Last updated on 2018-10-29…
循环神经网络是深度学习的主要内容之一,可以处理文本、音频和视频等序列数据;可用于将序列分解为高级理解、注释序列,甚至从头开始生成新序列。
原英文链接:https://distill.pub/2016/augmented-rnns/
RNN与LSTM
1.RNN网络示意图:
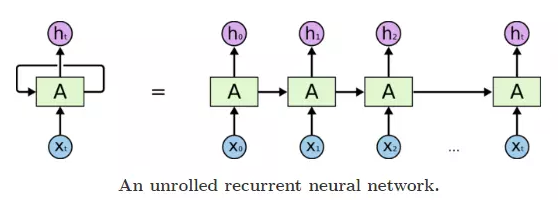
放大一点:

2.传统的RNN设计与较长的序列相悖,于是就出现了 LSTM “长短期记忆”网络
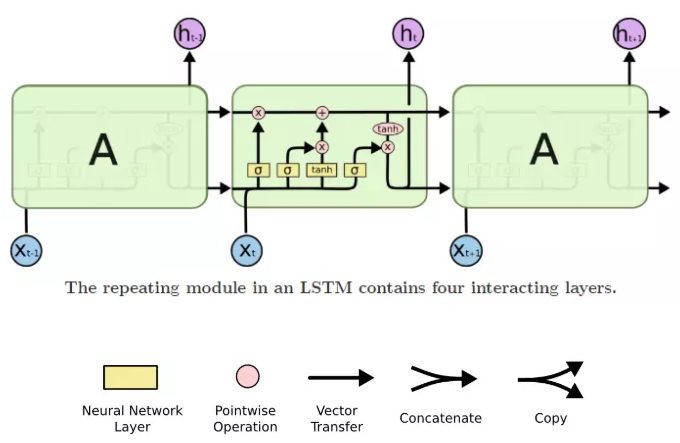
3.后来衍生出四个大方向:
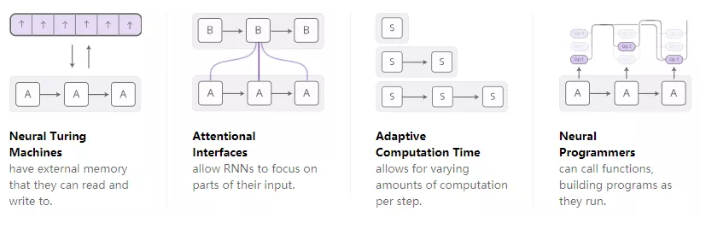
Neural Turing Machines
Neural Turing Machines 神经图灵机将RNN与外部存储器组合在一起:
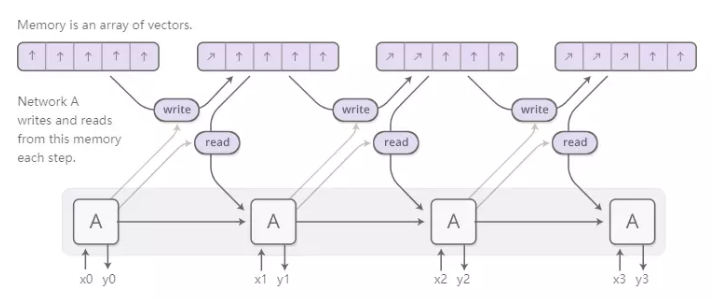
但read和write如何运作?挑战在于我们希望使它们具有差异性。特别是,我们希望使它们在我们读取或写入的位置方面具有可区分性,以便我们可以了解读写的位置。这很棘手,因为内存地址似乎基本上是离散的。
NTM为此提供了一个非常聪明的解决方案:每一步,它们都可以在不同的范围内进行读写。
1.举个例子,让我们专注于阅读。RNN不是指定单个位置,而是输出“注意力分布”,描述我们如何分散我们关心不同记忆位置的值。因此,读取操作的结果是加权和。

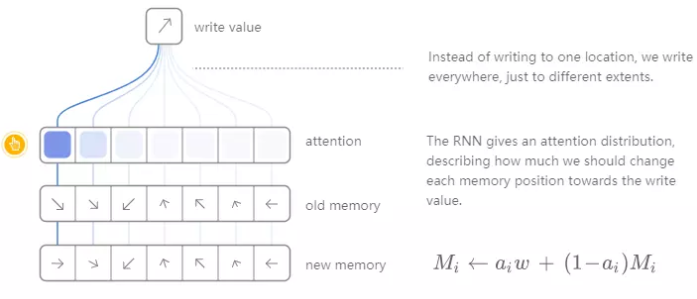
2.同样,我们一次到不同程度地写到处。同样,注意力分布描述了我们在每个位置写了多少。
我们通过使存储器中的位置的新值成为旧存储器内容和写入值的凸起组合来实现这一点,其中两者之间的位置由注意力量决定。
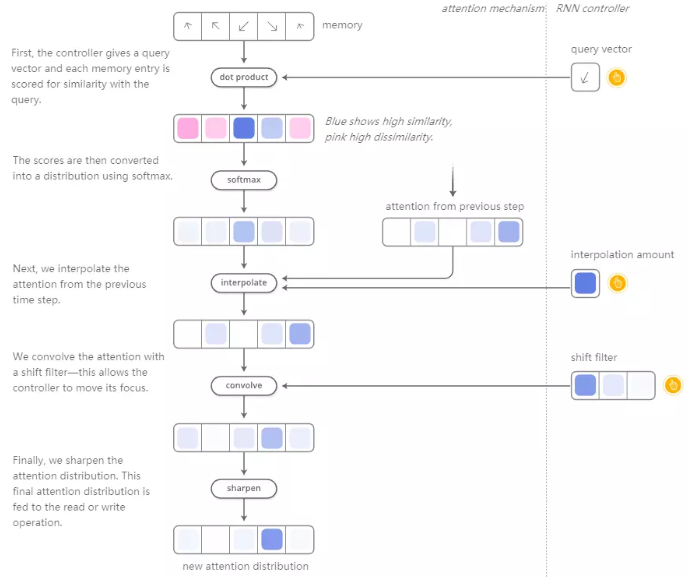
3.但NTM如何决定内存中的哪些位置集中注意力呢?它们实际上使用两种不同方法的组合:基于内容的注意力和基于位置的注意力。
