Last updated on 2019-4-9…
流程图
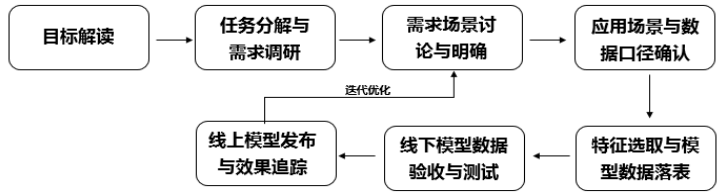
1.目标解读
- 在建立用户画像前,首先需要明确用户画像服务于企业的对象,根据业务方需求,未来产品建设目标和用户画像分析之后预期效果;
2.任务分解与需求调研
- 经过第一阶段的需求调研和目标解读,我们已经明确了用户画像的服务对象与应用场景,接下来需要针对服务对象的需求侧重点,结合产品现有业务体系和“数据字典”规约实体和标签之间的关联关系,明确分析纬度;
3.需求场景讨论与明确
- 在本阶段,数据运营人员需要根据前面与需求方的沟通结果,输出《产品用户画像需求文档》,在该文档中明确画像应用场景、最终开发出的标签内容与应用方式 ,并就该份文档与需求方反复沟通确认无误。
4.应用场景与数据口径确认
- 经过第三个阶段明确了需求场景与最终实现的标签纬度、标签类型后,数据运营人员需要结合业务与数据仓库中已有的相关表,明确与各业务场景相关的数据口径。在该阶段中,数据运营方需要输出《产品用户画像实施文档》,该文档需要明确应用场景、标签开发的模型、涉及到的数据库与表,应用实施流程;
5.特征选取与模型数据落表
- 本阶段中数据分析挖掘人员需要根据前面明确的需求场景进行业务建模,写好HQL逻辑,将相应的模型逻辑写入临时表中,抽取数据校验是否符合业务场景需求。
6.线下模型数据验收与测试
- 数据仓库团队的人员将相关数据落表后,设置定时调度任务,进行定期增量更新数据。数据运营人员需要验收数仓加工的HQL逻辑是否符合需求,根据业务需求抽取查看表中数据范围是否在合理范围内,如果发现问题及时反馈给数据仓库人员调整代码逻辑和行为权重的数值。
7.线上模型发布与效果追踪
- 经过第六阶段,数据通过验收之后,就可以将数据接口给到搜索、或技术团队部署上线了。上线后通过对用户点击转化行为的持续追踪,调整优化模型及相关权重配置。
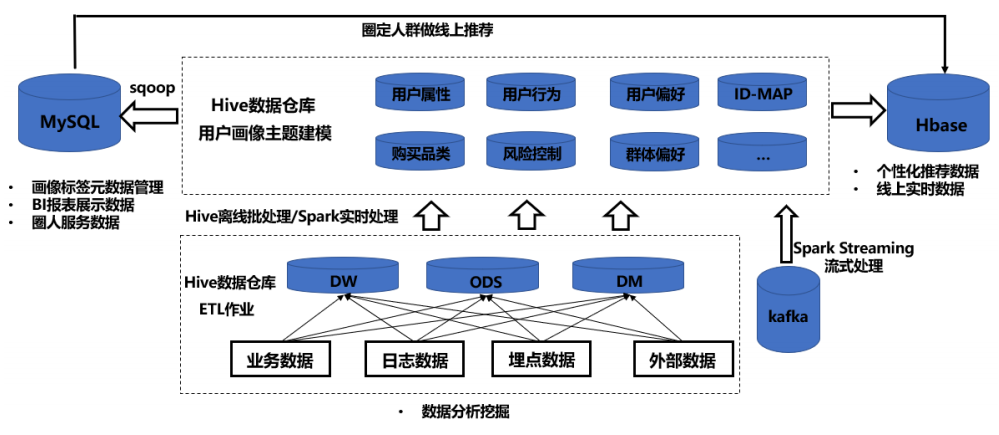
数仓架构
标签类型
用户画像建模其实就是对用户进行打标签。
统计类标签:这类标签是最为基础也最为常见的标签类型,例如对于某个用户来说,他的性别、年龄、城市、星座、近7日 活跃时长、近7日活跃天数、近7日活跃次数等字段可以从用户注册数据、用户访问、消费类数据中统计得出。该类标签构成 了用户画像的基础;
规则类标签:该类标签基于用户行为及确定的规则产生。例如对平台上“消费活跃”用户这一口径的定义为近30天交易次数>=2。 在实际开发画像的过程中,由于运营人员对业务更为熟悉、而数据人员对数据的结构、分布、特征更为熟悉,因此规 则类标签的规则确定由运营人员和数据人员共同协商确定;(同时需要借助数据调研,这要是展开又可以说很多了….)
