Last updated on 2018-10-20…
原文来自《美团机器学习实践》,Target:海量数据下的机器学习应用场景
并行计算编程技术
- CPU单核:通过
向量化技术来提升单核的处理能力 - CPU多核:通过
多线程技术来充分利用多核处理能力 - GPU:通过
异构计算来扩充单机的处理能力 - 多机并行:把多机串联起来组成计算集群
向量化
费林分类法:
| 单一指令流 | 多指令流 | |
|---|---|---|
| 单一数据流 | 单指令流单数据流(SISD) | 多指令流单数据流(MISD) |
| 多数据流 | 单指令流多数据流(SIMD) | 多指令流多数据流MIMD) |
单指令流多数据流(Single Instruction Multiple Data,SIMD)是一种采用一个控制器来控制多个处理器,同时对一组数据(又称“数据向量”)中的每一个分别执行相同的操作从而实现空间上的并行性的技术。
- 在微处理器中,单指令流多数据流技术则是一个控制器控制多个平行的处理微元,例如Intel的MMX或SSE,以及AMD的3D Now!指令集。
- 图形处理器(GPU)拥有强大的并发处理能力和可编程流水线,面对单指令流多数据流时,运算能力远超传统CPU。OpenCL和CUDA分别是目前最广泛使用的开源和专利通用图形处理器(GPGPU)运算语言。
在X86架构的CPU上:(PC端)
- SSE指令集(Streaming SIMD Extensions, 单指令多数据流式扩展):16个128位的寄存器,每一个寄存器可存放4个(32位)单精度浮点数,这些数就可以在寄存器中进行算术逻辑运算,然后把结果放回内存
- AVX指令集(Advanced Vector Extensions,高级向量扩展):扩充为256位,从而支持256位的矢量计算,理论上性能提升1倍
在ARM架构的CPU上:(移动端)
- Neon指令集:16个128位的寄存器
在理想状况下,SSE指令集的加速比位4倍,AVX是8倍。不过实际过程中,由于加载数据到寄存器有时间消耗,加速比略低于这个理论值
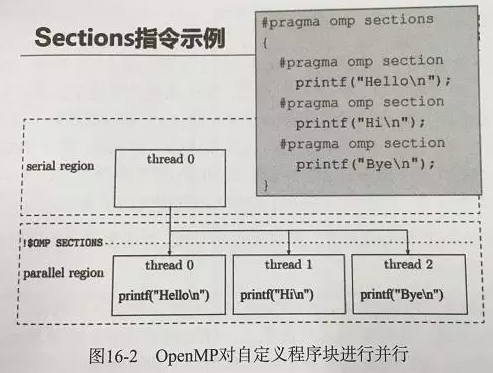
多核并行 OpenMP
很多OS跟编程语言都提供了多线程编程库,如UNIX/Linux的Pthread、Windows的WinThread,并行起来就会遇到同步互斥问题和移植性问题。
OpenMP,一个支持共享存储并行设计的库。
GPU 编程
事实证明,在浮点计算、并行计算等部分计算方面,GPU性能数十倍甚至上百倍于CPU。
目前主流的GPU计算方案CUDA是NVIDIA提供的。
在利用CUDA进行编程时,一个网格分为多个线程块,一个线程块分为多个线程。任务划分会影响最后的执行效果。
import numpy
from pycublas import CUBLASMatrix
A = CUBLASMatrix(numpy.mat([[1,2,3],[4,5,6]],numpy.float32))
B = CUBLASMatrix(numpy.mat([[2,3],[4,5],[6,7]],numpy.float32))
C = A*B
print C.np_mat()
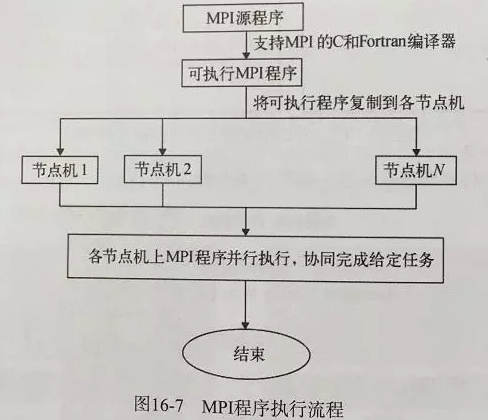
多机并行MPI
消息传递接口MPI(Massage Passing Interface)
小结
向量化和OpenMP:在单机执行机器学习训练的情况下,主要采用该技术进行加速,使用该技术的常用开源机器学习包有XGBoost、Multi-core Liblinear、Libffm和FANN
GPU编程(CUDA):几乎所有的深度学习包都会使用该技术,比如Theano、MXNet、Tensorflow和Caffe
MPI:大公司基本都会开发自己的消息通信系统,其功能上与MPI大同小异,Graphlab、Distributed MPI LIBLINEAR、Paracel都是采用MPI的代表
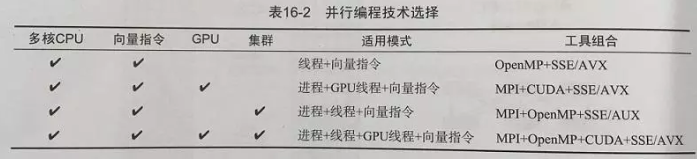
并行计算模型
常见分布式系统:
- 通用分布式任务处理方案:
Hadoop(批处理)、Spark(基于内存) - 实时流处理系统:
Storm - 面向分布式数据流处理和批处理的开源计算平台:
Flink - 专为分布式深度学习任务设计的:
TensorFlow、MXNet、PaddlePaddle等
常见的并行计算模型:
- BSP模型:切分好的并行任务同时计算(线程或者进程),计算完之后统一进行通信,对各自的计算结果进行同步(此时容易木桶效应),然后再开始新一轮的计算和同步。
- SSP模型:通过设置一个Bound来确定同步的时机。当最快的Worker比最慢的Worker超过这个Bound时,所有的Worker就进行一次参数的同步。
- ASP模型:Worker之间不再有同步操作
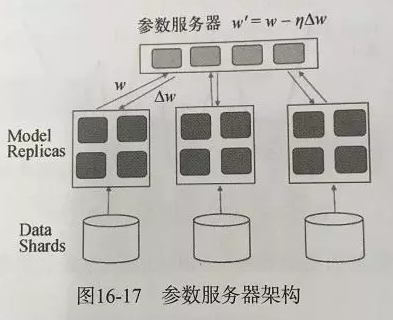
- 参数服务器:见下图