基于内容的关注允许NTM搜索他们的内存并专注于与他们正在寻找的内容匹配的位置,而基于位置的注意力允许内存中的相对移动,使NTM循环。
这种读写功能允许NTM执行许多以前超出神经网络的简单算法。例如,它们可以学习在内存中存储一个长序列,然后循环遍历它,重复重复它。
当它们这样做时,我们可以看到它们读写的地方,以便更好地了解它们正在做的事情:
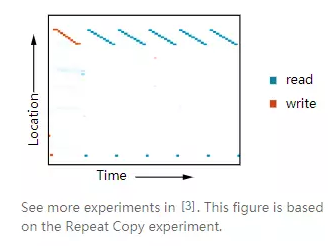
它们还可以学习模仿查找表(lookup table),甚至学习排序数字!另一方面,它们仍然不能做很多基本的事情,比如加或加数。
自最初的NTM论文以来,已经有许多令人兴奋的论文探讨类似的方向:
Neural GPU 神经GPU克服了NTM无法增加和增加数字的能力。RL NTMZaremba和Sutskever使用强化学习训练NTM,而不是原始使用的可微分读/写。Neural Random Access Machines 神经随机访问机基于指针工作。- 一些论文探讨了可区分的数据结构,如
堆栈和队列12。内存网络12是另一种攻击类似问题的方法。
在某种客观意义上,这些模型可以执行的许多任务,例如学习如何添加数字。神经网络还能够做很多其他的事情,但是像神经图灵机这样的模型似乎已经对它的能力产生了极大的限制。
这些模型有许多开源实现。NTM的开源实现包括Taehoon Kim(TensorFlow),Shawn Tan(Theano),Fumin(Go),Kai Sheng Tai(Torch)和Snip(Lasagne)。 Neural GPU的代码是开源的,并放在TensorFlow模型库中。 Memory Networks的开源实现包括Facebook(Torch / Matlab),YerevaNN(Theano)和Taehoon Kim(TensorFlow)。
Attentional Interfaces
当我们翻译一个句子时,我们特别注意自己正在翻译的这个词。当我们正在录制录音时,我们会仔细聆听自己正在积极写下的片段。如果有人让我们描述正坐在哪里的房间,我们会瞥一眼自己正在描述的物体。
神经网络可以使用注意力实现相同的行为,专注于他们给出的信息的一部分。例如,RNN可以通过另一个RNN的输出参加。在每个时间步骤,它侧重于另一个RNN中的不同位置。
