Last updated on 2018-12-07…
早期的强化学习算法主要关注于状态和动作都是离散且有限的问题,可以使用表格来记录这些概率。但在很多实际问题中,有些任务的状态和动作的数量非常多,还有些任务的状态和动作是连续的。
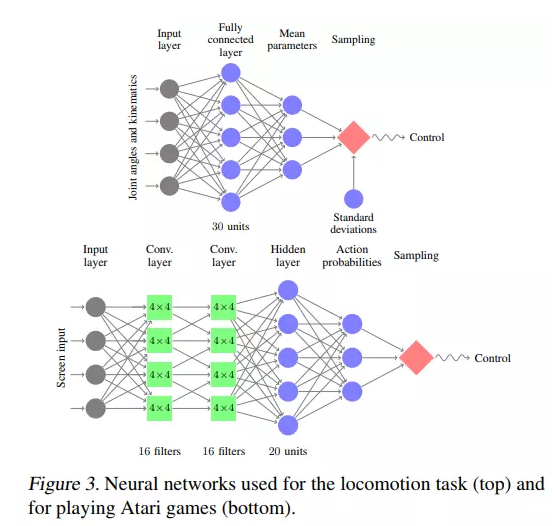
相比于RL,DRL通常利用卷积层中隐藏神经元来探测到各式各样的state(取决于卷积层的权重分配),由全连接层的权重分配决定action。
用强化学习来定义问题和优化目标,用深度学习来解决策略和值函数的建模问题,然后使用误差反向传播算法来优化目标函数。
但是,前不久Deepmind团队的软件工程师之一 Alex Irpan 发文《Deep Reinforcement Learning Doesn’t Work Yet》,一上来就指出DRL是个大坑。它的成功案例其实很少,但每个都太有名了(变相吹捧?!)。
文末我将Alex的看法做了一些归纳。
本文综述方面的内容绝大部分来自于这篇文章。
Alex介绍:他从伯克利拿到的计算机科学本科学位,本科时候曾经在伯克利人工智能实验室(Berkeley AI Research (BAIR) Lab)进行本科科研,导师是 DRL 大牛 Pieter Abbeel。
下面点击相应的标题即可阅读相应的完整论文
引言
DL 的基本思想是通过多层的网络结构和非线性变换,组合低层特征,形成抽象的、易于区分的高层表示,以发现数据的分布式特征表示。因此 DL 方法侧重于对事物的感知和表达。
RL 的基本思想是通过最大化智能体(agent)从环境中获得的累计奖赏值,以学习到完成目标的最优策略。因此 RL 方法更加侧重于学习解决问题的策略。
随着人类社会的飞速发展,在越来越多复杂的现实场景任务中,需要利用 DL 来自动学习大规模输入数据的抽象表征,并以此表征为依据进行自我激励的 RL,优化解决问题的策略。
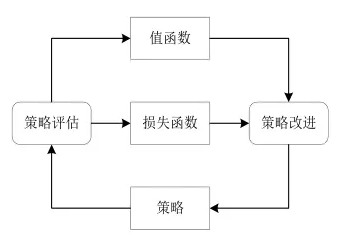
其学习过程可以描述为:
-
在每个时刻 agent与环境交互得到一个高维度的观察,并利用 DL 方法来感知观察,以得到抽象、具体的状态特征表示;
-
基于预期回报来评价各动作的价值函数,并通过某种策略将当前状态映射为相应的动作。
-
环境对此动作做出反应,并得到下一个观察。通过不断循环以上过程,最终可以得到实现目标的最优策略。
DRL原理框架如图 1 所示:
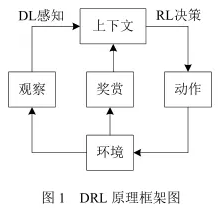
目前 DRL 技术在游戏、机器人控制、参数优化、机器视觉等领域中得到了广泛的应用,并被认为是迈向通用人工智能(ArtificialGeneral Intelligence,AGI)的重要途径。
