Last updated on 2019-12-20…
以下大部分内容来自哈工大(深圳)的HUA Yang同学,非常感谢!个人仅做了少部分的添加和修改。
过拟合与欠拟合
《深度学习》 5.2 容量、过拟合和欠拟合
- 欠拟合指模型不能在训练集上获得足够低的训练误差;
- 过拟合指模型的训练误差与测试误差(泛化误差)之间差距过大;
- 反映在评价指标上,就是模型在训练集上表现良好,但是在测试集和新数据上表现一般(泛化能力差);
降低过拟合风险的方法
所有为了减少测试误差的策略统称为正则化方法,这些方法可能会以增大训练误差为代价。
- 数据增强
- 图像:平移、旋转、缩放
- 利用生成对抗网络(GAN)生成新数据
- NLP:利用机器翻译生成新数据
- 降低模型复杂度
- 神经网络:减少网络层、神经元个数
- 决策树:降低树的深度、剪枝
- …
- 权值约束(添加正则化项)
- L1 正则化
- L2 正则化
- 集成学习
- 神经网络:Dropout
- 决策树:随机森林、GBDT
- 提前终止
降低欠拟合风险的方法
- 加入新的特征
- 交叉特征、多项式特征、…
- 深度学习:因子分解机、Deep-Crossing、自编码器
- 增加模型复杂度
- 线性模型:添加高次项
- 神经网络:增加网络层数、神经元个数
- 减小正则化项的系数
- 添加正则化项是为了限制模型的学习能力,减小正则化项的系数则可以放宽这个限制
- 模型通常更倾向于更大的权重,更大的权重可以使模型更好的拟合数据
反向传播算法
作用/目的/本质
-
反向传播概述:
梯度下降法中需要利用损失函数对所有参数的梯度来寻找局部最小值点;
而反向传播算法就是用于计算该梯度的具体方法,其本质是利用链式法则对每个参数求偏导。
公式推导
数学/深度学习的核心/反向传播的 4 个基本公式
- 可以用 4 个公式总结反向传播的过程
标量形式:
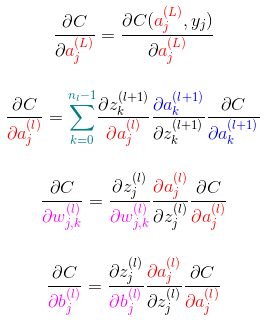
上标
(l)表示网络的层,(L)表示输出层(最后一层);下标j和k指示神经元的位置;w_jk表示l层的第j个神经元与(l-1)层第k个神经元连线上的权重
- 符号说明,其中:
(w,b)为网络参数:权值和偏置z表示上一层激活值的线性组合a即 “activation”,表示每一层的激活值,上标(l)表示所在隐藏层,(L)表示输出层C表示激活函数,其参数为神经网络输出层的激活值a^(L),与样本的标签y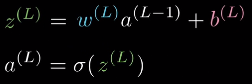
-
以 均方误差(MSE) 损失函数为例,有
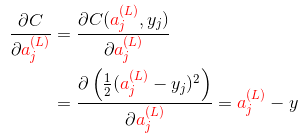
- Nielsen 的课程中提供了另一种更利于计算的表述,本质上是一样的。

激活函数
激活函数的作用
为什么要使用非线性激活函数?