我们希望注意力是可以区分的,这样我们就可以学会在哪里集中注意力。要做到这一点,我们使用神经图灵机使用的相同技巧:我们专注于各处,只是不同程度。
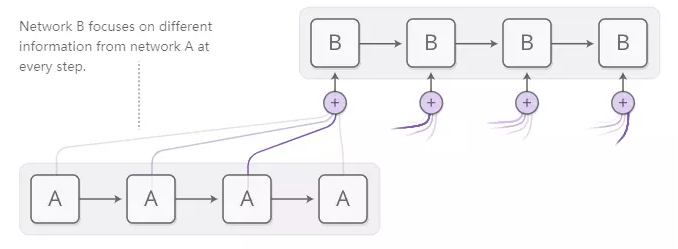
注意力分布通常是基于内容的注意力产生的。参与的RNN生成描述其想要关注的内容的查询。每个项目都使用查询进行点生成,以生成分数,描述它与查询的匹配程度。将得分输入softmax以产生注意力分布。
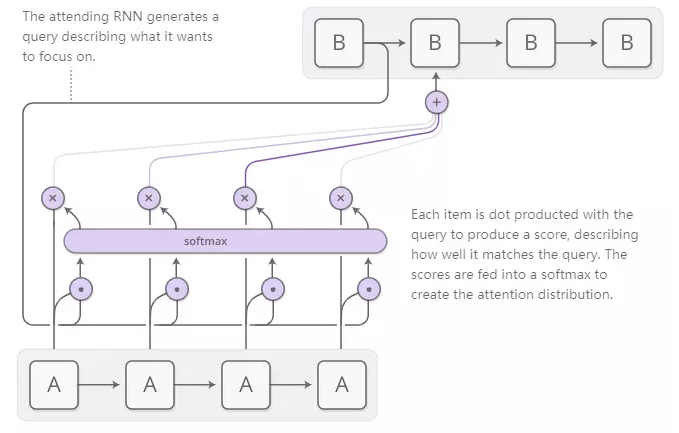
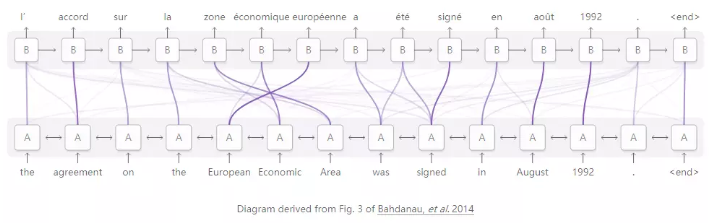
RNN之间关注的一个用途是翻译。传统的序列到序列模型必须将整个输入分解为单个向量,然后将其扩展回来。注意通过允许RNN处理输入以传递关于它看到的每个单词的信息来避免这种情况,然后RNN生成输出以在它们变得相关时关注单词。
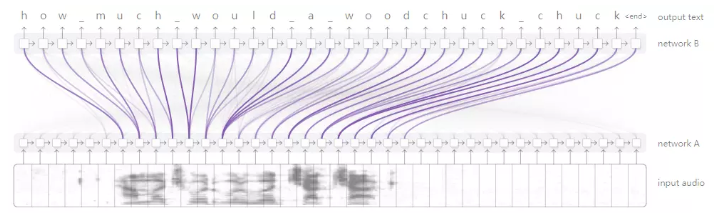
RNN之间的这种关注还有许多其他应用。它可以用于语音识别,允许一个RNN处理音频,然后让另一个RNN浏览它,在生成成绩单时关注相关部分。
这种关注的其他用途包括解析文本,它允许模型在生成解析树时浏览单词,以及用于会话建模,其中模型可以关注对话的前面部分因为它产生了它的反应。
注意也可以用在卷积神经网络和RNN之间的接口上。这允许RNN每步查看图像的不同位置。这种关注的一个流行用途是用于图像字幕。首先,conv网络处理图像,提取高级特征。然后运行RNN,生成图像的描述。由于它在描述中生成每个单词,RNN侧重于conv网对图像相关部分的解释。我们可以明确地想象这个:

更广泛地说,只要想要与其输出中具有重复结构的神经网络接口,就可以使用注意力接口。我们已经发现注意力接口是一种非常通用且功能强大的技术,并且正变得越来越普遍。
Adaptive Computation Time
标准RNN对每个时间步进行相同的计算量,还限制了RNN对长度为n的列表进行O(n)运算。这似乎不是很合理。(当事情艰难时人们会选择多思考一下,对吧?)
