Last updated on 2020-11-1…
结合百度和支付宝两段推荐系统相关的实习经历,本篇针对 工业界的模型发展 做了简单梳理与回顾。
表示学习和深度学习在推荐系统中的应用是目前工业界比较成熟的,但是与强化学习、知识图谱、多任务学习相结合是比较少的,
一方面此类技术与推荐结合才刚刚开始探索,背后有太多问题需要人力去挖掘和探索;另一方面在公司的业务中敢不敢上这种前沿课题的探索与实验甚至上线接大流量,部门老大的魄力很关键。
本篇之外,部分知名外企发表的相关应用论文整理在《Airbnb实时搜索排序》的文末。
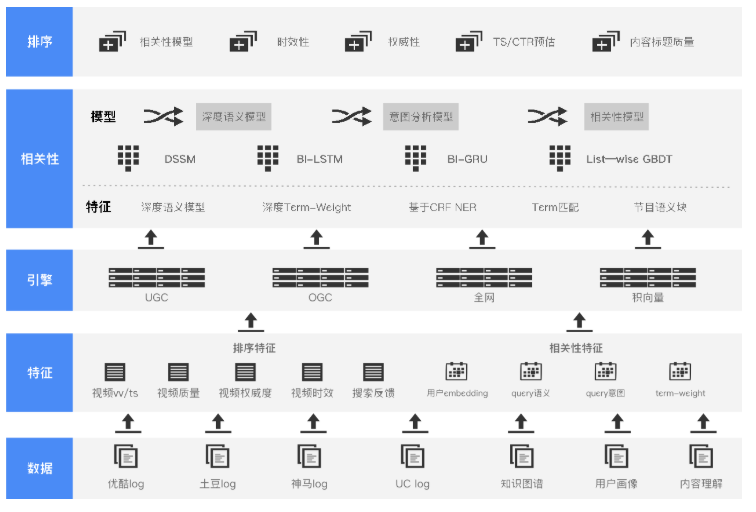
表示学习
常用类别特征的表示方法:One-Hot Encoding、Look-Up Embedding、Pre-Train Embedding
框架
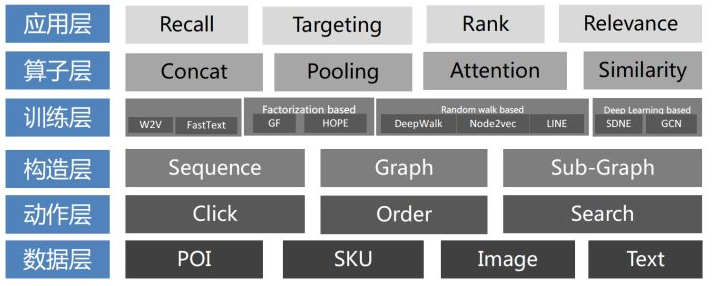
序列 Sequence
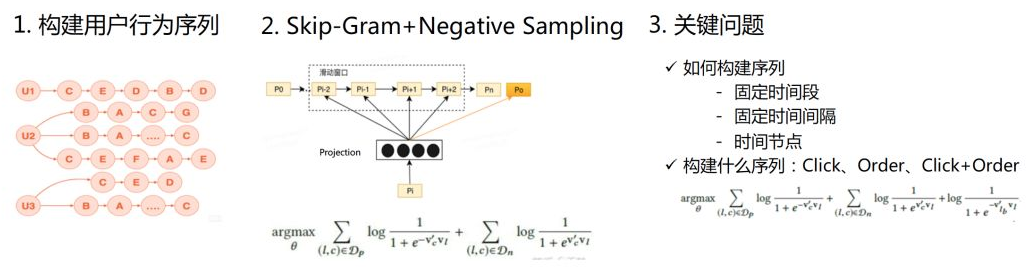
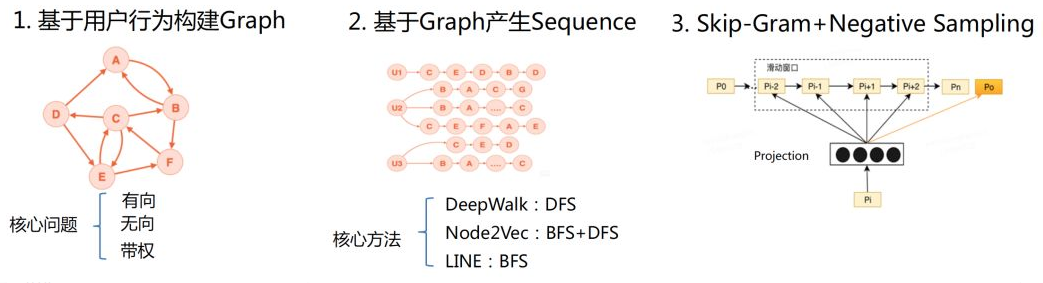
图 Graph
附加信息 Side Information
Side Information框架是解决冷启动的方法之一。

多模态 Multimodal
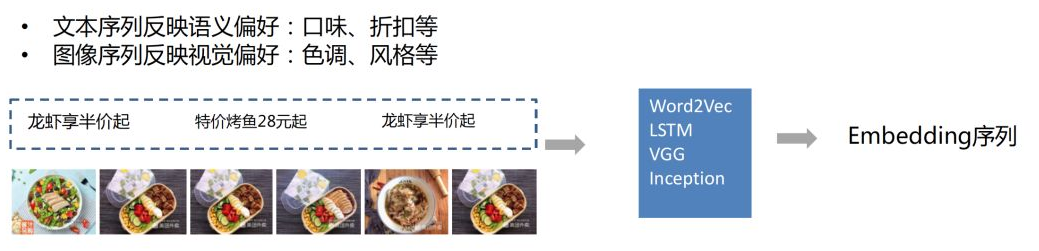
更准确来说,这部分属于模式识别范畴,各大公司在业务稳定后基本都会成立单独的内容理解团队,以分享到外部的资料举例,优酷团队在这方面做的很不错:《优酷在多模态内容理解上的研究及应用》。
深度学习

企业级的推荐系统为了尽量提高模型的准确性,往往会使用丰富的甚至异构的内容数据。这些特征从不同的维度展现了不同的信息,而且特征间的组合通常是非常有意义的。传统的交叉特征是由工程师手动设计的,这有很大的局限性,成本很高,并且不能拓展到未曾出现过的交叉模式中。因此学者们开始研究用神经网络去自动学习高阶的特征交互模式,弥补人工特征工程带来的种种局限性。
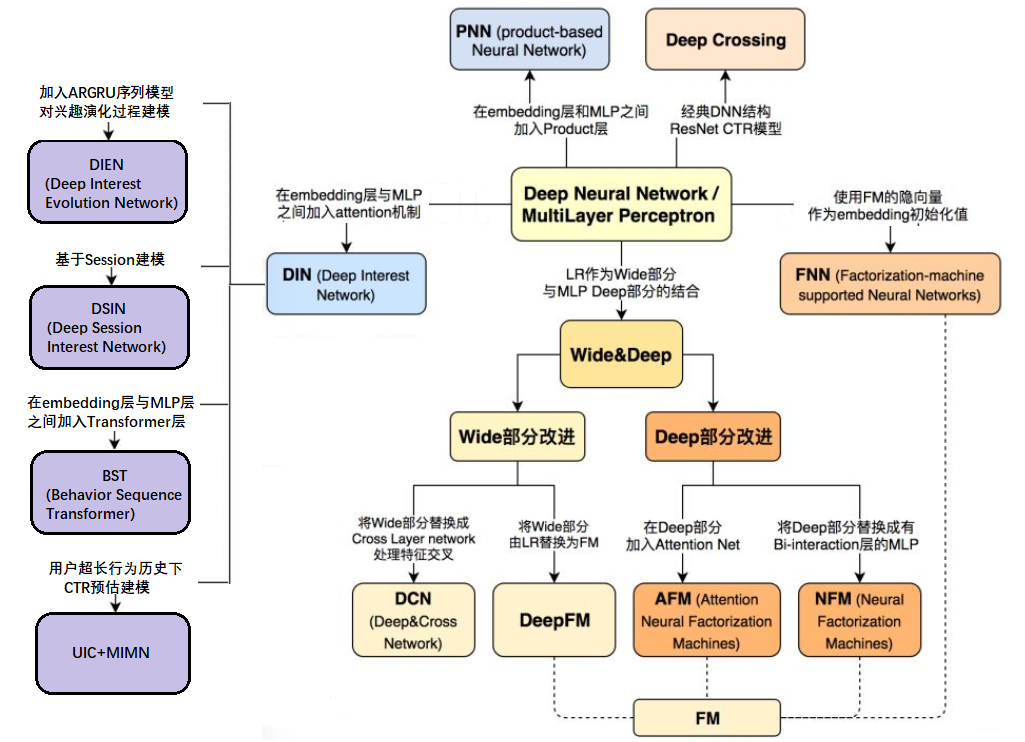
2015-2016
