
离线计算层
离线计算层主要包含了算法集合、算法引擎,负责数据的整合、特征的提取、模型的训练、以及线下的评估。
近线实时数据流
主要是对不同的用户流实施订阅、行为预测,并利用各种数据处理工具对原始日志进行清洗,处理成格式化的数据,落地到不同类型的存储系统中,供下游的算法和模型使用。
在线实时打分
根据用户所处的场景,提取出相对应的特征,并利用多种机器学习算法,对多策略召回的结果进行融合和打分重排。