自适应计算时间是RNN每步执行不同计算量的一种方法。总体思路很简单:允许RNN为每个时间步进行多个计算步骤。
为了让网络了解要执行的步骤数,我们希望步数可以区分。我们使用之前使用的相同技巧实现了这一点:我们不是决定运行离散数量的步骤,而是在运行步骤数量上分配注意力。输出是每个步骤的输出的加权组合。
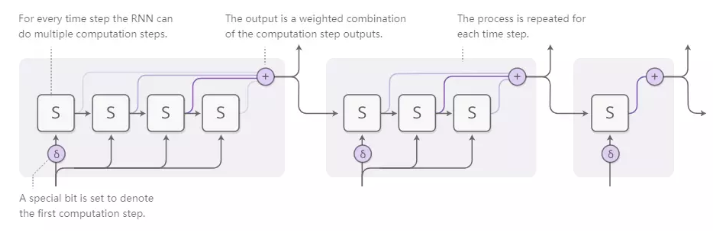
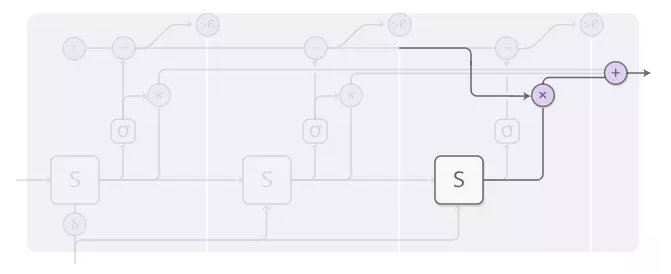
还有一些细节,在上图中省略了。这是一个包含三个计算步骤的时间步骤的完整图表。
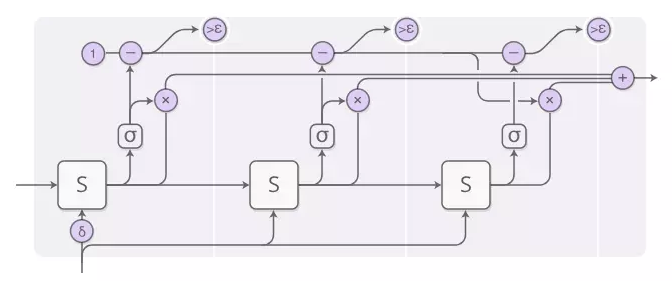
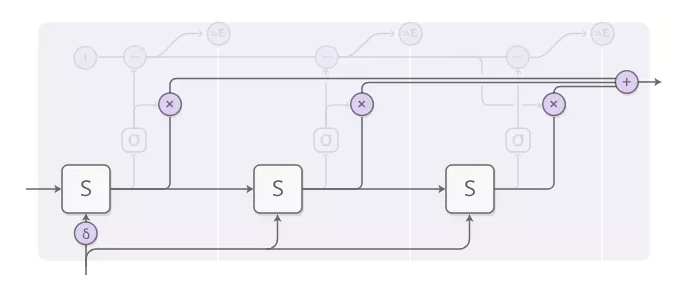
这有点复杂,所以让我们一步一步地完成它。在高级别,我们仍在运行RNN并输出状态的加权组合:
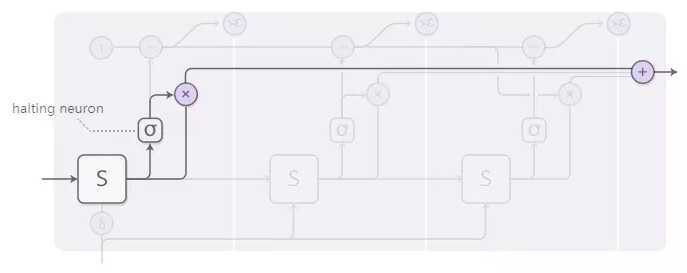
每个步骤的重量由“停止神经元”决定。它是一个S形神经元,它看着RNN状态并给出一个停止的重量,我们可以将其视为我们应该在该步骤停止的概率。
暂停权重为1的总预算,因此我们跟踪顶部的预算。当它达到低于epsilon时,我们停止。
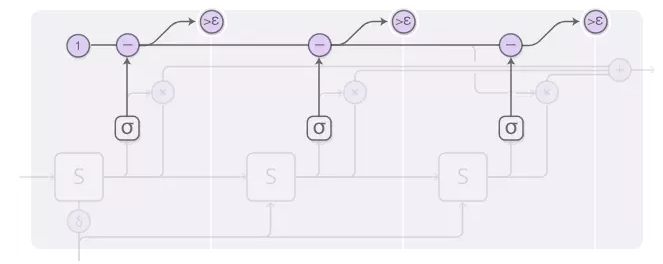
当我们停下来时,可能会有一些因为我们在低于epsilon时停止而停止预算。我们应该怎么做呢?从技术上讲,它将被用于未来的步骤,但我们不想计算这些步骤,因此我们将其归因于最后一步。
在训练自适应计算时间模型时,可以在成本函数中添加“ponder cost 思考成本”项。这会使模型对其使用的计算量进行惩罚。这个术语越大,用于降低计算时间的性能就越大。
自适应计算时间是一个非常新的想法,但我们相信它和类似的想法将是非常重要的。
代码:目前唯一的自适应计算时间的开源实现似乎是Mark Neumann(TensorFlow)。
Neural Programmer
神经网络在许多任务中都很出色,但它们也很难做一些基本的事情,比如算法,这在普通的计算方法中是微不足道的。有一种方法可以将神经网络与正常编程融合在一起,并获得两全其美的效果。
神经程序员就是这样做的一种方法。它学会创建程序以解决任务。实际上,它学会了生成这样的程序而不需要正确程序的例子。它发现如何制作程序作为完成某项任务的手段。
