Last updated on 2020-06-02…
本篇整理自《知识蒸馏在推荐系统的应用》
推荐系统中,复杂模型推上线时,模型响应速度太慢,当流量大的时候撑不住,而知识蒸馏(Knowledge Distilation)则是解决方法之一。
一般知识蒸馏采取Teacher-Student模式:将复杂模型作为Teacher,Student模型结构较为简单,用Teacher来辅助Student模型的训练,
Teacher学习能力强,可以将它学到的暗知识(Dark Knowledge)迁移给学习能力相对弱的Student模型,以此来增强Student模型的泛化能力。
复杂笨重但是效果好的Teacher模型不上线,就单纯是个导师角色,真正上战场挡抢撑流量的是灵活轻巧的Student小模型。
主流的知识蒸馏技术有两个技术发展主线:Logits蒸馏方法及特征蒸馏方法。
Logits蒸馏方法
Logits:分类网络最后一层输出的属于各个类别的大小数值 zi (第i个类别的Logits数值)。
qi:是Logits数值经过类Softmax变换后,归属于第i个类别的概率值(当T=1时即标准的Softmax公式)。
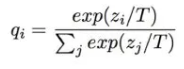
如果将T设大,则Softmax之后的Logits数值,各个类别之间的概率分值差距会缩小,也即是强化那些非最大类别的存在感;反之,则会加大类别间概率的两极分化。
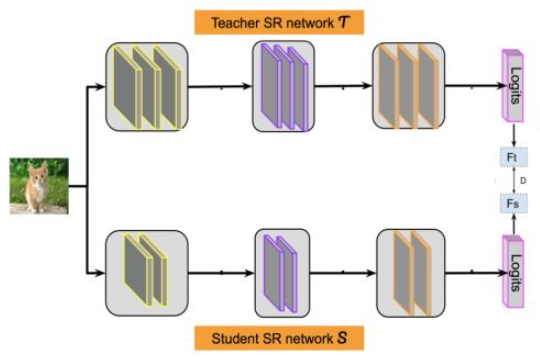
假设我们有一个Teacher网络,一个Student网络,输入同一个数据给这两个网络。
- Teacher会得到一个Logits向量 zt,代表Teacher认为输入数据属于各个类别的可能性;
- Student也有一个Logits向量 zs,代表了Student认为输入数据属于各个类别的可能性。
最简单也是最早的知识蒸馏工作,就是让Student的Logits去拟合Teacher的Logits,即Student的损失函数为:
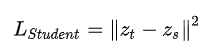
其中, 是Teacher的Logits, 是Student的Logits。在这里,Teacher的Logits就是传给Student的暗知识。
在论文《Distilling the Knowledge in a Neural Network》中,Student的损失函数由两项组成,一个子项是Ground Truth,就是在训练集上的标准交叉熵损失,让Student去拟合训练数据,另外一个是蒸馏损失,让Student去拟合Teacher的Logits:
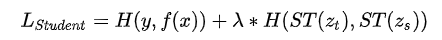
其中, H 是交叉熵损失函数, f(x) 是Student模型的映射函数, y 是Ground Truth Label, zt 是Teacher的Logits, zs 是Student的Logits, ST() 是Softmax Temperature函数, λ 用于调节蒸馏Loss的影响程度。
特征蒸馏方法
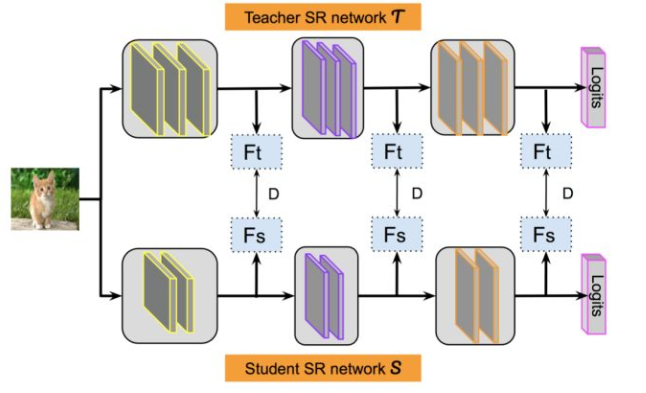
特征蒸馏方法不像Logits方法那样,Student只学习Teacher的Logits这种结果知识,而是学习Teacher网络结构中的中间层特征。
最早采用这种模式的工作来自于自于论文《FITNETS:Hints for Thin Deep Nets》,它强迫Student某些中间层的网络响应,要去逼近Teacher对应的中间层的网络响应。
这种情况下,Teacher中间特征层的响应,就是传递给Student的暗知识。在此之后,出了各种新方法,但是大致思路还是这个思路,本质是Teacher将特征级知识迁移给Student。
精排蒸馏
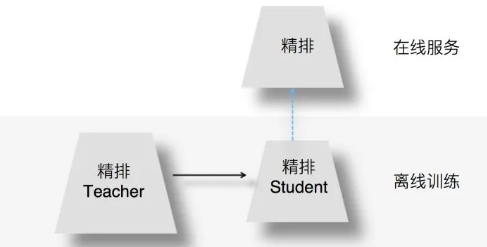
离线训练的时候,可以训练一个复杂精排模型作为Teacher,一个结构较简单的DNN排序模型作为Student。
- 在Student训练的时候,除了采用常规的Ground Truth训练数据外,Teacher也辅助Student的训练,将Teacher复杂模型学到的一些知识迁移给Student,增强其模型表达能力。
- 在模型上线服务的时候,使用小的Student作为线上服务精排模型,进行在线推理。
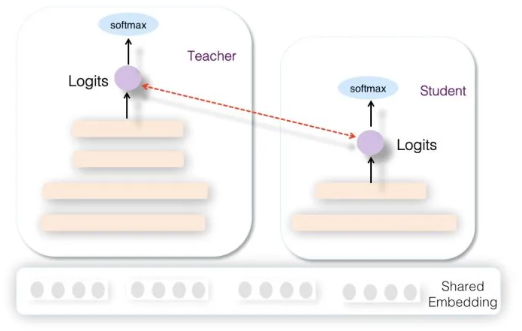
目前推荐领域里,在精排环节采用知识蒸馏,主要采用Teacher和Student联合训练(Joint Learning)的方法,而目的是通过复杂Teacher来辅导小Student模型的训练,将Student推上线,增快模型响应速度。
从网络结构来说,Teacher和Student模型共享底层特征Embedding层,Teacher网络具有层深更深、神经元更多的MLP隐层,而Student则由较少层深及神经元个数的MLP隐层构成,两者的MLP部分参数各自私有对于所有训练数据,会同时训练Teacher和Student网络。