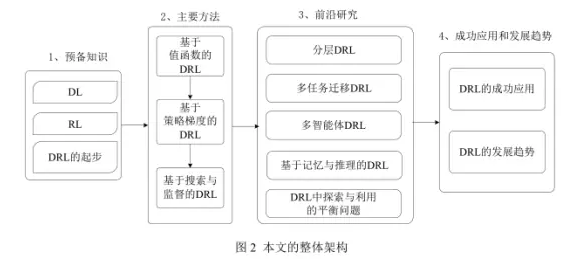
本文对 DRL的研究历程和发展现状进行了详细的阐述。整体架构如图 2 所示:
基于值函数的DRL
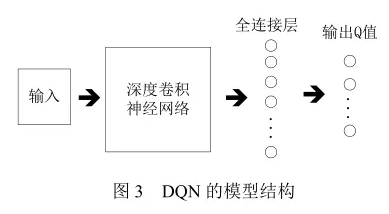
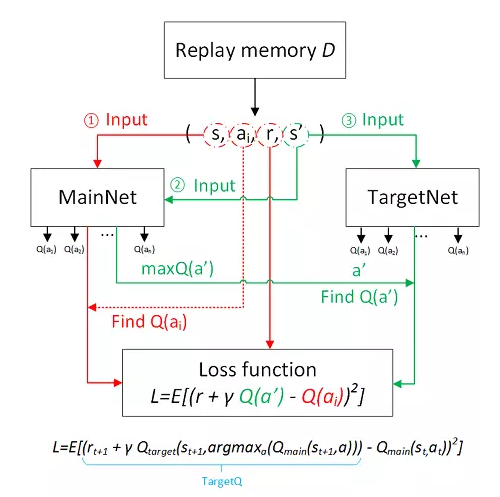
深度Q网络(DQN)
Deep Q-Network模型用于处理基于视觉感知的控制任务,是 DRL 领域的开创性工作。
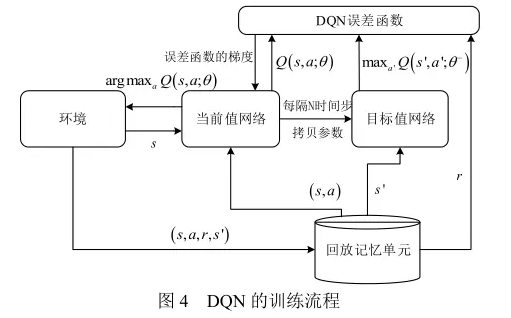
- 在训练过程中使用
经验回放机制(experience replay),在线处理得到的转移样本。 - 除了使用深度卷积网络近似表示当前的值函数之外,还单独使用了另一个网络来产生
目标 Q 值。当前值网络的参数 θ 是实时更新的,每经过 N 轮迭代,将当前值网络的参数复制给目标值网络。通过最小化当前 Q 值和目标 Q 值之间的均方误差来更新网络参数。引入目标值网络后,在一段时间内目标 Q 值是保持不变的,一定程度上降低了当前 Q 值和目标 Q 值之间的相关性,提升了算法的稳定性。 - 将奖赏值和误差项缩小到有限的区间内,保证了 Q 值和梯度值都处于合理的范围内,提高了算法的稳定性。
深度双Q网络(DDQN)
Deep Double Q-Network的作者发现并证明了传统的DQN普遍会过高估计Action的Q值,而且估计误差会随Action的个数增加而增加。如果高估不是均匀的,则会导致某个次优的Action高估的Q值超过了最优Action的Q值,永远无法找到最优的策略。
- 在双Q学习中有两套不同的参数: θ 和 θ-。其中 θ 用来选择对应最大 Q 值的动作,θ- 用来评估最优动作的 Q 值。两套参数将动作选择和策略评估分离开,降低了过高估计 Q 值的风险。
- DDQN使用当前值网络的参数来选择最优动作,使用目标值网络的参数θ- 来评估该最优动作。
- DDQN 在其他方面都与 DQN 保持一致。实验表明,DDQN 能够估计出更加准确的Q 值。
基于优势学习的深度Q网络
降低 Q 值的评估误差可以提升性能。Bellemare 等人在贝尔曼方程中定义新的操作符,来增大最优动作值和次优动作值之间的差异,以缓和每次都选取下一状态中最大 Q 值对应动作所带来的评估误差。
- 根据
优势学习(Advantage Learning,AL)定义两种新的操作符,用AL和PAL误差项来替代贝尔曼方程中的误差项,可以有效地增加最优和次优动作对应值函数之间的差异,从而获得更加精确的 Q值。 - 优势学习相当于一个回归任务,每一步目标是最小化与Rt的距离,整体来看就是之前策略累计奖励的动态平均。