机器学习挖掘类标签:该类标签通过数据挖掘产生,应用在对用户的某些属性或某些行为进行预测判断。例如根据一个用户 的行为习惯判断该用户是男性还是女性,根据一个用户的消费习惯判断其对某商品的偏好程度。该类标签需要通过算法挖掘 产生
正排索引与倒排索引
正排索引
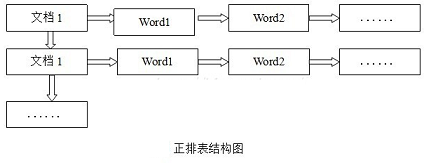
正排表是以文档的ID为关键字,表中记录文档中每个字的位置信息,查找时扫描表中每个文档中字的信息直到找出所有包含查询关键字的文档。
这种组织方法在建立索引的时候结构比较简单,建立比较方便且易于维护;因为索引是基于文档建立的,若是有新的文档加入,直接为该文档建立一个新的索引块,挂接在原来索引文件的后面。若是有文档删除,则直接找到该文档号文档对应的索引信息,将其直接删除。但是在查询的时候需对所有的文档进行扫描以确保没有遗漏,这样就使得检索时间大大延长,检索效率低下。
尽管正排表的工作原理非常的简单,但是由于其检索效率太低,除非在特定情况下,否则实用性价值不大。
倒排索引
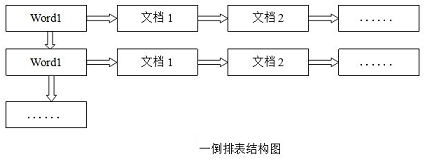
倒排表以字或词为关键字进行索引,表中关键字所对应的记录表项记录了出现这个字或词的所有文档,一个表项就是一个字表段,它记录该文档的ID和字符在该文档中出现的位置情况。
由于每个字或词对应的文档数量在动态变化,所以倒排表的建立和维护都较为复杂,但是在查询的时候由于可以一次得到查询关键字所对应的所有文档,所以效率高于正排表。在全文检索中,检索的快速响应是一个最为关键的性能,而索引建立由于在后台进行,尽管效率相对低一些,但不会影响整个搜索引擎的效率。
BAT用户画像浅析
百度
百度数据类型广泛,主要包含搜索数据、百度知道、百度贴吧及百度地图等数据,但是这些数据很少可以精确到个体用户层面,搜索大数据可以预测流行病爆发时间、世界杯的胜负概率及城市拥堵状况,总之百度的数据在宏观层面有不少应用,但是在微观的用户画像层面,百度毫无优势,大部分人还没有百度账号呢,百度的用户体系最近几年也是靠一些APP慢慢完善起来的。
阿里
据统计,2015年阿里巴巴活跃用户数为4.07亿,覆盖98.5%的中国互联网购物人群。其中,移动月度活跃用户达到3.93亿,占整个中国手机网民的64%,这意味着六成以上的中国手机网民都是淘宝或天猫移动端的活跃用户。(以上相关数据摘自“阿里妈妈电商营销”微信公众号)
目前阿里的数据标签已经逐步整理到阿里的数据超市——GProfile全局档案。GProfile 全局档案是以消费者档案为核心构建内容,通过分析消费者的基础信息、购物行为以描绘其特征画像。在阿里数据的平台上,GProfile 主要根据用户在历史时间内的网购行为记录,从网购时间点、内容深度剖析,提供用户基础属性、社交行为、互动行为、消费行为、偏好习惯、财富属性、信用属性和地理属性八大类标签服务。
此外,从数据能力来说,阿里的数据还可结合优酷土豆视频数据、CNZZ友盟媒体数据、虾米天天动听音乐数据等。(以上相关内容摘自“阿里数据”微信公众号)
阿里数据的特点是真实、可靠,随着公司收购其他数据类平台,阿里的数据类型也逐渐丰富起来,在用户画像数据方面,阿里可谓彻彻底底的真人数据。
腾讯
腾讯的数据优势在社交数据,此外随着微信/QQ支付的普及,腾讯也有了用户身份证、银行卡等数据。
腾讯的数据积累年限久远、维度丰富,从QQ、Qzone、腾讯微博到微信,腾讯涵盖兴趣偏好、地理位置、人口统计学信息等等数据,且准确性也不低。
腾讯在用户画像数据方面有很广泛的维度,且在兴趣、心理特征等标签上有很高的准确性。
用户画像的价值
1、精准营销
精准营销是用户画像或者标签最直接和有价值的应用。这部分也是我们广告部门最注重的工作内容。当我们给各个用户打上各种“标签”之后,广告主(店铺、商家)就可以通过我们的标签圈定他们想要触达的用户,进行精准的广告投放。无论是阿里、还是腾讯很大一部分广告都是通过这种方式来触达用户,百度的搜索广告方式有所不同。
2、助力产品
一个产品想要得到广泛的应用,受众分析必不可少。产品经理需要懂用户,除了需要知道用户与产品交互时点击率、跳失率、停留时间等行为之外,用户画像能帮助产品经理透过用户行为表象看到用户深层的动机与心理。
3、行业报告与用户研究
通过对用户画像的分析可以了解行业动态,比如90后人群的消费偏好趋势分析、高端用户青睐品牌分析、不同地域品类消费差异分析等等。这些行业的洞察可以指导平台更好的运营、把握大方向,也能给相关公司(中小企业、店铺、媒体等)提供细分领域的深入洞察。