| CCPM | [CIKM 2015]A Convolutional Click Prediction Model |
| FNN | [ECIR 2016]Deep Learning over Multi-field Categorical Data: A Case Study on User Response Prediction |
| PNN | [ICDM 2016]Product-based neural networks for user response prediction |
| Wide & Deep | [DLRS 2016]Wide & Deep Learning for Recommender Systems |
2017-2018
2018-2019
自动特征工程方面我即将出一篇论文,期待下~
强化学习
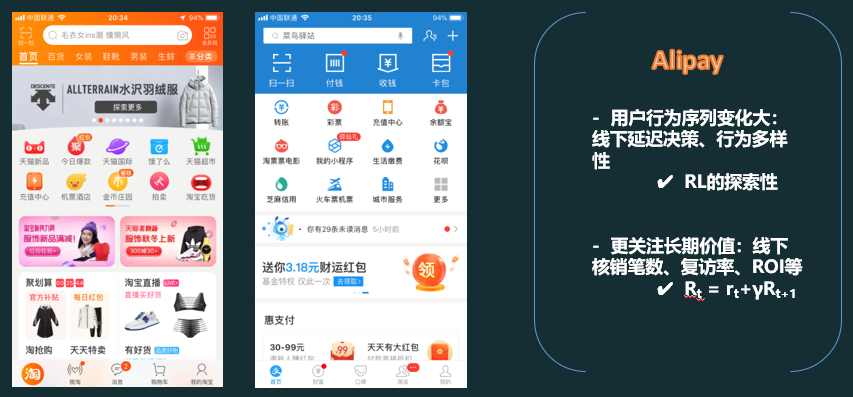
用户与推荐系统之间往往会发生持续密切的交互行为,强化学习中的Reward机制十分适合应用到这种模式,所以基于强化学习的推荐方法中,往往会把推荐系统看做智能体(Agent)、把用户看做环境(Environment),商品的推荐问题可以看做经典的顺序决策问题。Agent每一次排序策略的选择可以看做一次试错(Trial and Error),把用户的反馈、点击成交等作为从环境中获得的奖赏(Exploration & Exploitation)。
在支付宝实习的时候,优化CTR模型之余,针对商家线下运营策略推荐场景,主导实现了off-policy的强化学习模型。(下图仅作抛砖引玉,模型细节不能公布哈)
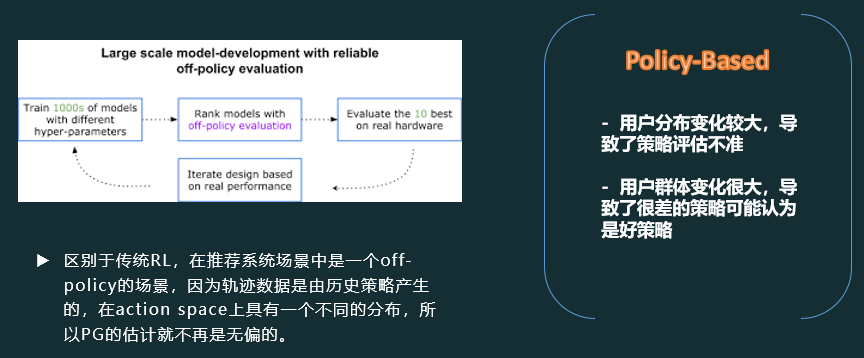
2018-2019
机遇与挑战
- 离线评估与在线效果之间的巨大鸿沟
- 离线模拟过程的泛化性问题,特别是用户端连续决策行为的建模方面。
- 现有方法其实还是有很多问题,例如没有刻画用户反馈行为的连续性与前后相关性、没有考虑用户反馈背后的多因素影响等等。
- 动作空间偏大
- 在真实的推荐系统中面临巨大无比的离散化行为空间(待推荐item集合巨大无比)。
- TPGR模型在这个问题上已经作出了一些探索,但还没有完全解决这类问题。