基于优先级采样的深度Q网络
在每个时刻,经验回放机制从样本池中等概率地抽取小批量的样本用于训练.然而等概率采样并不能区分不同样本的重要性。
- 该抽样方法将每个样本的时间差分(Temporal Difference, TD)误差项作为评价优先级的标准。其绝对值越大,对应样本被采样的概率越高。
- 在抽样过程中该方法使用随机比例化(stochastic prioritization)和重要性采样权重(importance-sampling weights)两种技巧。
- 随机比例化操作不仅能充分利用较大 TD 误差项对应的样本,而且保证了抽取样本的多样性。
- 重要性采样权重的使用放缓了参数更新的速度,保证了学习的稳定性。
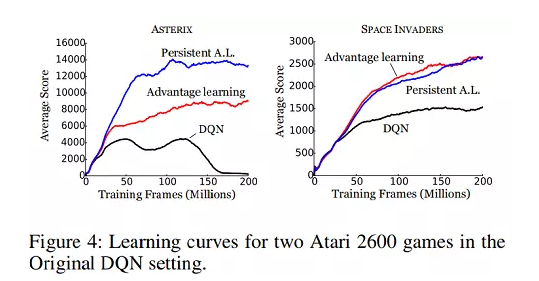
- 实验表明,基于该抽样方式的深度双Q 网络可以提升训练速度,并在很多 Atari 2600 游戏中获得了更高的分数。
^以上是基于训练算法的改进
基于竞争架构的DQN
DQN 将 CNN 提取的抽象特征经过全连接层后,直接在输出层输出对应动作的 Q 值,而引入竞争网络结构的模型则将 CNN 提取的抽象特征分流到两个支路中,其中一路代表状态值函数,另一路代表依赖状态的动作优势函数(advantage function)。即用竞争网络替代了之前的全连接层。
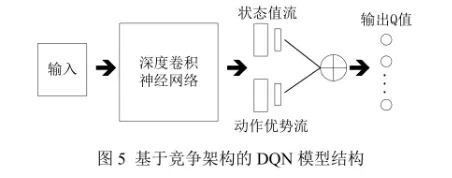
- 通过该种竞争网络结构,agent 可以在策略评估过程中更快地识别出正确的行为。
- 实际操作中,一般要将动作优势流设置为单独动作优势函数值减去某状态下所有动作优势函数的平均值。该技巧不仅可以保证该状态下各动作的优势函数相对排序不变,而且可以缩小 Q 值的范围,去除多余的自由度。
深度循环Q网络
在传统的 RL 方法中,状态信息的部分可观察性一直是个亟待解决的难题。
DQN 通过堆叠离当前时刻最近的 4 幅历史图像组成输入状态,有效缓解了状态信息的部分可观察问题,却增加了网络的计算和存储负担。
Hausknecht 等人利用循环神经网络结构来记忆时间轴上连续的历史状态信息,提出了DRQN 模型。
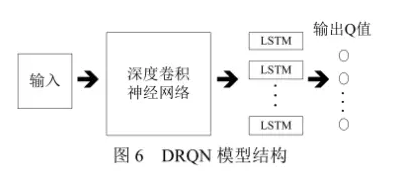
- DRQN 将 DQN 中第 1 个
全连接层的部件替换成了 256 个长短期记忆单元(Long Short-Term Memory,LSTM)。此时模型的输入仅为当前时刻的一幅图像,减少了深度网络感知图像特征所耗费的计算资源 - 此时模型的输入仅为当前时刻的一幅图像,减少了深度网络感知图像特征所耗费的计算资源.
