Last updated on 2019-09-29…
《DeepGBM: A Deep Learning Framework Distilled by GBDT for Online Prediction Tasks》,发表在 KDD 2019
介绍
CTR数据特征:
- 通常包含离散和连续两种特征
- 数据会实时增加,分布随之变化
问题的思考出发点:
- GBDT:适合处理连续特征,但不善于处理大量离散特征,且每次全量数据训练。
- NN:适合处理离散类别特征(要embedding),但不善于处理连续特征
- GBDT+NN:由于GBDT的存在,依然难以在线训练
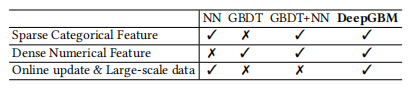
所以作者设计了DeepGBM,包含两部分:
CatNN:面向离散类别特征,实际就是DeepFMGBDT2NN:面向连续数值特征,主要做了两件事:- 对gbdt生成的tree分组,然后用NN拟合叶子的index
- 把叶子的index作embedding,单层全连接后sigmoid输出
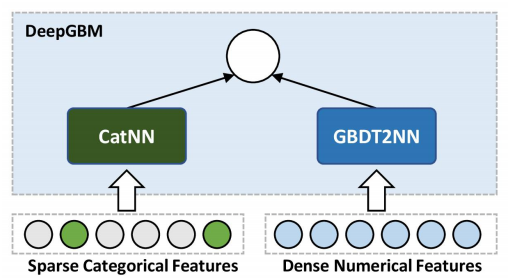
离散部分 CatNN
实际就是DeepFM

连续部分 GBDT2NN
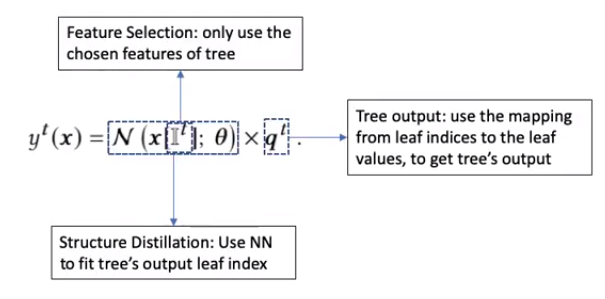
这部分主要做了三件事:
- 特征选择:只使用tree中选定的特征
- 结构蒸馏:使用NN拟合tree的叶子的index
- 决策树输出:把叶子index映射到value,得到tree的输出
单树蒸馏
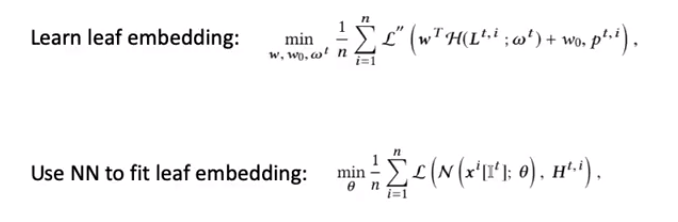
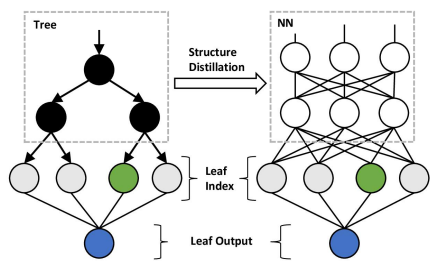
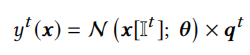
多树蒸馏
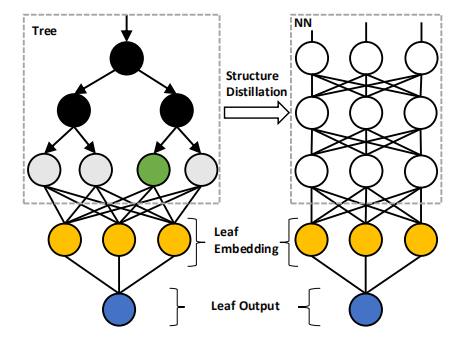
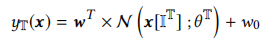
Tree Grouping
NN对应的一棵树转化代价太大,优化方法:降低蒸馏多颗tree的代价

实验
离线
 上式右侧为树组T的嵌入损失,α、β为超参数
上式右侧为树组T的嵌入损失,α、β为超参数
几种模型的效果(分类问题利用AUC,回归问题利用MSE)对比如下
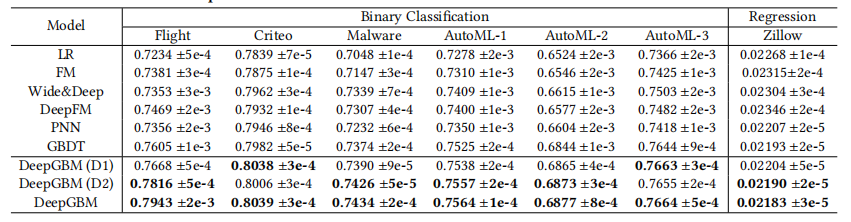
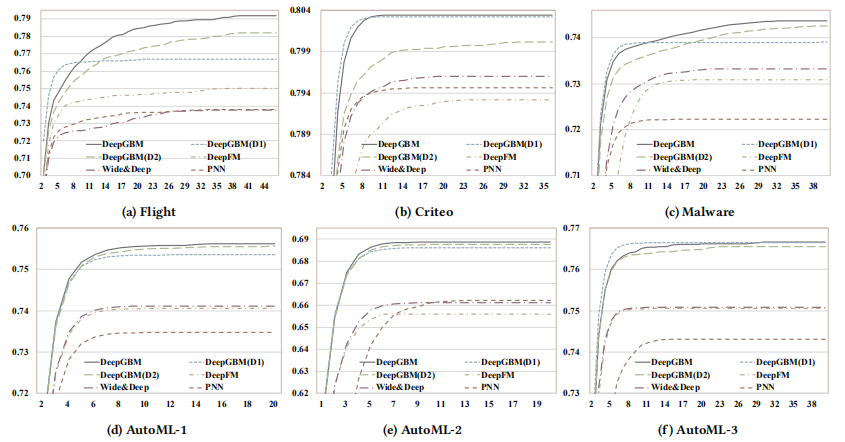
离线实验表明:
- 基于 GBDT 的模型较 NN 模型有更好的表现
- GBDT2NN 在 GBDT 的基础上还有一定提升
- DeepGBM 的表现比所有的baseline模型都要好
在线
 在线时就不涉及GBDT,也不重新训练了
在线时就不涉及GBDT,也不重新训练了
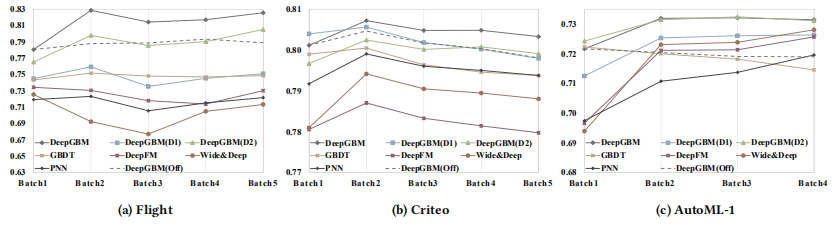
在线实验表明:
- DeepGBM 契合在线场景,且效果比所有的baseline模型都要好
个人吐槽点
- CatNN整个就是原来的DeepFM
- online实验时的loss根本不涉及gbdt,也不涉及gbdt的更新