Last updated on 2019-03-30…
演讲者:Minmin Chen, Google
引言

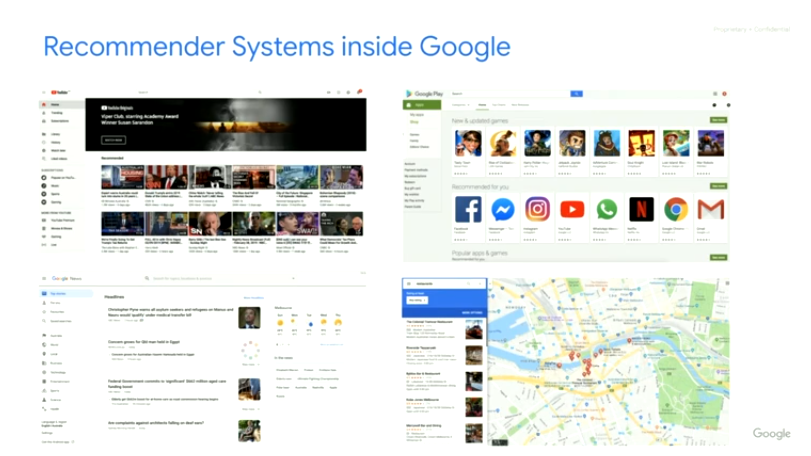
历史发展
CF

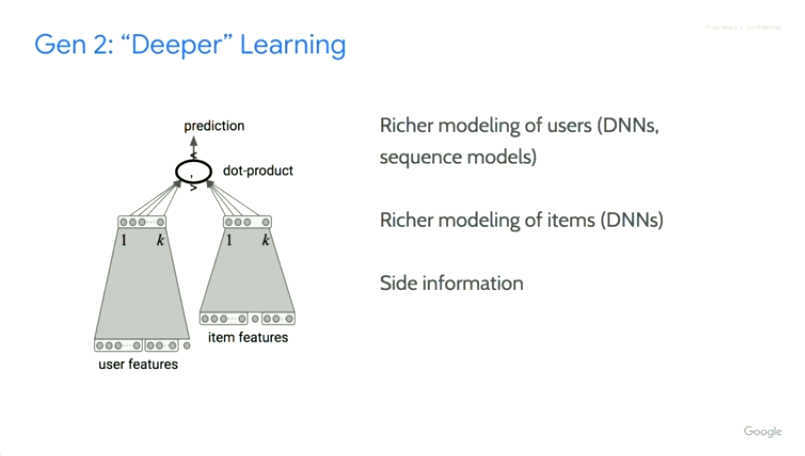
DNN
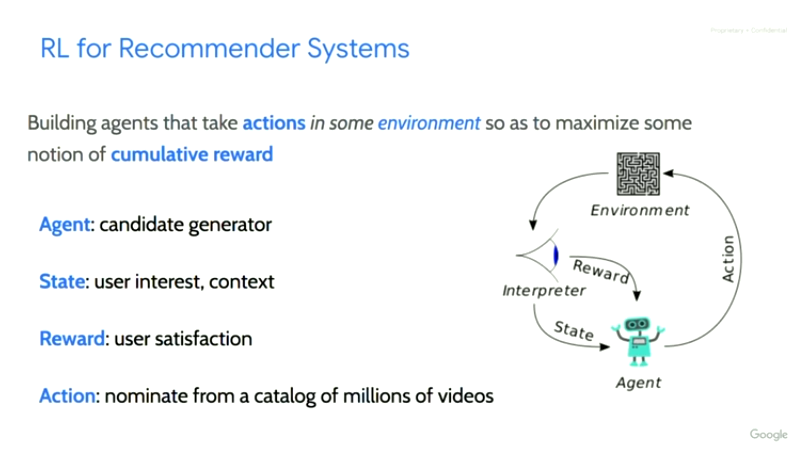
强化学习