- 使用激活函数的目的是为了向网络中加入非线性因素;加强网络的表示能力,解决线性模型无法解决的问题
为什么加入非线性因素能够加强网络的表示能力?——神经网络的万能近似定理
- 神经网络的万能近似定理认为主要神经网络具有至少一个非线性隐藏层,那么只要给予网络足够数量的隐藏单元,它就可以以任意的精度来近似任何从一个有限维空间到另一个有限维空间的函数。
- 如果不使用非线性激活函数,那么每一层输出都是上层输入的线性组合;
此时无论网络有多少层,其整体也将是线性的,这会导致失去万能近似的性质
《深度学习》 6.4.1 万能近似性质和深度;
- 但仅部分层是纯线性是可以接受的,这有助于减少网络中的参数。
《深度学习》 6.3.3 其他隐藏单元
常见的激活函数
《深度学习》 6.3 隐藏单元
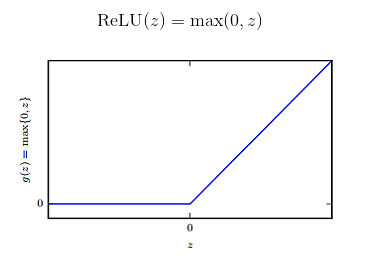
1.整流线性单元 ReLU
- ReLU 通常是激活函数较好的默认选择
2.ReLU 的拓展
ReLU及其扩展都基于以下公式: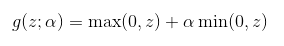
当 α=0 时,即标准的线性整流单元
- 绝对值整流(absolute value rectification):固定
α = -1,此时整流函数即绝对值函数g(z)=|z| - 渗漏整流线性单元(Leaky ReLU, Maas et al., 2013):固定
α为一个小值,比如 0.01 - 参数化整流线性单元(parametric ReLU, PReLU, He et al., 2015):将
α作为一个可学习的参数 maxout单元 (Goodfellow et al., 2013a):maxout单元 进一步扩展了ReLU,它是一个可学习的k段函数
Keras 简单实现
# input shape: [n, input_dim]
# output shape: [n, output_dim]
W = init(shape=[k, input_dim, output_dim])
b = zeros(shape=[k, output_dim])
output = K.max(K.dot(x, W) + b, axis=1)
参数数量是普通全连接层的 k 倍
深度学习(二十三)Maxout网络学习 - CSDN博客
3.sigmoid 与 tanh
sigmoid(z),常记作σ(z);tanh(z)的图像与sigmoid(z)大致相同,区别是值域为(-1, 1)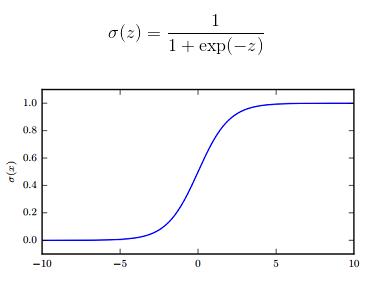
4.其他激活函数
很多未发布的非线性激活函数也能表现的很好,但没有比流行的激活函数表现的更好。比如使用
cos也能在 MNIST 任务上得到小于 1% 的误差。通常新的隐藏单元类型只有在被明确证明能够提供显著改进时才会被发布。
-
线性激活函数: 如果神经网络的每一层都由线性变换组成,那么网络作为一个整体也将是线性的,这会导致失去万能近似的性质。但是,仅部分层是纯线性是可以接受的,这可以帮助减少网络中的参数。
-
softmax: softmax 单元常作为网络的输出层,它很自然地表示了具有 k 个可能值的离散型随机变量的概率分布。
- 径向基函数(radial basis function, RBF):
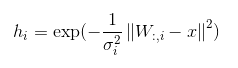
在神经网络中很少使用 RBF 作为激活函数,因为它对大部分 x 都饱和到 0,所以很难优化。
- softplus:
softplus是ReLU的平滑版本。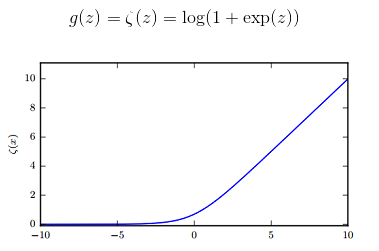
通常不鼓励使用 softplus 函数,大家可能希望它具有优于整流线性单元的性质,但根据经验来看,它并没有。 (Glorot et al., 2011a) 比较了这两者,发现 ReLU 的结果更好。
- 硬双曲正切函数(hard tanh):
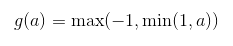
它的形状和 tanh 以及整流线性单元类似,但是不同于后者,它是有界的。
ReLU 相比 sigmoid 的优势 (3)
- 避免梯度消失***
sigmoid函数在输入取绝对值非常大的正值或负值时会出现饱和现象——在图像上表现为变得很平,此时函数会对输入的微小变化不敏感——从而造成梯度消失;ReLU的导数始终是一个常数——负半区为 0,正半区为 1——所以不会发生梯度消失现象
- 减缓过拟合**
ReLU在负半区的输出为 0。一旦神经元的激活值进入负半区,那么该激活值就不会产生梯度/不会被训练,造成了网络的稀疏性——稀疏激活- 这有助于减少参数的相互依赖,缓解过拟合问题的发生
- 加速计算*
ReLU的求导不涉及浮点运算,所以速度更快
为什么 ReLU 不是全程可微/可导也能用于基于梯度的学习?