- 在线效果容易受到其它策略的影响
- 例如推荐端在使用RL算法,用户还在看到很多其它推荐、展示策略在其它位置、时段、平台推给他的结果,较难精确建模用户反馈与行为归因。
- 如何去做更好地探索
- 因为真实场景中没有游戏环境那样丰富的样本数据,每一次探索都有巨大的显性成本或隐性成本。
- 更快地探索、更好地采用效率是RL4Rec实际应用中的难题。
知识图谱
Personalized Recommendation Systems: Five Hot Research Topics You Must Know
在多数推荐场景中,物品可能包含丰富的知识信息,而刻画这些知识的网络结构即被称为知识图谱。物品端的知识图谱极大地扩展了物品的信息,强化了物品之间的联系,为推荐提供了丰富的参考价值,更能为推荐结果带来额外的多样性和可解释性。
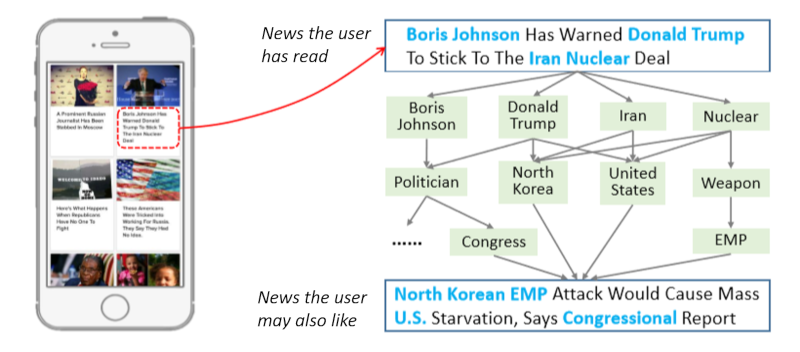
和社交网络相比,知识图谱是一种异构网络(一般由三元组 < 头节点,关系,尾节点 > 组成),因此针对知识图谱的推荐算法设计要更复杂和精巧。
引入网络特征学习的方法处理推荐系统中知识图谱的相关信息,有助于增强推荐系统的学习能力,提高精确度和用户满意度。
将知识图谱引入推荐系统,主要有以下两种不同的处理方式:
- 基于特征的辅助推荐模型:核心是知识图谱特征学习的引入。即首先使用知识图谱特征学习对其进行处理,从而得到实体和关系的低维稠密向量表示。这些低维的向量表示可以较为自然地与推荐系统进行结合和交互。
- 基于结构的全局推荐模型:更加直接地使用知识图谱的结构特征。具体来说,对于知识图谱中的每一个实体,我们都进行BFS来获取其在知识图谱中的多跳关联实体从中得到推荐结果。
2018-2019
机遇与挑战
- 现有模型都属于统计学习模型,即挖掘网络中的统计学信息并以此进行推断
- 一个困难但更有研究前景的方向是在网络中进行推理,将
图推理与推荐系统相结合。
- 一个困难但更有研究前景的方向是在网络中进行推理,将
- 如何设计出性能优秀且运行效率高的算法,也是潜在的研究方向
- 现有模型并不涉及
计算引擎层面、系统层面甚至硬件层面的考量,如何将上层算法和底层架构进行联合设计和优化,是实际应用中一个亟待研究的问题。