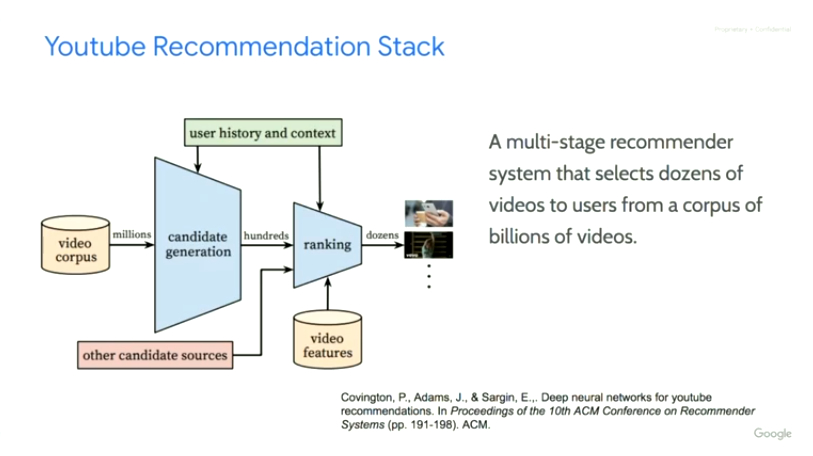
Data Source
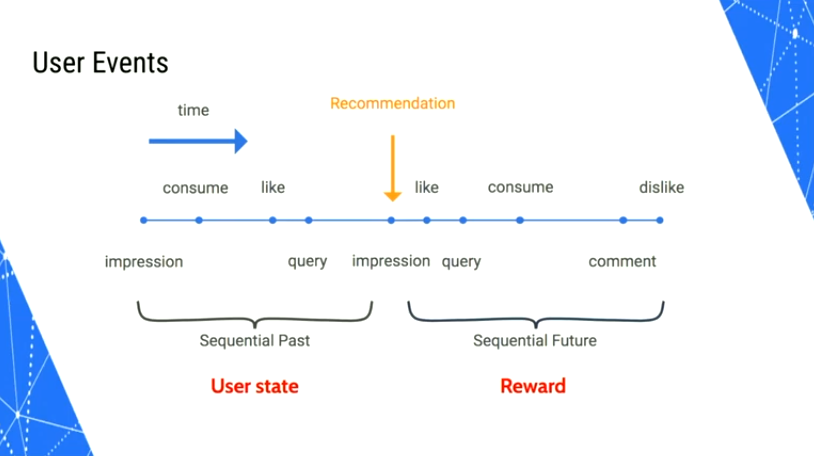
State
因为是基于用户的交互历史预测下一个用户点击的item,所以文中也采用RNN针对用户State的转换进行建模。
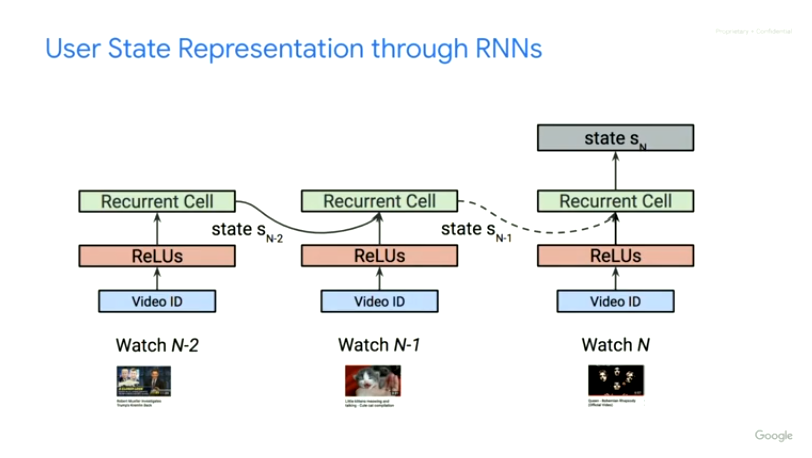 文中提到实验了包括LSTM、GRU等RNN单元,发现Chaos Free的RNN单元因为稳定高效而使用起来效果最好。
文中提到实验了包括LSTM、GRU等RNN单元,发现Chaos Free的RNN单元因为稳定高效而使用起来效果最好。
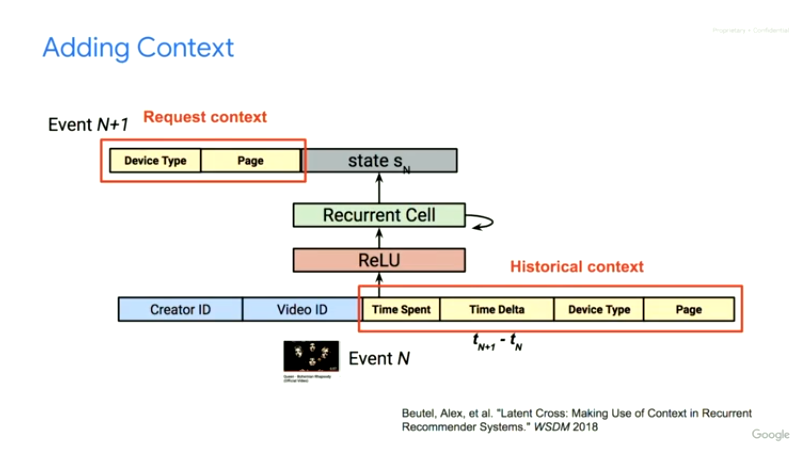
Reward

