Last updated on 2019-5-21…
KDD 2018 Best Paper《Real-time Personalization using Embeddings for Search Ranking at Airbnb》
业务形态
Airbnb作为全世界最大的短租网站,提供了一个连接房主(host)挂出的短租房(listing)和主要是以旅游为目的的租客(guest/user)的中介平台。这样一个中介平台的交互方式比较简单,guest输入地点,价位,关键词等等,Airbnb会给出listing的搜索推荐列表。
Airbnb上预订是双向选择的过程:客户如果想预订房源,还要看房东是否同意。
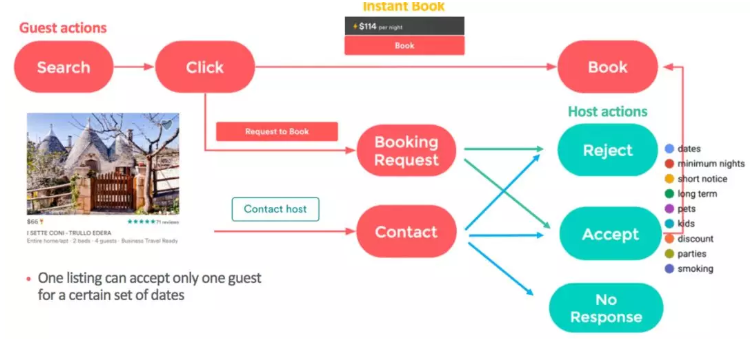
总之,guest和host之间的交互方式有以下几种:
- guest点击listing (click)
- guest预定lising (book)
- host有可能拒绝guest的预定请求 (reject)
为了进行更加准确的排序,Airbnb的搜索团队建立了一个Real-time实时的个性化排序模型,既考虑用户的短时兴趣,也考虑用户的长期兴趣。
短时兴趣指用户在一个session中表现出的兴趣(点击序列)长期兴趣指用户在其所有历史行为中表现出的兴趣(预订序列)
在模型中,其精髓就在于Embedding的过程,包括Listing Embedding、User Type & Listing Type Embedding。
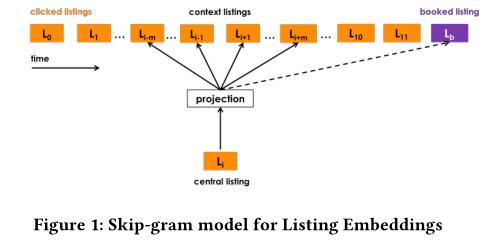
Listing Embedding
对房源进行Embedding,可以建模用户的短时兴趣,也可以进行相似房源的推荐。它通过用户在Session中的点击序列训练得到,这里的session定义要注意以下两点:
- 一个是只有停留时间超过30s的listing page才被算作序列中的一个数据点
- 二是如果用户超过30分钟没有动作,那么这个序列会断掉,不再是一个序列。
作用:清洗噪声点和负反馈信号,同时避免非相关序列的产生
方法借鉴Skip-Gram,原目标函数:
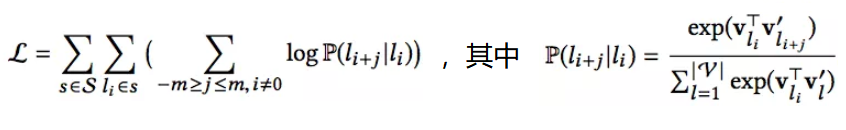 这里,V是所有的房源的集合,vl是房源的输入向量,而vl‘是房源的输出向量。
这里,V是所有的房源的集合,vl是房源的输入向量,而vl‘是房源的输出向量。
因为数据量很大,所以此时采用负采样的方法,即随机选择一小部分作为负样本。优化的目标函数变为:
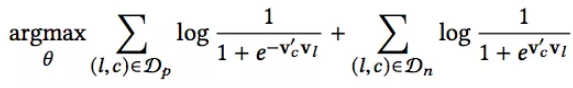 其中Dp代表的是正样本的集合,Dn代表的是负样本的集合
其中Dp代表的是正样本的集合,Dn代表的是负样本的集合
trick1: Booked Listing as Global Context
在所有的训练用的Session中,有一部分发生了预订行为,我们称之为booked sessions,有一些没有发生预订行为,我们称之为exploratory sessions。