- 现有模型并不涉及
- 现有的模型网络结构都是静态的,在真实场景中,知识图谱具有一定的时效
- 如何刻画这种时间演变的网络,并在推荐时充分
考虑时序信息,也值得我们未来研究。
- 如何刻画这种时间演变的网络,并在推荐时充分
在工业界中,一方面构建一张图需要花费巨大的人力;另一方面图采样等相关技术还不成熟(暴力地使用GCN、KGAT并不现实)。 据目前我所了解到的,在知识图谱工业级应用方面,谷歌和百度是比较前沿的(重视程度源于索引量大且对query质量要求高时的场景需求)。
多任务学习
我们在优化推荐效果的时候,很多时候不仅仅需要关注 CTR 指标,同时还需要优化例如 CVR ( 转化率 )、视频播放时长、用户停留时长、用户翻页深度、关注率、点赞率这些指标。
那么一种做法是对每个任务单独使用一个模型来优化,但是这样做的缺点显而易见,需要花费很多人力。其实很多任务之间都是存在关联性的,比如 CTR 和 CVR。
那么能不能使用一个模型来同时优化两个或多个任务呢?其实这就是 Multi-task 多任务的定义。
具体一点地说,当我们完成召回阶段之后,有了可供推荐的候选 Item,然后从数据库中获取 User 和 Item 特征(特征缓存),从参数服务器获取模型参数(权重缓存),就可以进行预估。
这里假定淘宝有五个预估目标,分别是点击率 CTR、购买转化率 CVR、收藏率 collect,加购率 cart、停留时长 stay,这五个目标分别对应五个模型,粗排阶段的作用就是利用模型根据各自目标来给候选 Item 计算一个预估值(分数),排序阶段结束每个 Item 都会有五个不同的目标预估分数,如何用这些分数,是交给下一个流程来处理的。
精排阶段有两个主要作用,一个是融合,也就是将排序阶段传递来的多个目标分数进行融合,形成一个分数,另外一个是约束,也就是规制过滤。
2018-2019
以上部分论文是有理论缺陷的,需仔细甄别。
总结与思考
多任务学习的定义中,有两个非常关键的限定,也是多任务得以实现的前提条件:多个任务之间必须具有相关性以及拥有可以共享的底层表示。(当多个任务的相关性没那么强时,这些任务之间就会相互扰乱,从而影响最后的效果)
