Last updated on 2020-06-08…
理解用户是搜索排序中一个非常重要的问题,工业级的推荐系统一般需要大量的泛化特征来较好的表达用户。这些泛化特征可以分为两类:
- 偏
静态的特征,例如用户的基本属性(年龄、性别、职业等等)特征、长期偏好(品类、价格等等)特征; 动态变化的特征,例如刻画用户兴趣的实时行为序列特征。
用户的实时行为特征能够明显加强不同样本之间的区分度,所以在模型中优化用户行为序列建模是让模型更好理解用户的关键环节。
推荐系统中的用户兴趣变化非常剧烈,比如电商推荐中,用户一会看看服饰,一会看看电子产品,若只使用静态特征进行推荐,每次推荐的内容是一样的,这无疑是不能满足用户需求,实时性需要保障。
大致来讲,用户行为序列建模包含以下几种方式:
Pooling方法;特点是将用户历史行为看做一个无序集合,方法有sum/max pooling等;Attention模型:属于Pooling方法的一种,优点在于灵活的捕捉全局和局部的联系,方法有DIN、DIEN、DSIN、BST等;序列模型:将用户行为看做一个具有时间属性的序列,方法有RNN、LSTN、GRU等;- 关注用户的
多兴趣表达:方法有MIND等; - 结合业务场景的其他方法。
非序列的Pooling方法
pooling方法对用户行为序列中的 item 进行 Sum-pooling 或者 Mean-pooling 后的结果来表达用户的兴趣,
这种方法假设所有行为内的 item 对用户的兴趣都是等价的(实际上用户点过的item对任务的贡献度是不同的),
因而会引入一些噪声。尤其是复杂一点的交互场景中,这种假设往往是不能很好地进行建模来表达用户兴趣。
2016年Google团队在《Deep Neural Networks for YouTube Recommendations》中提出了 Deepmatch 和 Deep ranking model 结构,将用户观看过的视频序列取到embedding后,做了一个mean pooling作为用户历史兴趣的表达。
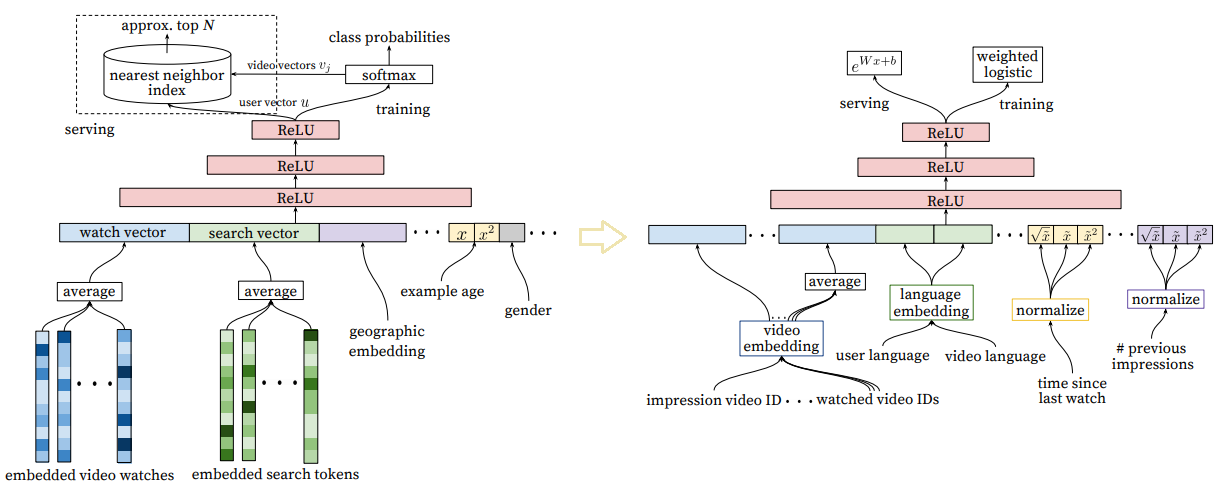
这种方式比较简单,但是简洁好用。通常情况下可以作为一个baseline。
Attention方法
往期相关传送门:《深度兴趣演化网络 DIEN》、《深度会话兴趣网络 DSIN》
近年来,在搜索推荐算法领域,针对用户行为序列建模取得了重要的进展:
- DIN 引入注意力机制,考虑行为序列中不同 item 对当前预测 item 有不同的影响;
- DIEN 将网络分为兴趣提取层和兴趣演化层,解决了 DIN 无法捕捉用户兴趣动态变化的缺点;
- DSIN 针对 DIN 和 DIEN 没有考虑用户历史行为中的 Session 信息,因为每个 Session 中的行为是相近的,而在不同 Session 之间的差别很大,它在 Session 层面上对用户的行为序列进行建模;
- BST 模型通过 Transformer 模型来捕捉用户历史行为序列中的各个 item 的关联特征,与此同时,加入待预测的 item 来达到抽取行为序列中的商品与待推荐商品之间的相关性。
Transformer应用模型的主要构成:
- 所有特征(user 维度、item 维度、query 维度、上下文维度、交叉维度)经过底层 Embedding Layer 得到对应的 Embedding 表示;