Action



Off-Policy Learning

理想情况下是收集日志的时候同时把用户相应的用户策略也就是点击概率给收集下来,
但由于策略不同等客观原因文中针对用户的行为策略使用另外一组θ’参数进行预估,而且防止它的梯度回传影响主RNN网络的训练。
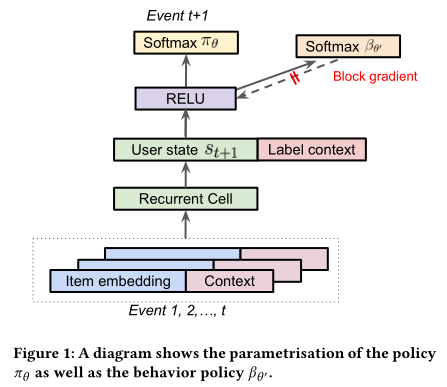

另外,由于在推荐系统中,用户可以同时看到k个展示给用户的候选item,用户可能同时与一次展示出来的多个item进行交互。因此需要扩展策略根据用户的行为历史预测下一次用户可能点击的top-K个item。
 假设同时展示K个不重复item的reward奖励等于每个item的reward的之和,根据公式推导我们可以得到Top-K的Off-Policy修正的策略梯度如下,与上面Top 1的修正公式相比主要是多了一个包含K的系数。也就是说,随着K的增长,策略梯度会比原来的公式更快地降到0。
假设同时展示K个不重复item的reward奖励等于每个item的reward的之和,根据公式推导我们可以得到Top-K的Off-Policy修正的策略梯度如下,与上面Top 1的修正公式相比主要是多了一个包含K的系数。也就是说,随着K的增长,策略梯度会比原来的公式更快地降到0。
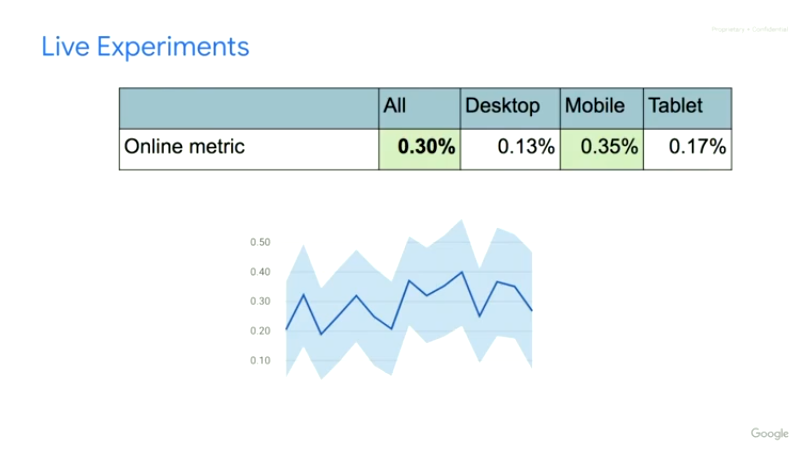