- 虽然从数学的角度看 ReLU 在 0 点不可导,因为它的左导数和右导数不相等;
- 但是在实现时通常会返回左导数或右导数的其中一个,而不是报告一个导数不存在的错误。从而避免了这个问题
正则化
Batch Normalization(批标准化)
- BN 是一种正则化方法(减少泛化误差),主要作用有:
- 加速网络的训练(缓解梯度消失,支持更大的学习率)
- 防止过拟合
- 降低了参数初始化的要求。
1.动机
- 训练的本质是学习数据分布。如果训练数据与测试数据的分布不同会降低模型的泛化能力。因此,应该在开始训练前对所有输入数据做归一化处理。
- 而在神经网络中,因为每个隐层的参数不同,会使下一层的输入发生变化,从而导致每一批数据的分布也发生改变;致使网络在每次迭代中都需要拟合不同的数据分布,增大了网络的训练难度与过拟合的风险。
2.基本原理
- BN 方法会针对每一批数据,在网络的每一层输入之前增加归一化处理,使输入的均值为
0,标准差为1。目的是将数据限制在统一的分布下。 -
具体来说,针对每层的第
k个神经元,计算这一批数据在第k个神经元的均值与标准差,然后将归一化后的值作为该神经元的激活值。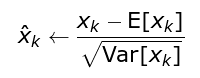
- BN 可以看作在各层之间加入了一个新的计算层,对数据分布进行额外的约束,从而增强模型的泛化能力;
- 但同时 BN 也降低了模型的拟合能力,破坏了之前学到的特征分布;
- 为了恢复数据的原始分布,BN 引入了一个重构变换来还原最优的输入数据分布
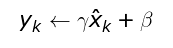 其中
其中 γ和β为可训练参数。
小结
- 以上过程可归纳为一个
BN(x)函数: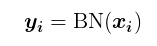
其中
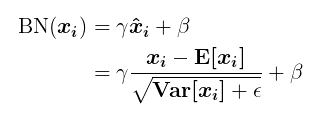
- 完整算法:

3.BN 在训练和测试时分别是怎么做的?
- 训练时每次会传入一批数据,做法如前述;
- 当测试或预测时,每次可能只会传入单个数据,此时模型会使用全局统计量代替批统计量;
- 训练每个 batch 时,都会得到一组
(均值,方差); - 所谓全局统计量,就是对这些均值和方差求其对应的数学期望;
- 具体计算公式为:
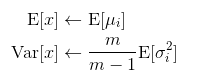
- 其中
μ_i和σ_i分别表示第 i 轮 batch 保存的均值和标准差;m为 batch_size,系数m/(m-1)用于计算无偏方差估计 - 原文称该方法为移动平均(moving averages)
- 其中
- 训练每个 batch 时,都会得到一组
-
此时,
BN(x)调整为: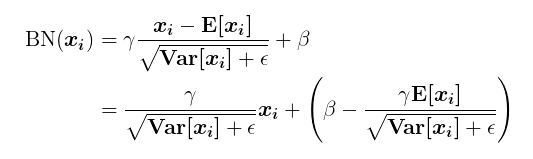
- 完整算法:

4.为什么训练时不采用移动平均?
群里一位同学的面试题
- 使用 BN 的目的就是为了保证每批数据的分布稳定,使用全局统计量反而违背了这个初衷;
- BN 的作者认为在训练时采用移动平均可能会与梯度优化存在冲突;
【原文】”It is natural to ask whether we could simply use the moving averages µ, σ to perform the normalization during training, since this would remove the dependence of the normalized activations on the other example in the minibatch. This, however, has been observed to lead to the model blowing up. As argued in [6], such use of moving averages would cause the gradient optimization and the normalization to counteract each other. For example, the gradient step may increase a bias or scale the convolutional weights, in spite of the fact that the normalization would cancel the effect of these changes on the loss. This would result in unbounded growth of model parameters without actually improving the loss. It is thus crucial to use the minibatch moments, and to backpropagate through them.”