^以上是基于网络结构的改进
基于策略梯度的DRL
策略梯度是一种常用的策略优化方法,它通过不断计算策略期望总奖赏关于策略参数的梯度来更新策略参数,最终收敛于最优策略。 因此在解决 DRL 问题时,可以采用参数为的深度神经网络来进行参数化表示策略,并利用策略梯度方法来优化策略。
在求解 DRL 问题时,往往第一选择是采取基于策略梯度的算法。原因是它能够直接优化策略的期望总奖赏,并以端对端的方式直接在策略空间中搜索最优策略,省去了繁琐的中间环节。 因此与 DQN 及其改进模型相比,基于策略梯度的 DRL 方法适用范围更广,策略优化的效果也更好。
假设一个完整情节的状态、动作和奖赏的轨迹为:
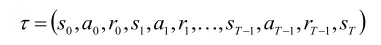 则策略梯度表示为如下的形式:
则策略梯度表示为如下的形式:
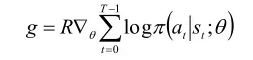
区域信赖的策略最优化(TRPO)
通过各种策略梯度方法直接优化用深度神经网络参数化表示的策略
Trust Region Policy Optimization的核心思想是:
强制限制同一批次数据上新旧两种策略预测分布的KL 差异,从而避免导致策略发生太大改变的参数更新步。- 为了将应用范围扩展到大规模状态空间的 DRL 任务中,TRPO 算法使用深度神经网络来参数化策略,在只接收原始输入图像的情况下实现了端对端的控制。
基于行动者评论家
TRPO这类方法在每个迭代步,都需要采样批量大小为 N 的轨迹来更新策略梯度。然而在许多复杂的现实场景中,很难在线获得大量训练数据。
Lillicrap 等人利用 DQN 扩展 Q 学习算法的思路对确定性策略梯度(Deterministic Policy Gradient,DPG)方法进行改造,提出了一种基于 AC 框架的深度确定性策略梯度(Deep Deterministic Policy Gradient,DDPG)算法。
- 该算法可用于解决连续动作空间上的 DRL 问题.DDPG分别使用参数为和的深度神经网络来表示确定性策略和值函数。
- 其中,
策略网络用来更新策略,对应 AC 框架中的行动者;值网络用来逼近状态动作对的值函数,并提供梯度信息,对应 AC 框架中的评论家。
实验表明,DDPG 不仅在一系列连续动作空间的任务中表现稳定,而且求得最优解所需要的时间步也远远少于 DQN。与基于值函数的 DRL 方法相比,基于 AC 框架的深度策略梯度方法优化策略效率更高、求解速度更快。
异步的优势行动者评论家算法(A3C)
经验回放机制存在两个不足之处:
- agent 与环境的每次实时交互都需要耗费很多的内存和计算力
- 经验回放机制要求 agent 采用离策略(off-policy)方法来进行学习,而离策略方法只能基于旧策略生成的数据进行更新

异步的优势行动者评论家算法(Asynchronous Advantage Actor-Critic,A3C)在各类连续动作空间的控制任务上表现的最好。
- A3C 算法
利用 CPU 多线程的功能并行、异步地执行多个 agent。 - 因此在任意时刻,并行的 agent 都将会经历许多不同的状态,去除了训练过程中产生的状态转移样本之间的关联性,因此这种低消耗的异步执行方式可以很好地替代经验回放机制。
基于搜索与监督的DRL
除了基于值函数的 DRL 和基于策略梯度的DRL 之外,还可以通过增加额外的人工监督来促进策略搜索的过程,即为基于搜索与监督的 DRL 的核心思想。
蒙特卡洛树搜索(Monte Carlo Tree Search,MCTS)作为一种经典的启发式策略搜索方法,被广泛用于游戏博弈问题(AlphaGO)中的行动规划。