- 建模用户行为序列得到用户的 Embedding 表示;
- 所有 Embedding concat 一起送入到三层的 MLP 网络。
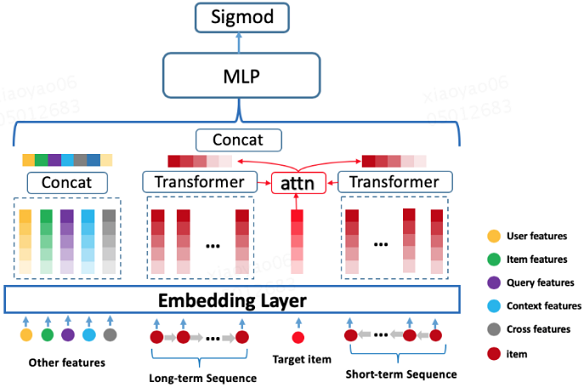
输入部分:
- 分为短期行为序列和长期行为序列。
- 行为序列内部的每个行为原始表示是由商户 ID,以及一些商户泛化信息的 Embedding 进行 concat 组成。
- 每段行为序列的长度固定,不足部分使用零向量进行补齐。
输出部分:
- 对 Transformer Layer 输出的向量做 Sum-pooling (这里尝试过Mean-pooling、concat,效果差不多)得到行为序列的最终 Embedding 表示。
这里存在一个问题,对所有的 item 打分的时候,用户的 Embedding 表示都是一样的。
- 参考 BST 引入
Target-item,这样可以学习行为序列内部的 item 与 Target-item 的相关性,这样在对不同的 item 打分时,用户的 Embedding 表示是不一样的; - 叠加 DIN 模型里面的
Attention-pooling机制。
序列建模方法
这类方法将用户行为看做一个序列,套用NLP领域常用的RNN/LSTM/GRU方法来进行建模。
可以参考的论文有GRU4REC,将seesion中点击item的行为看做一个序列,使用GRU进行刻画。知乎上有作者的亲自解读,这里不再重复。
阿里搜索团队使用RNN类方法建模用户行为序列的文章是《Perceive Your Users in Depth: Learning Universal User Representations from Multiple E-commerce Tasks》。比较有意思的是这篇paper提出了一种Property Gated LSTM方法。
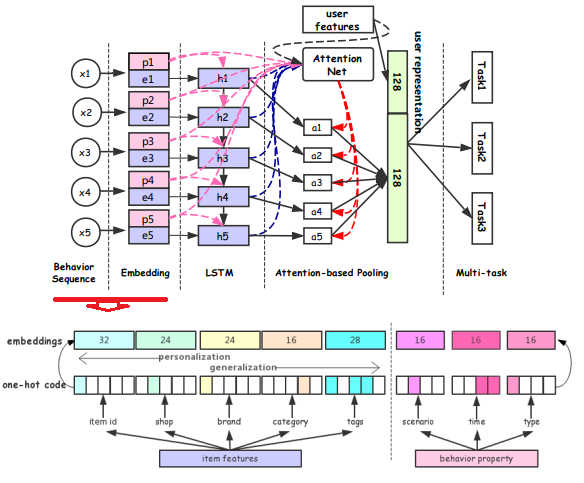
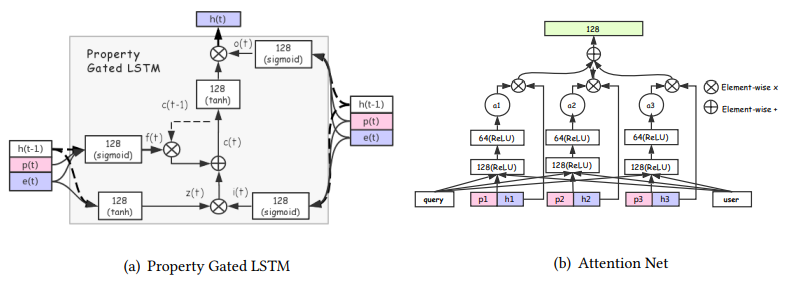
其通过多任务学习的方式学到一个较为通用的用户表征。具体来说,模型将用户行为序列中的每个行为xi分成商品信息item_i(item id、shop id、brand id)和行为属性property_i(场景、时间等上下文),经过embedding层得到embedding后,经过一个Property Gated LSTM层后,得到每个行为节点的隐状态,使用attention网络对隐状态进行加权,然后和user profile feature concat后作为输出。
多兴趣表达
在前面的方法中,基本上都遵循着这样的范式:将用户行为序列经过pooling/attention/rnn的处理,聚合成一个用户行为序列的embedding, 然后加入其它的特征embedding concat后,再经过几层的mlp后作为接sigmode(排序任务)或者softmax/sampled softmax(召回任务)。
事实上,用户行为序列里,通常包含着用户的多峰兴趣。每个用户的历史行为长度不一样,用户的兴趣数量也不同,能不能将用户行为抽取/聚合成多个兴趣,并且表示为不同的embeding呢?