本文中的实际模型通过生成类似SQL的程序来查询表来回答有关表的问题。然而,这里有许多细节使它有点复杂,所以让我们首先想象一个稍微简单的模型,给出一个算术表达式并生成一个程序来评估它。
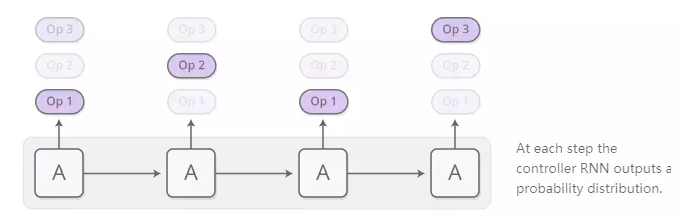
生成的程序是一系列操作。每个操作被定义为对过去操作的输出进行操作。因此,操作可能类似于“在前两步添加操作的输出以及在1步之前添加操作的输出。”它更像是一个Unix管道,而不是一个带有变量分配和读取的程序。

程序由控制器RNN一次生成一个操作。在每个步骤,控制器RNN输出下一个操作应该是什么的概率分布。例如,我们可能非常确定我们想要在第一步执行添加,然后很难确定我们是否应该在第二步增加或分割,依此类推……
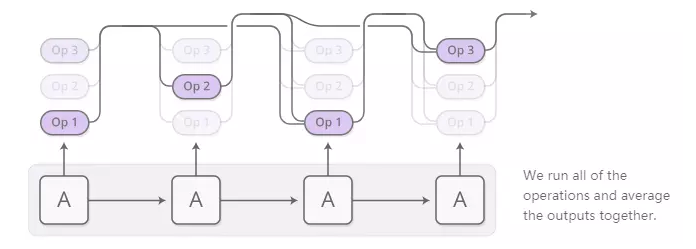
现在可以评估生成的操作分布。我们不是在每一步都运行单个操作,而是通常运行所有这些操作的注意技巧,然后将输出平均在一起,加权我们运行该操作的概率。
只要我们可以通过操作定义导数,程序的输出就可能性而言是可微的。然后我们可以定义一个损失,并训练神经网络以产生给出正确答案的程序。通过这种方式,神经程序员学会了在没有好程序实例的情况下编写程序。唯一的监督是该计划应该产生的答案。
这是神经程序员的核心思想,此外还有一些额外的巧妙技巧:
- 多种类型:神经网络编程器中的许多操作都处理标量数以外的类型。某些操作输出表列的选择或单元格的选择。只有相同类型的输出才能合并在一起。
- 引用输入:神经程序员需要回答诸如“有多少城市人口超过1,000,000?”这样的问题,给出一个有人口列的城市表。为了实现这一点,一些操作允许网络引用他们正在回答的问题中的常量或列的名称。这种引用基于注意力(指针网络)。
神经网络编程器并不是神经网络生成程序的唯一方法。另一个可爱的方法是神经程序员 - 解释器,它可以完成许多非常有趣的任务,但需要以正确程序的形式进行监督。
我们认为,弥合传统编程和神经网络之间差距的这个一般空间非常重要。虽然神经网络程序员显然不是最终的解决方案,但我们认为有很多重要的经验教训可供学习。
代码:用于问答的神经程序员的最新版本已由其作者开源,并可作为TensorFlow模型使用。Ken Morishita(Keras)还实现了神经程序员 - 解释器。
结束语