- 对于Teacher网络,就是常规的训练过程,以
交叉熵作为Teacher的损失函数。 - 对于Student网络,损失函数由两个部分构成,一个子项是
交叉熵,另外一个子项是使Student输出的Logits去拟合Teacher输出的Logits。
阿里妈妈团队在论文《Rocket Launching: A Universal and Efficient Framework for Training Well-performing Light Net》中提出其要点有三:
- 两个模型同时训练;
- Teacher和Student共享特征Embedding;
- 通过Logits进行知识蒸馏。
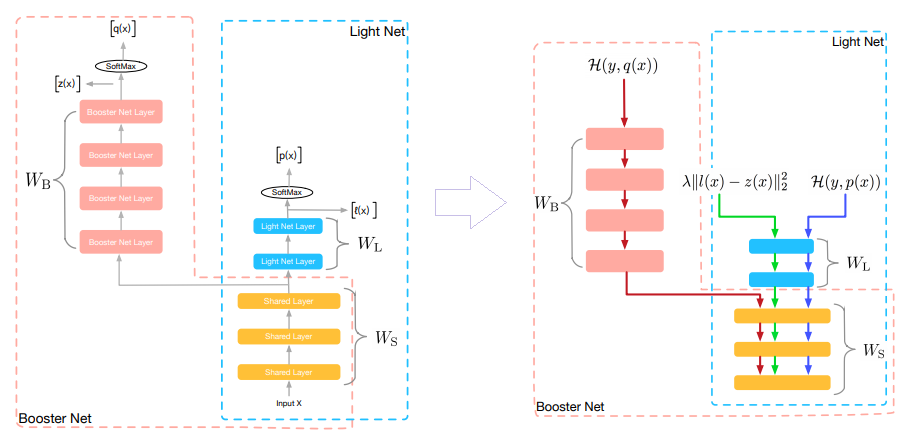
爱奇艺团队在排序阶段提出了双DNN排序模型,可以看作是在阿里的rocket launching模型基础上的进一步改进。
Student和Teacher共享特征Embedding参数层,Student模型在损失函数中加入了拟合Teacher输出阶段的Logits子项,这两点和rocket launching是类似的。
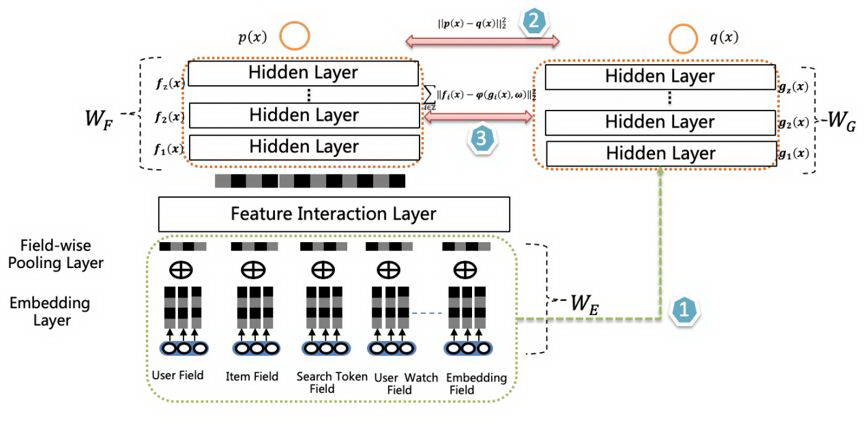
主要改进有两点:
- 为了进一步增强student的泛化能力,要求student的隐层MLP的激活也要学习Teacher对应
隐层的响应,这点同样可以通过在student的损失函数中加子项来实现。 - 双DNN排序模型的Teacher在特征Embedding层和MLP层之间,可以比较灵活加入各种
不同方法的特征组合功能,通过这种方式,体现Teacher模型的较强的模型表达和泛化能力。
爱奇艺给出的数据对比说明了,这种模式学会的student模型,线上推理速度是Teacher模型的5倍,模型大小也缩小了2倍。Student模型的推荐效果也比rocket launching更接近Teacher的效果,这说明改进的两点对于Teacher传授给Student更强的知识起到了积极作用。
召回/粗排蒸馏
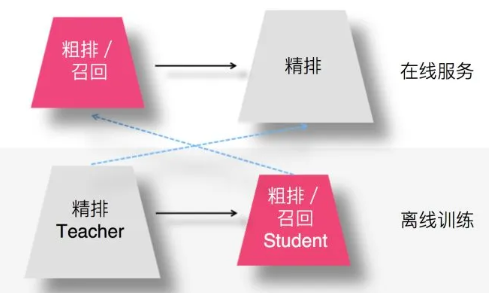
用复杂的精排模型作为Teacher,召回或粗排模型作为小的Student,比如FM或者双塔DNN模型等,Student模型模拟精排环节的排序结果,以此来指导召回或粗排Student模型的优化过程。
