Last updated on 2019-12-9…
场景
通常,在每个会话中的用户行为是相近的,而在不同会话之间差别是很大的:

DSIN模型
Base Model就是一个全连接神经网络,其输入的特征的主要分为三部分——用户特征、待推荐物品特征、用户历史行为序列特征。
用户特征如性别、城市、用户ID等待推荐物品特征:如商家ID、品牌ID等用户历史行为序列特征:如用户最近点击的物品ID序列等
这些特征会通过Embedding层转换为对应的embedding,拼接后输入到多层全连接中,并使用logloss指导模型的训练。
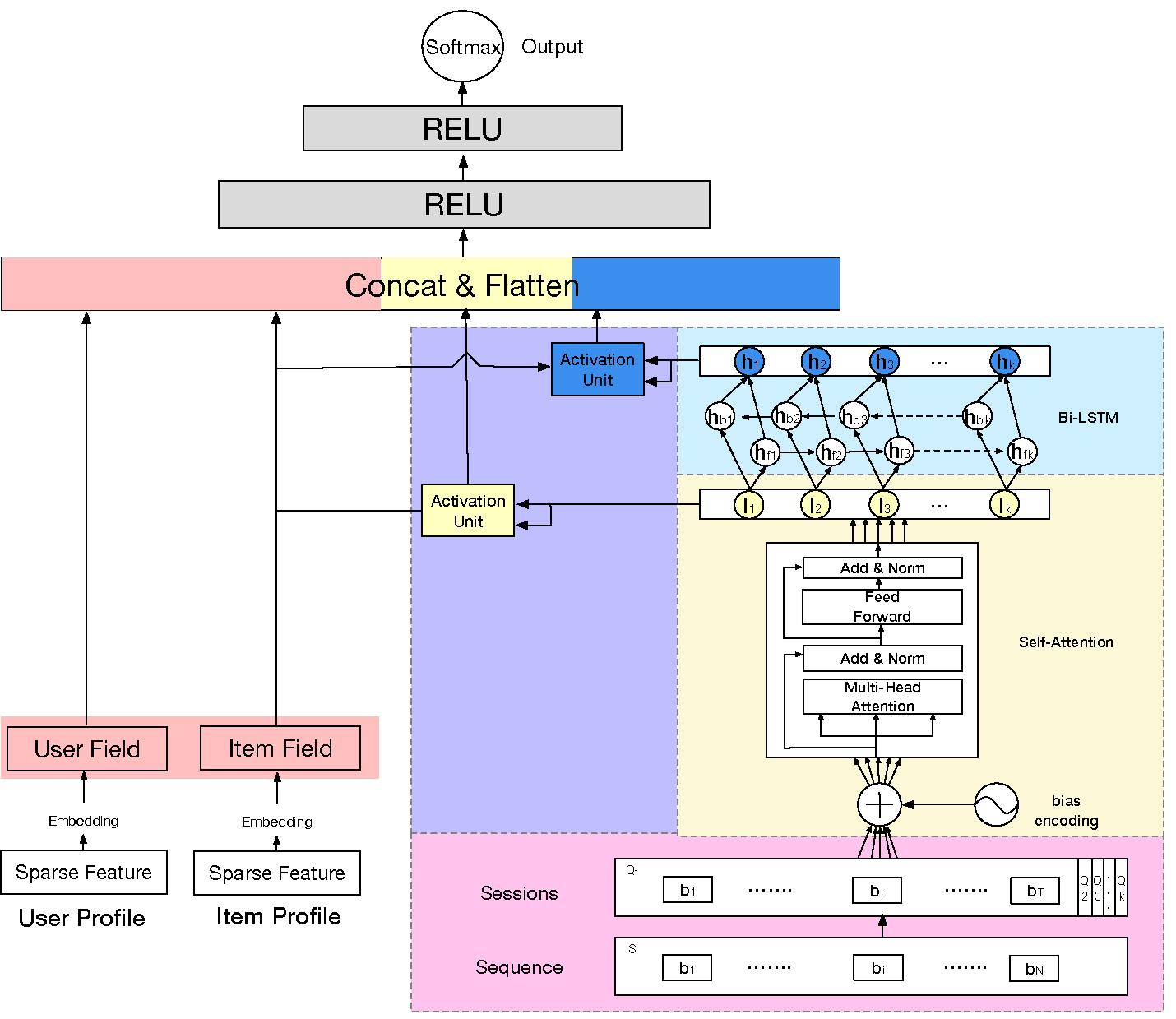 DSIN在全连接层之前,分成了两部分:
DSIN在全连接层之前,分成了两部分:
- 左边:将用户特征和物品特征转换对应的向量表示,这部分主要是一个embedding层
- 右边:对用户行为序列进行处理,从下到上分为四层:
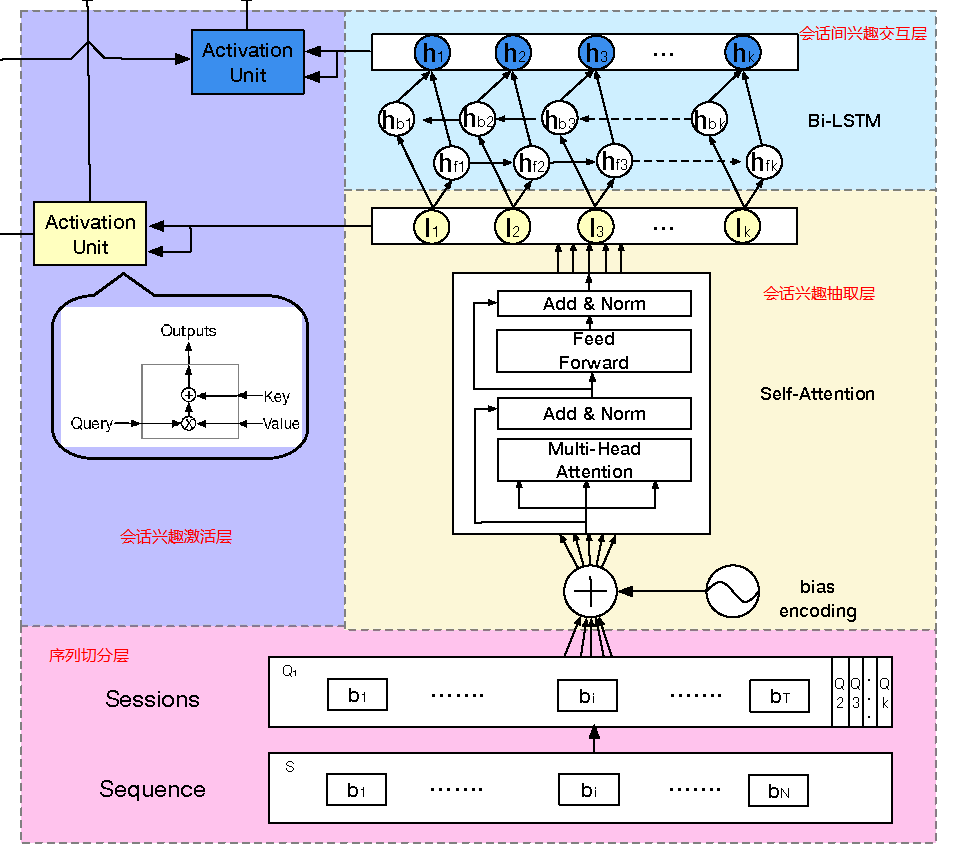
序列切分层session division layer会话兴趣抽取层session interest extractor layer会话间兴趣交互层session interest interacting layer会话兴趣激活层session interest acti- vating layer
序列切分层 session division layer
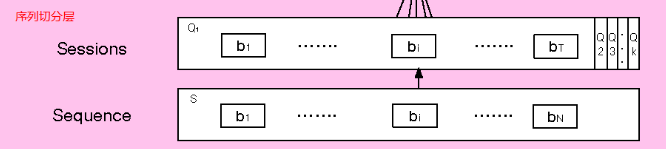
这一层将用户的行文进行切分,首先将用户的点击行为按照时间排序,判断每两个行为之间的时间间隔,前后的时间间隔大于30min就进行切分。
切分后,我们可以将用户的行为序列S转换成会话序列Q。
例如第k个会话表示为Qk=[b1;b2;…;bi;…;bT]。
其中,T是会话的长度,bi是会话中第i个行为,是一个d维的embedding向量。所以Qk是T * d的。而Q,则是K * T * d的。而Q,则是K。
会话兴趣抽取层 session interest extractor layer
这里对每个session,使用transformer对每个会话的行为进行处理。
在Transformer中,对输入的序列会进行Positional Encoding。Positional Encoding对序列中每个物品,以及每个物品对应的Embedding的每个位置,进行了处理,如下:

但在我们这里不一样了,我们同时会输入多个会话序列,所以还需要对每个会话添加一个Positional Encoding。
在DSIN中,这种对位置的处理,称为Bias Encoding,它分为三块:
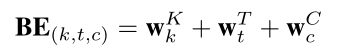
BE是K * T * d的,和Q的形状一样。BE(k,t,c)是第k个session中,第t个物品的嵌入向量的第c个位置的偏置项。
也就是说,每个会话、会话中的每个物品有偏置项,每个物品对应的embedding的每个位置,都加入了偏置项。
所以加入偏置项后,Q变为:

随后,是对每个会话中的序列通过Transformer进行处理:

这里的过程和Transformer的Encoding的block处理是一样的。经过Transformer处理之后,每个Session是得到的结果仍然是T * d。
随后,我们经过一个avg pooling操作,将每个session兴趣转换成一个d维向量。

其中Ik就代表第k个session对应的兴趣向量。
会话间兴趣交互层 session interest interacting layer
用户的会话兴趣,是有序列关系在里面的,这种关系,我们通过一个双向LSTM(bi-LSTM)来处理:
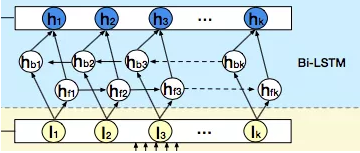
每个时刻的hidden state计算如下:
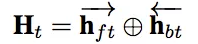
相加的两项分别是前向传播和反向传播对应的t时刻的hidden state。这里得到的隐藏层状态Ht,我们可以认为是混合了上下文信息的会话兴趣。
会话兴趣激活层 session interest acti- vating layer
用户的会话兴趣与目标物品越相近,那么应该赋予更大的权重,这里使用注意力机制来刻画这种相关性:
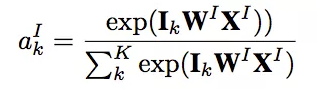
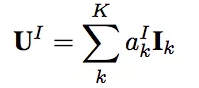
这里XI是带推荐物品向量。
同样,混合了上下文信息的会话兴趣,也进行同样的处理:
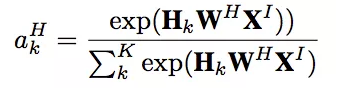
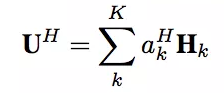
后面的话,就是把四部分的向量:用户特征向量、待推荐物品向量、会话兴趣加权向量UI、带上下文信息的会话兴趣加权向量UH进行横向拼接,输入到全连接层中,得到输出。
实验结果
本次使用了两个数据集进行了实验,分别是阿里妈妈的广告数据集和阿里巴巴的电商推荐数据集。
对比模型有:YoutubeNet、Wide & Deep、DIN 、DIN-RNN(这个和DIN很像,在原始的DIN中,用户的行为序列没有使用RNN进行处理,而DIN-RNN使用bi-LSTM对用户的历史行为序列进行处理)、DIEN。
评价指标是AUC,结果如下:

题外话:兴趣探索
DSIN在模型层面表征了用户兴趣,而用户兴趣探索实际是个庞大的工程问题。
算法最有效的能力,是识别出你最感兴趣的内容和最不感兴趣的内容。在二者之间,还存在一大块“你可能感兴趣的内容”,这些内容绝对不会被工程师和产品经理们放弃。事实上,每个人的成长也是不断地将“可能感兴趣的事情”,固化为“确定感兴趣的事情”和“确定不感兴趣的事情”的过程。
那么算法如何去探索那些人们“可能感兴趣的内容”呢?
用户兴趣泛化和窄化,其实是推荐系统中的经典问题,学界和业界一直很重视。这个问题叫EE(Exploitation Exploration):
- Exploitation是
利用,通过已知的比较确定的用户兴趣,推荐相关的内容。 - Exploratio是
探索,除了推荐给用户已知的感兴趣的内容,还需要不断探索用户的其他兴趣,避免推荐结果一成不变。
算法追求的是,尽可能地满足用户获取有价值信息的需求,并且让用户获取信息的价值最大化。
兴趣探索在短期内会减损用户使用时长,因为用户会在信息流里刷到不那么感兴趣的内容,觉得信息流很乱。但是如果不做兴趣探索,短期内可以提升点击率,但这个提升效果会迅速衰减,因此从长期看收益是负向的。
我们始终相信人对于优质来源和优质内容的鉴别力。人的判断不同于机器,但同样值得被重视。技术更快,面对海量的信息,分发效率尤其重要;但人更准,特别是进入模棱两可的地带,人的同理心和想象力能够发挥重要作用。