[1702.03275] Batch Renormalization
相关阅读
- 深入理解Batch Normalization批标准化 - 郭耀华 - 博客园
- 深度学习中批归一化的陷阱 - 51CTO
L1/L2 范数正则化
《深度学习》 7.1.1 L2 参数正则化 & 7.1.2 - L1 参数正则化 机器学习中正则化项L1和L2的直观理解 - CSDN博客
作用/异同
相同点
- 限制模型的学习能力——通过限制参数的规模,使模型偏好于权值较小的目标函数,防止过拟合。
不同点
- L1 正则化可以产生更稀疏的权值矩阵,可以用于特征选择,同时一定程度上防止过拟合;L2 正则化主要用于防止模型过拟合
- L1 正则化适用于特征之间有关联的情况;L2 正则化适用于特征之间没有关联的情况。
1.为什么 L1 和 L2 正则化可以防止过拟合?
- L1 & L2 正则化会使模型偏好于更小的权值。
- 更小的权值意味着更低的模型复杂度;添加 L1 & L2 正则化相当于为模型添加了某种先验,限制了参数的分布,从而降低了模型的复杂度。
- 模型的复杂度降低,意味着模型对于噪声与异常点的抗干扰性的能力增强,从而提高模型的泛化能力。——直观来说,就是对训练数据的拟合刚刚好,不会过分拟合训练数据(比如异常点,噪声)——奥卡姆剃刀原理
2.为什么 L1 正则化可以产生稀疏权值,而 L2 不会?
- 对目标函数添加范数正则化,训练时相当于在范数的约束下求目标函数
J的最小值 - 带有L1 范数(左)和L2 范数(右)约束的二维图示
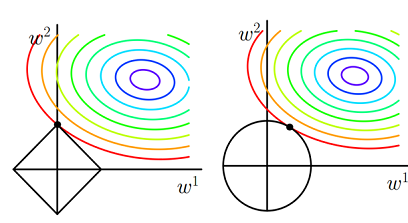
- 图中
J与L1首次相交的点即是最优解。L1在和每个坐标轴相交的地方都会有“顶点”出现,多维的情况下,这些顶点会更多; - 在顶点的位置就会产生稀疏的解。而
J与这些“顶点”相交的机会远大于其他点,因此L1正则化会产生稀疏的解。 L2不会产生“顶点”,因此J与L2相交的点具有稀疏性的概率就会变得非常小。
- 图中
Dropout
《深度学习》 7.12 Dropout
Bagging 集成方法
- 集成方法的主要想法是分别训练不同的模型,然后让所有模型表决最终的输出。
- 集成方法奏效的原因是不同的模型通常不会在测试集上产生相同的误差。
- 集成模型能至少与它的任一成员表现得一样好。如果成员的误差是独立的,集成将显著提升模型的性能。
- Bagging 是一种集成策略——具体来说,Bagging 涉及构造 k 个不同的数据集。
- 每个数据集从原始数据集中重复采样构成,和原始数据集具有相同数量的样例——这意味着,每个数据集以高概率缺少一些来自原始数据集的例子,还包含若干重复的例子
- 更具体的,如果采样所得的训练集与原始数据集大小相同,那所得数据集中大概有原始数据集
2/3的实例
集成方法与神经网络:
- 神经网络能找到足够多的不同的解,意味着他们可以从模型平均中受益——即使所有模型都在同一数据集上训练。
- 神经网络中随机初始化的差异、批训练数据的随机选择、超参数的差异等非确定性实现往往足以使得集成中的不同成员具有部分独立的误差。