在基于搜索与监督的 DRL 方法中,策略搜索一般是通过 MCTS 来完成的。
在 AI 领域中,由于围棋存在状态空间巨大且精确评估棋盘布局、走子困难等原因,开发出一个能够精通围棋游戏的 agent,一直被认为是最有挑战性的难题.直到 Silver 等人将 CNN 与 MCTS 相结合,提出了一种被称作为 AlphaGo 的围棋算法,在一定程度上解决了这一难题.AlphaGo 的主要思想有两点:
- 使用 MCTS 来近似估计每个状态的值函数
- 使用基于值函数的 CNN 来评估棋盘的当前布局和走子.AlphaGo 完整的学习系统主要由以下 4 个部分组成:
- 策略网络(policy network).又分为监督学习的策略网络和 RL 的策略网络.策略网络的作用是根据当前的局面来预测和采样下一步走棋
- 滚轮策略(rollout policy).目标也是预测下一步走子,但是预测的速度是策略网络的 1000倍
- 估值网络(value network).根据当前局面,估计双方获胜的概率
- MCTS将策略网络、滚轮策略和估值网络融合进策略搜索的过程中,以形成一个完整的系统
分层DRL(HRL)
在一些复杂的 DRL 任务中,直接以最终目标为导向来优化策略,效率很低。 因此可以利用分层强化学习(Hierarchical Reinforcement Learning,HRL)将最终目标分解为多个子任务来学习层次化的策略,并通过组合多个子任务的策略形成有效的全局策略。
本章将主要介绍 3 种具有代表性的分层 DRL 算法。
基于时空抽象和内在激励的HRL (h-DQN)
在一些复杂的目标导向型任务中,稀疏反馈的问题一直阻碍着 agent 性能的提升。现有的各种DRL 模型(DQN、DRQN 等)在面对操作难度很大的 Montezuma’s Revenge 游戏时,并不能表现出任何的智能行为。
由于在学习过程中,agent得到的反馈信号极少,导致其对某些重要状态空间的探索很不充分。若要在此类复杂的环境中进行有效的学习,agent 必须感知出层次化时空抽象(temporal abstraction)的知识表达,并在此基础上通过某些内在激励来促进其探索。
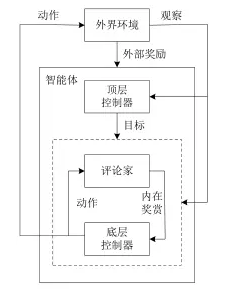
层次化的 DQN 算法(hierarchical Deep Q-Network,h-DQN)
- h-DQN是一种基于时空抽象和内在激励的分层 DRL算法,通过在不同的时空尺度上设置子目标来层次化值函数。
- 顶层的值函数用于确定 agent 的决策,以得到下一个内在激励的子目标,而底层的值函数用于确定 agent 的行动,以满足顶层的子目标。
基于内部Option的深度Q学习
deep intra-option Q-learning模型:
- 该模型结合时空抽象和深度神经网络,自动地完成子目标的学习,同时可以在给定抽象状态和扩展动作集的前提下获得当前任务的一个层次化描述。
- 该分层 DRL 方法省去了特定的内在激励和人工设定中间目标这两个环节,加速了agent 的学习进程,并增强了模型在其他任务上的泛化能力。
- 受动力学系统启发,模型利用一种被称作PCCA+的聚类算法。该算法可以在状态空间中寻求亚稳定的区域并将其与抽象状态相关联。
- 生成的 Option 相当于 h-DQN 模型中设定的中间目标,省去了复杂的人工设定中间目标的过程,并使得学习到的 Option 与具体的学习任务无关。
深度后续强化学习
后续状态表示法(Successor Representation,SR)为学习值函数提供了第 3 种选择.