从实验结果的角度,文中进行了一系列的实验进行效果比较和验证,其中Top-K的Off-Policy修正方案带来了线上0.86%的播放时长提升。
而且前文也提到过,Minmin Chen在Industry Day上也提到线上实验效果显示这个是YouTube单个项目近两年来最大的reward增长。
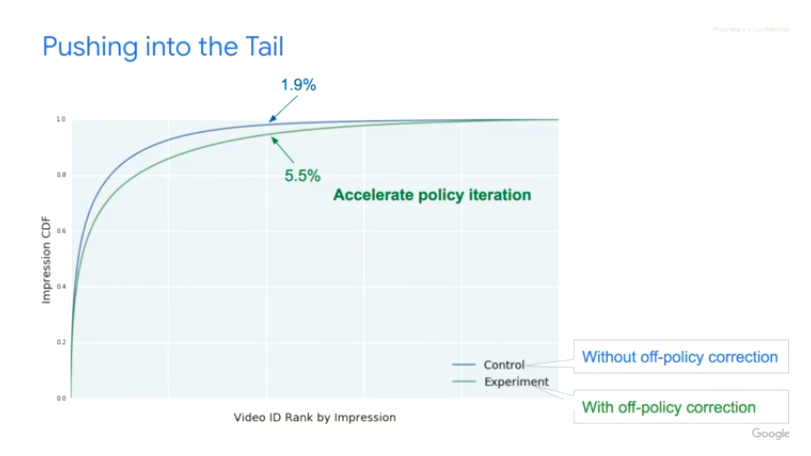
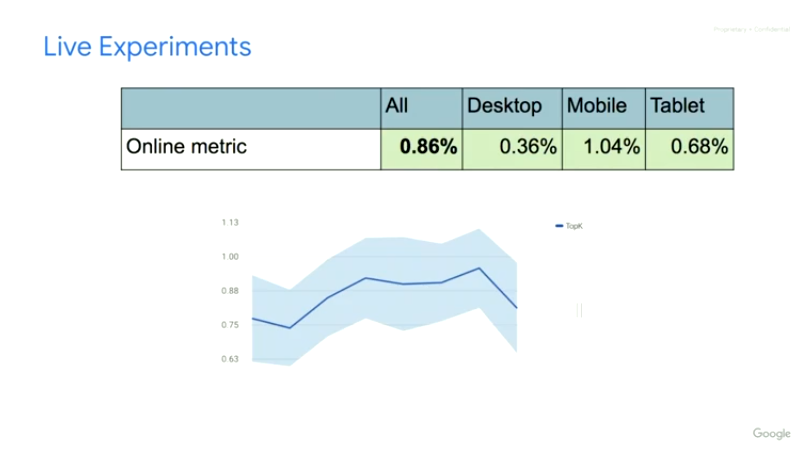
总结与展望

相关paper
- AntiSymmetricRNNs: a Dynamical System View on Recurrent Neural Networks
- Top-K Off-Policy Correction for a REINFORCE Recommender System
- Towards Neural Mixture Recommender for Long Range Dependent User Sequences
- Categorical-Attributes-Based Multi-Level Classification for Recommender Systems
- Dynamical Isometry and a Mean Field Theory of RNNs: Gating Enables Signal Propagation in Recurrent Neural Networks