Dropout 策略
- 简单来说,Dropout 通过参数共享提供了一种廉价的 Bagging 集成近似—— Dropout 策略相当于集成了包括所有从基础网络除去部分单元后形成的子网络。
- 通常,隐藏层的采样概率为
0.5,输入的采样概率为0.8;超参数也可以采样,但其采样概率一般为1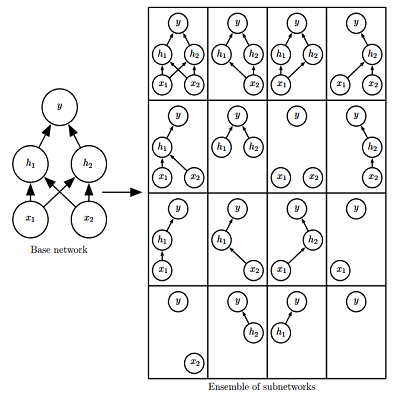
权重比例推断规则:
- 权重比例推断规则的目的是确保在测试时一个单元的期望总输入与在训练时该单元的期望总输入大致相同。
- 实践时,如果使用
0.5的采样概率,权重比例规则相当于在训练结束后将权重乘0.5,然后像平常一样使用模型;等价的,另一种方法是在训练时将单元的状态乘 2。
Dropout 与 Bagging 的不同
- 在 Bagging 的情况下,所有模型都是独立的;而在 Dropout 的情况下,所有模型共享参数,其中每个模型继承父神经网络参数的不同子集。
- 在 Bagging 的情况下,每一个模型都会在其相应训练集上训练到收敛。而在 Dropout 的情况下,通常大部分模型都没有显式地被训练;取而代之的是,在单个步骤中我们训练一小部分的子网络,参数共享会使得剩余的子网络也能有好的参数设定。
Dropout方法一览
- DropConnect:只在连接处扔,神经元不扔 ICML 2013
- Dropout:完全随机扔 JMLR 2014
- SpatialDropout:按channel随机扔 CVPR 2015
- Stochastic Depth:按res block随机扔 ECCV 2016
- Cutout:在input层按spatial块随机扔 CoRR 2017
- DropBlock:每个feature map上按spatial块随机扔 NIPS 2018
深度学习实践
输入标准化
1、为什么要标准化?
-
使训练更快:如果我们的激活函数是sigmoid或者tanh,其梯度最大的区间是0附近,当输入值很大或者很小的时候,sigmoid或者tanh的变化就基本平坦了(sigmoid的导数sig(1-sig)会趋于0),也就是进行梯度下降进行优化的时候,梯度会趋于0,而倒是优化速度很慢。
-
减少陷入局部最佳状态的可能性:理论上对于每一种特征,我们需要使用不同的学习率来保证其方向是往最小值收敛,但是由于梯度下降法只有一个学习率,那么在进行梯度下降的时候,就会收到数值比较大的特征的影响,而偏离最佳的下降路径。
参数初始化
1、为什么要初始化?
假设输出z = w*x+b为远小于-1或者远大于1的数,通过激活函数(比如sigmoid)后所得到的输出会非常接近0或者1,也就是隐藏层神经元处于饱和的状态。 所以当出现这样的情况时,在权重中进行微小的调整仅仅会给隐藏层神经元的激活值带来极其微弱的改变。 而这种微弱的改变也会影响网络中剩下的神经元,然后会带来相应的代价函数的改变。结果就是,这些权重在我们进行梯度下降算法时会学习得非常缓慢。
因此,我们可以通过改变权重w的分布,使|z|尽量接近于0。这就是我们为什么需要进行权重初始化的原因了。
2、一般怎么初始化?