对于booked sessions,无论最终预订的房源是否在Skip-Gram的窗口内,都将其放入到目标函数中。这么做出于这样的考虑:无论当前窗口是否包含预订的房源,被预订的房源都是与当前的中心房源是有关联的。
此时的目标函数变为:
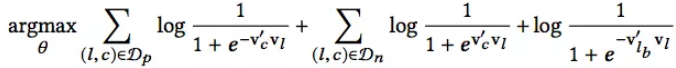 对于exploratory sessions,不做任何特殊的处理。
对于exploratory sessions,不做任何特殊的处理。
trick2: Adapting Training for Congregated Search
用户在出行的时候,都是有明确的目的地的(文中的用词是market,目的地只是market的一个特例)。
这样,我们在选择负样本的时候,在随机选择的基础上,可以加一批同目的地的房源负样本,记做Dmn。此时的目标函数变为:
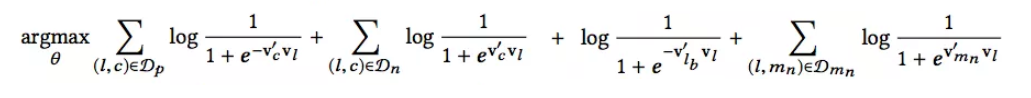
冷启动问题
对于新加入的房源,训练数据中是没有它的记录的,也就是无法训练得到其Embedding。
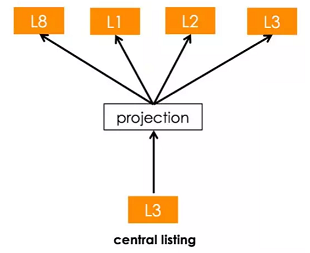
文中的做法是,从已有的得到embedding的房源中,选择3个同种类(种类会在下一节介绍)且距离最近(但是要在半径10miles以内)的3个房源,并用其embedding的平均值来作为新房源的embedding。98%的新房源都可以通过这种方式来获得相应的embedding。
User Type & Listing Type Embedding
用户在一个session内表现出的兴趣我们可以称为短时兴趣,但在推荐时,用户的长期兴趣有时候也很重要。比如用户正在洛杉矶找房源,那么便可以根据其之前在纽约预订过的房源信息来进行推荐。
尽管我们可以通过上面得到的房源embedding,可以捕获到不同城市之间房源的相关性信息,但是更加通用的做法是通过不同用户在不同城市的预订行为,来学习不同城市房源的相似性。
预订数据的特点:
- 预订序列数据相比于点击序列数据,是非常少的
- 许多用户只有过一次预订行为,这种的session是不能拿来用的
- 为了学习一个比较有效的embedding,房源至少要出现5-10次,但是有许多房源无法达到这样的标准(所以需要把房源进行归类,学习每一类房源的embedding)
- 如果序列中两次预订的时间间隔过长的话,用户的偏好是会发生改变的(所以需要把用户type考虑进来)
此时预订序列变为:
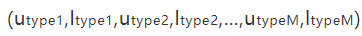
对房源和用户的归类规则如下:
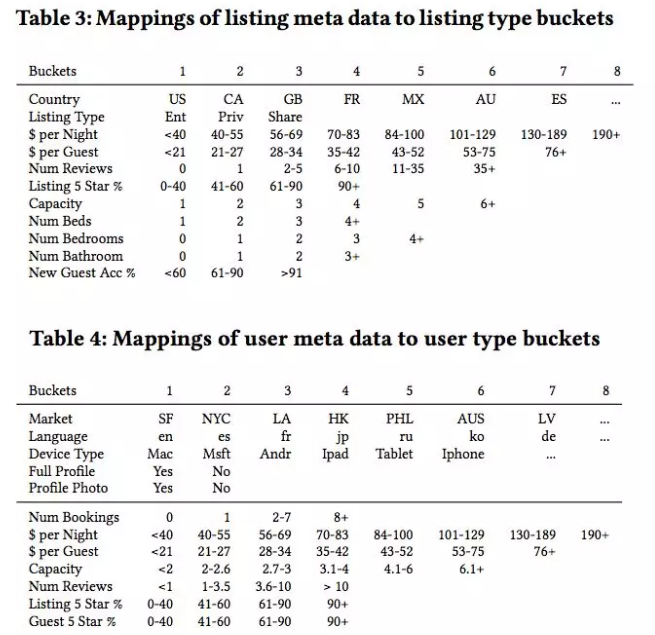 在表4用户类别里,中间是画了一条线的。如果一个用户没有过预订行为,其类别只用上面五行表示,如果有预订行为,则用所有的行表示。
在表4用户类别里,中间是画了一条线的。如果一个用户没有过预订行为,其类别只用上面五行表示,如果有预订行为,则用所有的行表示。
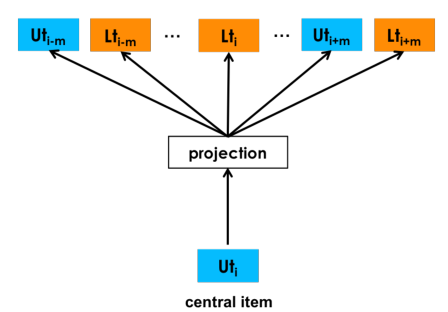
对预定序列用skip-gram进行训练:
-
当中心是一个user-type时,目标函数如下:
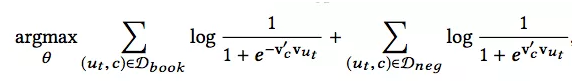
-
当中心是一个listing-type时,目标函数如下:
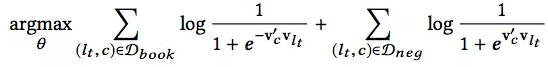
user-type和listing-type得到的embedding是属于同一空间的,可以直接来计算相似度!
显式的负样本
在Airbnb上,房东是可以拒绝用户的预订申请的,我们还想把这部分信息放进去,这部分就是显式的负样本:
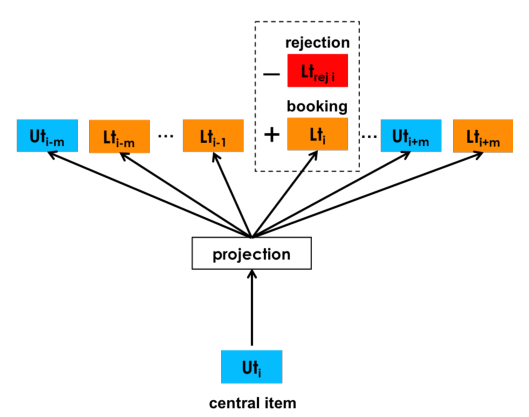
-
当中心是一个user-type时,目标函数如下:
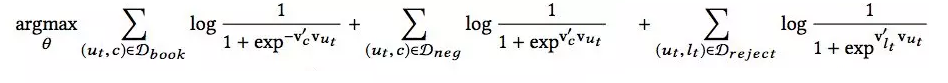
-
当中心是一个listing-type时,目标函数如下:
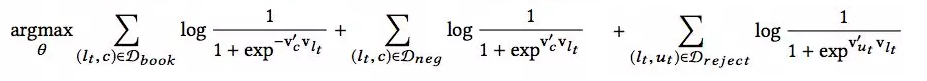
其他外企相关论文
[AAAI 2018]StarSpace: Embed All The Things! |
|
[Slideshare 2017]Deep Learning for Personalized Search and Recommender Systems |
|
[ICTAI 2017]Language Modelling for Collaborative Filtering: Application to Job Applicant Matching |
|
| Yahoo | [SIGKDD 2015]E-commerce in your inbox: Product recommendations at scale |
| Yahoo | [SIGKDD 2016]Scalable semantic matching of queries to ads in sponsored search advertising |
| Yahoo | [SIGKDD 2016]Ranking relevance in yahoo search |
| Etsy | [Arxiv 2016]An Ensemble-based Approach to Click-Through Rate Prediction for Promoted Listings at Etsy |
| Criteo | [Arxiv 2017]Specializing Joint Representations for the task of Product Recommendation |
| Tinder | [Slideshare 2017]Personalized Recommendations at Tinder: The TinVec Approach |
| Tumblr | [SIGKDD 2015]Gender and interest targeting for sponsored post advertising at tumblr |
| Instacart | [Slideshare 2017]Learned Embeddings for Search at Instacart |