- Student经过复杂精排模型的知识蒸馏,所以
效果可以非常接近于精排模型效果; - Student模型
结构简单,所以速度快,满足这两个环节对于速度的要求; - 通过Student模型模拟精排模型的排序结果,可以使得前置两个环节的优化目标和推荐任务的最终
优化目标保持一致。
这里需要注意的一点是:
- 如果召回模型或者粗排模型的优化目标已经是多目标的,对于新增的模型蒸馏来说,可以作为
多目标任务中新加入的一个新目标; - 也可以只保留单独的蒸馏模型,
完全替换掉之前的多目标模型。
一种直观的想法是:我们基本可以直接参照rocket launching的方案稍作改动即可。
对于粗排或者召回模型来说,一般大家会用DNN双塔模型建模,只需要将粗排或召回模型作为Student,精排模型作为Teacher,两者联合训练,要求Student学习Teacher的Logits,同时采取特征Embedding共享。
如此这般,就可以让召回或粗排模型学习精排模型的排序结果。
快手团队曾经在AICon分享过在粗排环节采取上面接近rocket launching的蒸馏技术方案,并取得了效果。
因双塔结构将用户侧和物品侧特征分离编码,所以类似爱奇艺技术方案的要求Student隐层学习Teacher隐层响应,是很难做到的。粗排尚有可能,设计简单网络DNN结构的时候不采取双塔结构即可,召回环节几无可能,除非把精排模型也改成双塔结构,可能才能实现这点,但这样可能会影响精排模型的效果。
但是,问题是:有必要为了训练召回或粗排的蒸馏模型,去联合训练精排模型么?貌似如果这样,召回模型对于排序模型耦合得过于紧密了,也有一定的资源浪费。其实我们未必一定要两者联合训练,也可以采取更节省成本的两阶段方法。
两阶段方案
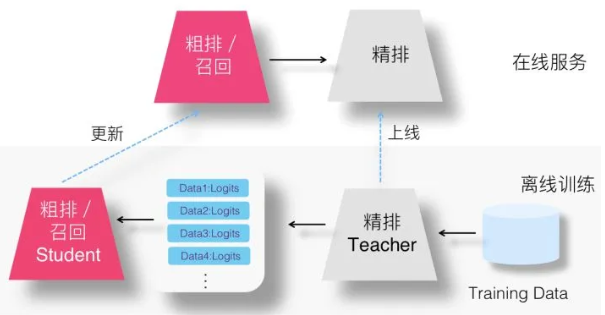
在专门的知识蒸馏研究领域里,蒸馏过程大都采取两阶段的模式。
- 第一阶段先训练好Teacher模型;
- 第二阶段是训练Student的过程,在Student训练过程中会使用训练好Teacher提供额外的Logits等信息,辅助Student的训练。
但事实上,很可能我们手上的召回模型或粗排模型已经是多目标的了,那么这种情况下,其实蒸馏Student模型就没有太大必要带Ground Truth优化目标,因为多目标已经各自做了这个事情了。这种情况下,独立优化蒸馏目标,然后将其作为多目标的一个新目标加入召回或粗排模型比较合适。
Logits方案