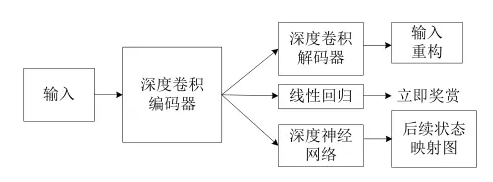
SR 将值函数分解为两个部分:后续状态映射图(successor map)和立即奖赏指示器(reward predictor):
- 后续状态映射图表示在给定当前状态下到达未来某一状态占有率的期望。
- 立即奖赏指示器表示从状态到奖赏值的映射.在 SR 中,这两个部分以内积的形式构成值函数。
多任务迁移DRL
在传统 DRL 方法中,每个训练完成后的 agent只能解决单一任务。然而在一些复杂的现实场景中,需要 agent 能够同时处理多个任务,此时多任务学习和迁移学习就显得异常重要。
基于行为模拟
Parisotto 等人提出了一种基于行为模拟(actor-mimic)的多任务迁移 DRL 方法:
- 它可以基于一组相关的源任务预训练一个深度策略网络。
- 该方法的基本思想是通过
监督信号的指导,使得单一的策略网络学会各自任务相对应的策略,并将学习到的知识迁移到相似的新任务中。
基于策略蒸馏
Rusa 等人提出一种新颖的多任务迁移 DRL方法,称作策略蒸馏(policy distillation)。该方法根据学习网络和指导网络 Q 值的偏差来确定 Q 值回归目标函数,引导学习网络逼近指导网络的值函数空间。
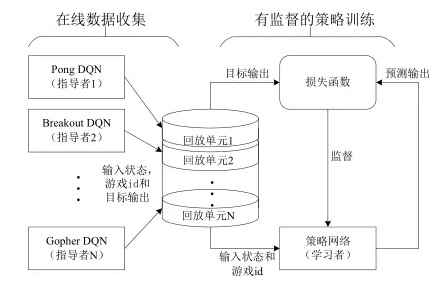
- 首先,使用多个训练完成的单任务 DQN 模型来产生输入状态、任务 id 和目标输出,并将其存储到各自的回放单元中。
- 其中,任务 id 用来标识不同任务的指导模型。不同任务有着不同的动作集合和独立的输出层,因此在训练和评估模型的过程中必须使用 id 区分出不同的任务。
- 然后,每个情节都按次序分别从各自的回放单元中采样 n 个训练样本,并基于这些训练样本来构造损失函数,以指导学习模型的训练。
基于渐进式神经网络
上面分别介绍了两种用于解决 DRL问题的迁移学习方法.然而这两种迁移学习方法都存在一定的局限性:
- 在迁移知识之前,都需要
耗费大量的训练样本来指导模型的训练。 - 虽然训练样本的获取对于视频游戏任务是没有难度的,但一些真实场景下的机器人控制任务就很难在线获取大量的训练数据。
- 在这类消耗资源较多的场景中,
试错学习会造成较大的损失。
Rusa 等人提出了一种基于渐进式神经网络(progressive neural networks)的迁移 DRL 方法。该渐进式神经网络可以通过逐层存储迁移知识和提取有价值特征,解决从仿真环境中迁移知识到真实环境的难题。
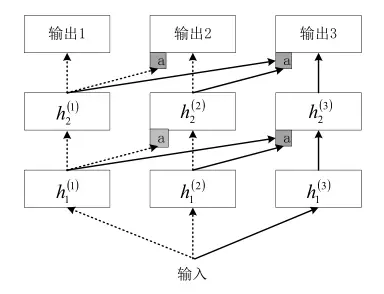
渐进式神经网络的构成过程可以描述为:
- 在第1列构造1个深度神经网络来训练某一任务
- 为了训练第2个任务,通过以下方式构造第2列深度神经网络:固定第1列神经网络的参数,并将其网络中各个隐藏层的激活值通过适配器处理之后连接到第2列神经网络的对应层,以作为额外输入
- 为了训练第 3 个任务,通过以下方式构建第3列神经网络:固定前两列神经网络的参数,前两列网络各个隐藏层的激活值通过适配器处理之后,组合连接到当前神经网络的对应层以作为额外的输入
这种基于渐进式神经网络的迁移 DRL 方法的优势在于:针对新的任务,在训练时保留了之前训练模型的隐藏层状态,层次性地组合之前网络中每一隐藏层的有用特征,使得迁移学习拥有一个长期依赖的先验知识。
多 agent DRL
在面对一些真实场景下的复杂决策问题时,单agent 系统的决策能力是远远不够的。例如在拥有多玩家的 Atari 2600 游戏中,要求多个决策者之间存在相互合作或竞争的关系。
因此在特定的情形下,需要将 DRL 模型扩展为多个 agent 之间相互合作、通信及竞争的多 agent 系统.
多agent的合作与竞争
Tampuu 等人利用上述思想,并根据不同目标动态调整奖赏模式,提出了一种多 agent 之间可以相互合作与竞争的 DRL 模型。
实验中,通过不同的奖励模式来验证模型具备的不同功能:
- 具体地,当奖励模式设置为赢方+1 分,输方-1 分时,系统最终学到多个agent 完全相互竞争的策略。
- 而如果将奖赏模式设置为不论每次结果如何赢方输方都为-1 分时,多个agent 就可以学到一种完全相互协作的策略。
基于通信协议的分布式深度循环Q网络
在面对一类需要多 agent 之间相互沟通的推理式任务时,通常 DQN 模型并不能学习到有效的策略。
针对此问题,Foerster 等人提出了一种称为分布式深度循环 Q 网络(Deep Distributed RecurrentQ-Networks,DDRQN)的模型,解决了状态部分可观察的多 agent 通信与合作的挑战性难题.