共享表示对于最终任务的学习有两类作用:
- 促进作用:通过浅层的共享表示互相分享、互相补充学习到的领域相关信息,从而互相促进学习,提升对信息的穿透和获取能力;
- 约束作用:在多个任务同时进行反向传播时,共享表示则会兼顾到多个任务的反馈,由于不同的任务具有不同的噪声模式,所以同时学习多个任务的模型就会通过平均噪声模式从而学习到更一般的表征。(这个有点像正则化的意思,因此相对于单任务,过拟合风险会降低,泛化能力增强)
执行多任务学习的两种最常用的方法:
- 参数的硬共享机制(基于参数的共享,Parameter Based)
共享 Hard 参数是神经网络 MTL 最常用的方法。在实际应用中,通常通过在所有任务之间共享隐藏层,同时保留几个特定任务的输出层来实现,如下图所示:
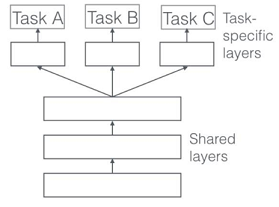 这种方法大大降低了过拟合的风险。这很直观:我们同时学习的工作越多,我们的模型找到一个含有所有任务的表征就越困难,而过拟合我们原始任务的可能性就越小。
这种方法大大降低了过拟合的风险。这很直观:我们同时学习的工作越多,我们的模型找到一个含有所有任务的表征就越困难,而过拟合我们原始任务的可能性就越小。
- 参数的软共享机制(基于约束的共享,Regularization Based)
即每个任务都有自己的参数和模型。模型参数之间的距离是正则化的,以便鼓励参数相似化,例如使用 L2 距离进行正则化。
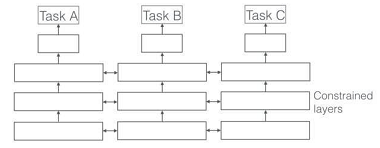 约束深度神经网络 Soft 参数共享的思想受到了 MTL 正则化技术的极大启发,这种思想已经用于其它模型开发。
约束深度神经网络 Soft 参数共享的思想受到了 MTL 正则化技术的极大启发,这种思想已经用于其它模型开发。
具体如何设计 MTL 的结构,首先在基于 MTL 基本原则情况下(存在共享表示和相关任务),应从任务特点、资源消耗、性能效果等方面去综合考虑。
结束语
model是实验室的产物,solution才是推向市场的结果,毕竟客户要的是solution,而不是model。
solution意味着需要产品化和工程化的思维方式,这是工业界和学术界最大的不同,也是其魅力所在。