从某种意义上说“A human with a piece of paper is, in some sense, much smarter than a human without. A human with mathematical notation can solve problems they otherwise couldn’t.”。使用计算机使我们能够获得令人难以置信的壮举,否则这些壮举将远远超出我们的能力范围。
总的来说,似乎许多有趣的智力形式是人类的创造性启发式直觉与一些更加清晰细致的媒介(如语言或方程式)之间的相互作用。有时,媒介是物理存在的东西,为我们存储信息,防止我们犯错误,或者计算繁重。在其他情况下,媒介是我们操纵的头脑中的模型。无论哪种方式,它似乎对情报至关重要。
机器学习的最新成果已经开始具有这种风格,将神经网络的直觉与其他东西结合起来。一种方法是人们称之为“启发式搜索”。例如,AlphaGo阐述了Go模型的工作原理,探讨了如何用神经网络的直觉(intuition)指导游戏。同样,DeepMath 使用神经网络作为操纵数学表达式的直觉。我们在本文中讨论的“增强型RNN”是另一种方法,我们将RNN连接到工程媒体,以扩展其一般功能。
与媒体互动自然涉及制定一系列采取行动,观察并采取更多行动。这带来了一个重大挑战:我们如何了解采取哪些行动?这听起来像是强化学习问题,我们当然可以采取这种方法。但强化学习文献实际上正在攻击这个问题的最难版本,其解决方案很难使用。关注的一个奇妙之处在于它通过部分地采取不同程度的所有动作,为我们提供了一个更容易解决这个问题的方法。这是有效的,因为我们可以设计类似NTM内存的媒介:允许分数操作并且可以区分。强化学习让我们走一条路,并尝试从中学习:注意力在每个分支方向上进行,然后将路径合并在一起。
注意力的一个主要缺点是我们必须在每一步都采取一切“行动”。这会导致计算成本线性增长,就像增加神经图灵机中的内存量一样。你可以想象的一件事就是让你的注意力稀少,这样你只需触摸一些记忆。然而,它仍然具有挑战性,因为你可能想要做一些事情,比如你的注意力取决于记忆的内容,并且这样做会天真地迫使你去看每个记忆。我们已经看到了一些初步的尝试来解决这个问题,比如用分层注意记忆学习高效算法,但似乎还有很多工作要做。如果我们真的可以让这种亚线性时间注意力发挥作用,那将是非常强大的!
增强循环神经网络和潜在的注意力技术令人难以置信。我们期待看到接下来会发生什么!