- 经过训练的 DDRQN 模型最终在多agent 之间达成了一致的通信协议.这使得 DRL 算法成功地学习到一种通信协议,对于解决多 agent的协作式任务具有较深远的意义。
- 因此未来可以通过DDRQN模型来对物联网和移动智能设备上的通信协议进行学习和优化,以使其能够更好地适应不同的应用场景。
基于记忆与推理的DRL
传统的基于视觉感知的 DRL 方法在解决更高层次的认知启发式任务(cognition-inspired tasks)时,其表现比起人类还相差甚远。
即在解决一些高层次的 DRL 任务时,agent 不仅需要很强的感知能力,也需要具备一定的记忆与推理能力,才能学习到有效的决策.因此赋予现有 DRL 模型主动记忆与推理的能力就显得十分重要。
基于记忆网络
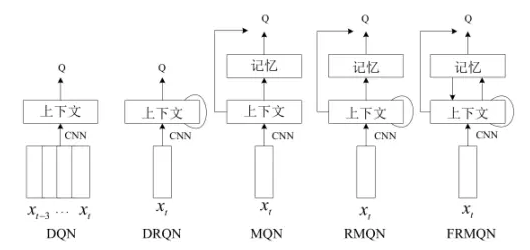
Junhyuk 等人通过在传统的 DRL 模型中加入外部的记忆网络部件,并通过学习使模型拥有了一定的记忆和推理能力。根据是否加入 RNN 部件和反馈控制机制,可以分为以下几种模型:
- 记忆深度 Q 网络(Memory Q-Network,
MQN) - 记忆深度循环 Q 网络(Recurrent Memory Q-Network,
RMQN) - 基于反馈控制机制的记忆深度循环 Q 网络(Feedback Recurrent Memory Q-Network,
FRMQN)
模型无关的情节式控制器
由认知神经科学可知,哺乳动物的学习系统包括两个部分:一部分用于缓慢学习结构化的知识;另一部分用于快速存储感知到的信息,并通过大脑中的海马体结构回放存储信息。这两部分构成一个完整的学习结构化知识的系统。
Blundell 等人设计出一种模型无关的情节式控制器(Model-Free Episode Control,MFEC)。
该控制器可以快速存储和回放状态转移序列,并将回放的序列整合到结构化知识的系统中,使得该控制器可以快速存储和回放状态转移序列,并将回放的序列整合到结构化知识的系统中,使得 agent 在面对一些较复杂的时序决策任务时,能够在更短的时间周期内达到人类玩家的水平。
以下内容来自于Alex的总结。
DRL的不足
1.它的样本利用率非常低。
- 换言之为了让模型的表现达到一定高度需要
极为大量的训练样本。
2.最终表现很多时候不够好。
- 在很多任务上用非强化学习甚至非学习的其它方法,如基于模型的控制(model based control),线性二次型调节器(Linear Quadratic Regulator)等等可以获得好得多的表现。最气人的是这些模型很多时候样本利用率还高。
- 当然这些模型有的时候会有一些假设比如有训练好的模型可以模仿,比如可以进行蒙特卡洛树搜索等等。
3.DRL 成功的关键离不开一个好的奖励函数(reward function),然而这种奖励函数往往很难设计。
- 在 Deep Reinforcement Learning That Matters 作者提到有时候把奖励乘以一个常数模型表现就会有天和地的区别。但奖励函数的坑爹之处还不止如此。奖励函数的设计需要保证:
- 加入了合适的先验
- 良好的定义了问题
- 在一切可能状态下的对应动作。
- 但模型很多时候会找到作弊的手段。
- Alex 举的一个例子是有一个任务需要把红色的乐高积木放到蓝色的乐高积木上面,奖励函数的值基于红色乐高积木底部的高度而定。结果一个模型直接把红色乐高积木翻了一个底朝天…
- 奖励函数的值太过稀疏。
- 换言之大部分情况下奖励函数在一个状态返回的值都是 0。这就和我们人学习也需要鼓励,学太久都没什么回报就容易气馁。
- 有的时候在奖励函数上下太多功夫会引入新的偏见(bias)。