- 一般使用服从的高斯分布(
mean=0, stddev=1)或均匀分布的随机值作为权重的初始化参数;使用0作为偏置的初始化参数 - 一些启发式方法会根据输入与输出的单元数来决定初始值的范围
比如 glorot_uniform 方法 (Glorot and Bengio, 2010)

Keras 全连接层默认的权重初始化方法
- 其他初始化方法
- 随机正交矩阵(Orthogonal)
- 截断高斯分布(Truncated normal distribution)
- Keras 提供的参数初始化方法:Keras/Initializers
调优trick总结
1、优化器
机器学习训练的目的在于更新参数,优化目标函数,常见优化器有SGD,Adagrad,Adadelta,Adam,Adamax,Nadam。其中SGD和Adam优化器是最为常用的两种优化器,SGD根据每个batch的数据计算一次局部的估计,最小化代价函数。
学习速率决定了每次步进的大小,因此我们需要选择一个合适的学习速率进行调优。学习速率太大会导致不收敛,速率太小收敛速度慢。因此SGD通常训练时间更长,但是在好的初始化和学习率调度方案的情况下,结果更可靠。
Adam优化器结合了Adagrad善于处理稀疏梯度和RMSprop善于处理非平稳目标的优点,能够自动调整学习速率,收敛速度更快,在复杂网络中表现更优。
2、学习速率
学习速率的设置第一次可以设置大一点的学习率加快收敛,后续慢慢调整;也可以采用动态变化学习速率的方式(比如,每一轮乘以一个衰减系数或者根据损失的变化动态调整学习速率)。
3、dropout
数据第一次跑模型的时候可以不加dropout,后期调优的时候dropout用于防止过拟合有比较明显的效果,特别是数据量相对较小的时候。
4、变量初始化
常见的变量初始化有零值初始化、随机初始化、均匀分布初始值、正态分布初始值和正交分布初始值。一般采用正态分布或均匀分布的初始化值,有的论文说正交分布的初始值能带来更好的效果。实验的时候可以才正态分布和正交分布初始值做一个尝试。
5、训练轮数
模型收敛即可停止迭代,一般可采用验证集作为停止迭代的条件。如果连续几轮模型损失都没有相应减少,则停止迭代。
6、正则化
为了防止过拟合,可通过加入l1、l2正则化。从公式可以看出,加入l1正则化的目的是为了加强权值的稀疏性,让更多值接近于零。而l2正则化则是为了减小每次权重的调整幅度,避免模型训练过程中出现较大抖动。
7、预训练
对需要训练的语料进行预训练可以加快训练速度,并且对于模型最终的效果会有少量的提升,常用的预训练工具有word2vec和glove。
8、激活函数

常用的激活函数为sigmoid、tanh、relu、leaky relu、elu。采用sigmoid激活函数计算量较大,而且sigmoid饱和区变换缓慢,求导趋近于0,导致梯度消失。sigmoid函数的输出值恒大于0,这会导致模型训练的收敛速度变慢。
tanh它解决了zero-centered的输出问题,然而,gradient vanishing的问题和幂运算的问题仍然存在。
relu从公式上可以看出,解决了gradient vanishing问题并且计算简单更容易优化,但是某些神经元可能永远不会被激活,导致相应的参数永远不能被更新(Dead ReLU Problem);leaky relu有relu的所有优点,外加不会有Dead ReLU问题,但是在实际操作当中,并没有完全证明leaky relu总是好于relu。
elu也是为解决relu存在的问题而提出,elu有relu的基本所有优点,但计算量稍大,并且没有完全证明elu总是好于relu。
9、特征学习函数
常用的特征学习函数有cnn、rnn、lstm、gru。cnn注重词位置上的特征,而具有时序关系的词采用rnn、lstm、gru抽取特征会更有效。gru是简化版的lstm,具有更少的参数,训练速度更快。但是对于足够的训练数据,为了追求更好的性能可以采用lstm模型。
10、特征抽取
max-pooling、avg-pooling是深度学习中最常用的特征抽取方式。max-pooling是抽取最大的信息向量,然而当存在多个有用的信息向量时,这样的操作会丢失大量有用的信息。
avg-pooling是对所有信息向量求平均,当仅仅部分向量相关而大部分向量无关时,会导致有用信息向量被噪声淹没。针对这样的情况,在有多个有用向量的情形下尽量在最终的代表向量中保留这些有用的向量信息,又想在只有一个显著相关向量的情形下直接提取该向量做代表向量,避免其被噪声淹没。那么解决方案只有:加权平均,即Attention。
11、每轮训练数据乱序
每轮数据迭代保持不同的顺序,避免模型每轮都对相同的数据进行计算。
12、batch_size选择
对于小数据量的模型,可以全量训练,这样能更准确的朝着极值所在的方向更新。但是对于大数据,全量训练将会导致内存溢出,因此需要选择一个较小的batch_size。
如果这时选择batch_size为1,则此时为在线学习,每次修正方向为各自样本的梯度方向修正,难以达到收敛。batch_size增大,处理相同数据量的时间减少,但是达到相同精度的轮数增多。实际中可以逐步增大batch_size,随着batch_size增大,模型达到收敛,并且训练时间最为合适