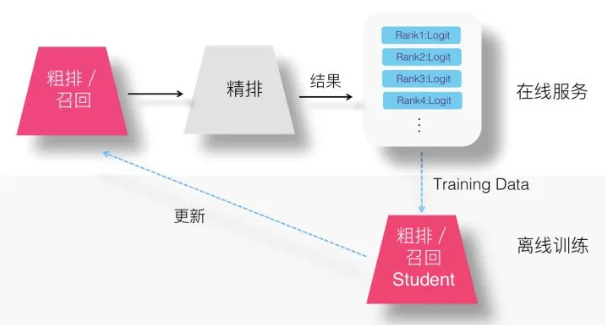
在召回或者精排采用知识蒸馏,此时精排模型其实身兼二职:
- 主业是做好线上的精准排序
- 副业是顺手可以教导一下召回及粗排模型。
所以,其实我们为了让Teacher能够教导Student,在训练Student的时候,并不需要专门训练一遍Teacher精排模型,因为它就在线上跑着呢。 而且我们抛开了Ground Truth优化子目标,所以不需要Teacher对训练数据都过一遍,而只需要多做一件事情:
- 线上精排模型在输出排序结果的时候,对于当前判断<User,Item,Context>实例,除了给出是否点击等判断外,只要把对应优化目标的Logits数值输出,并计入Log即可。
这样,召回或粗排模型可以直接使用训练数据中记载的Logits,来作为Student的训练数据,训练蒸馏模型。
Without-Logits方案
另外一类方法可以进一步减少Student对Teacher的依赖,或适用于无法得到合理Logits信息的场合。
这时,精排模型仍然是Teacher,只是传给召回或粗排模型的知识不再是Logits,而是一个·有序的列表排序结果,我们希望Student从这个排序结果里面获取额外的知识(让Student模型完全拟合精排模型的排序结果)。
如果这样的话,对于目前的线上推荐系统,不需要做任何额外的工作,因为排序结果是会记在Log里的
(也可以用推荐系统在精排之后,经过Re-ranker重排后的排序结果,这样甚至可以学习到一些去重打散等业务规则),
只要拿到Log里的信息,我们就可以训练召回或粗排的Student蒸馏模型。
很明显,这是一个典型的Learning to Rank问题。我们知道,对于LTR问题,常见的优化目标包括三种:Point Wise、Pair Wise和List Wise。于是,我们可以按照这三种模式来设计召回模型或粗排模型的蒸馏学习任务。
1、Point Wise蒸馏
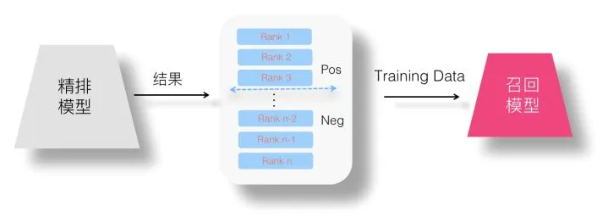
2、Pair Wise蒸馏
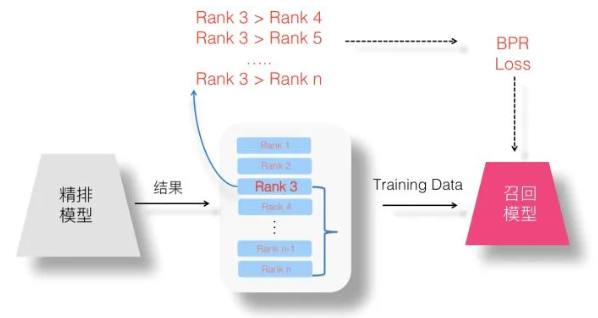
3、List Wise蒸馏
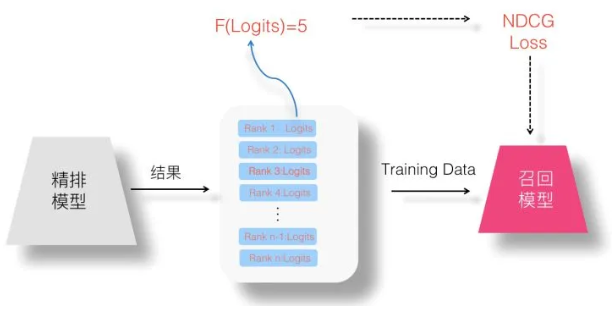
以上三种方法原文有叙述,这里不再重复。
结束语
实际情况是,业务量小的时候没必要上两阶段模型,业务量大的时候召回和精排分属不同组,互相合作是个问题,毕竟这种方法下精排训练结果直接影响粗排的训练…