阿里首猜团队在2019年提出的MIND方法,巧妙的使用胶囊网络中的动态路由算法,将底层的用户行为序列作为”vector in”,上层“vector out”的胶囊作为用户多峰兴趣。
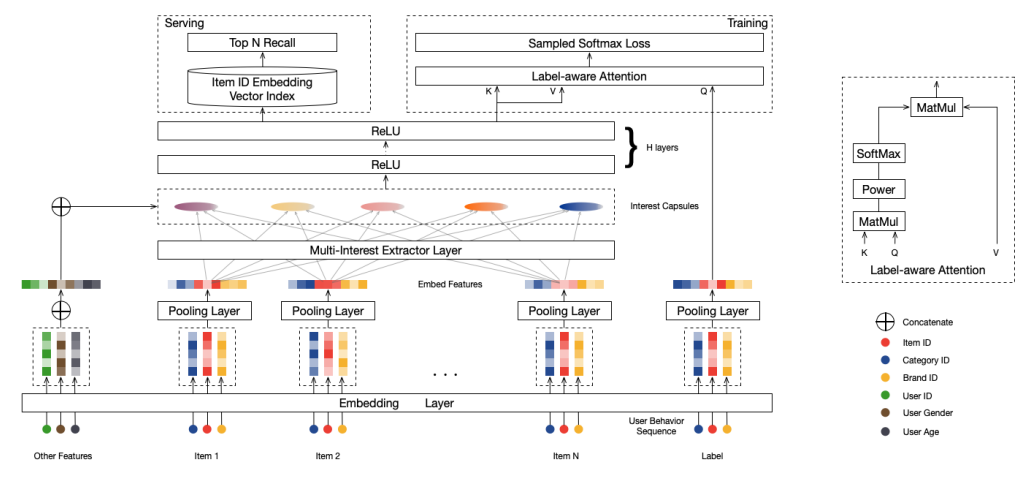
MIND中比较有意思的一些点,是不管用什么方式抽取多兴趣都可以借鉴的:
- 自适应的兴趣数量设置:作者设置了K个兴趣上限,然根据用户行为数量公式来调整实际抽取出的兴趣数量。
- 使用Label-aware Attention Layer:训练时,将用户下一个点击的item作为query,而不同的用户兴趣作为key和value,做一个attention,并且可以通过超参p来对attention分布进行控制。而在线上,每个用户兴趣向量分开进行召回。
《揭开迷雾,来一顿美味的Capsule盛宴》、《再来一顿贺岁宴:从K-Means到Capsule》、《三味Capsule:矩阵Capsule与EM路由》
其他
我们在做推荐系统时,面临不同业务场景,不同优化的阶段,常常面临不同的问题,这时候也有一些有趣的解法。
电商推荐中,我们看用户行为序列的case时,发现用户的兴趣常常可以按照session来进行切割,DSIN 这篇论文发现了这一点,将用户行为序列按照30分钟的间隔进行切割。阿里妈妈定向广告团队发现仅仅提升用户序列的长度,就可以带来可观的auc提升,为了建模超长行为序列,提出MIMN方法,设计了UIC(User Interest Center)模块,将用户兴趣表达模块单独进行拆分而不是每次请求进行计算。微信看一看召回中,存在多种异构行为序列的信息可以利用(比如可以用腾讯新闻、电商购物行为等等)。作者得到特征域的用户行为序列表达后,使用attention的方法替换concat的方法,动态调整不同领域的融合权重。
结束语
关注推荐系统相关论文时,应着重注意作者在实验部分是否指出其方法在真实业务中上线。
- 如果上线了说明起码在那个场景是效果可以的;
- 如果没上线那就是toy example,发论文玩玩的,比如bert4rec…
在真实场景中简单策略往往就可以拿到很不错的效果,但是如果在有论文kpi的部门,就要包装成模型方法论…