4.局部最优/探索和剥削(exploration vs. exploitation)的不当应用。 Alex举的一个例子是有一个连续控制的环境里,一个类似马的四足机器人在跑步,结果模型不小心多看到了马四脚朝天一顿乱踹后结果较好的情况,于是你只能看到四脚朝天的马了。
5.对环境的过拟合。
- DRL 少有在多个环境上玩得转的。你训练好的 DQN 在一个 Atari game上work 了,换一个可能就完全不 work。即便你想要做迁移学习,也没有任何保障你能成功。
6.不稳定性。
- 读 DRL 论文的时候会发现有时候作者们会给出一个模型表现随着尝试 random seed 数量下降的图,几乎所有图里模型表现最终都会降到 0。相比之下在监督学习里不同的超参数或多或少都会表现出训练带来的变化,而 DRL 里运气不好可能很长时间你模型表现的曲线都没有任何变化,因为完全不 work。
- 即便知道了超参数和随机种子,你的实现只要稍有差别,模型的表现就可以千差万别。这可能就是 Deep Reinforcement Learning That Matters 一文里 John Schulman 两篇不同文章里同一个算法在同一个任务上表现截然不同的原因。
- 即便一切都很顺利,从我个人的经验和之前同某 DRL 研究人员的交流来看只要时间一长你的模型表现就可能突然从很好变成完全不 work。原因我不是完全确定,可能和过拟合和 variance 过大有关。
DRL的成功案例
- 各类游戏:Atari Games, Alpha Go/Alpha Zero/Dota2 1v1/超级马里奥/日本将棋,其实还应该有 DRL 最早的成功案例,93年的西洋双陆棋(backgammon)
- DeepMind 的跑酷机器人。
- 为 Google 的能源中心节能。
- Google 的 AutoML。
DRL的有利条件
- 数据获取非常容易,非常 cheap。
- 不要急着一上来就攻坚克难,可以从简化的问题入手。
- 可以进行左右互搏。
- 奖励函数容易定义。
- 奖励信号非常多,反馈及时。
展望
Alex指出了一些未来潜在的发展方向和可能性:
- 局部最优或许已经足够好。未来某些研究可能会指出我们不必过于担心大部分情况下的局部最优。因为他们比起全局最优并没有差很多。
- 硬件为王。在硬件足够强的情况下我们或许就不用那么在乎样本利用率了,凡事硬刚就可以有足够好的表现。各种遗传算法玩起来。
- 人为添加一些监督信号。在环境奖励出现频次太低的情况下可以引入自我激励(intrinsic reward)或者添加一些辅助任务,比如DeepMind就很喜欢这套,之前还写了一篇 Reinforcement Learning with Unsupervised Auxiliary Tasks(https://arxiv.org/abs/1611.05397) 。LeCun 不是嫌蛋糕上的樱桃太少吗,让我们多给他点樱桃吧!
- 更多融合基于模型的学习从而提高样本使用率。这方面的尝试其实已经有很多了,具体可以去看 Alex 提到的那些工作。但还远不够成熟。
- 仅仅把 DRL 用于 fine-tuning。比如最初 Alpha Go 就是以监督学习为主,以强化学习为辅。
- 自动学习奖励函数。这涉及到 inverse reinforcement learning 和 imitation learning。
- 迁移学习和强化学习的进一步结合。
- 好的先验。
- 有的时候复杂的任务反而更容易学习。Alex 提到的例子是 DeepMind 经常喜欢让模型学习很多同一环境的变种来减小对环境的过拟合。我觉得这也涉及 curriculum learning,即从简单的任务开始逐步加深难度。可以说是层层递进的迁移学习。另外一个可能的解释是很多时候人觉得困难的任务和机器觉得困难的任务是相反的。比如人觉得倒水很简单,你让机器人用学习的路子去学倒水就可以很难。但反过来人觉得下围棋很简单而机器学习模型却在下围棋上把人击败了。