Last updated on 2020-03-16…
与一般推荐场景不同,搜索广告是一种具有严格限制性的推荐,本文在参考搜狗公司舒鹏在去年年初分享的一篇《深度学习新技术在搜狗搜索广告中的深化应用》的基础上作了一些补充,从自动化广告创意的业务场景切入,着重探究其背后的一些技术发展。
往期相关传送门:《搜索与竞价广告》、《feed流与广告投放》
背景知识
跟信息流广告或其他类型广告不同,搜索广告客户通过关键词来表达投放诉求,这些关键词将形成广告库,即所有客户所有广告的结构化集合。
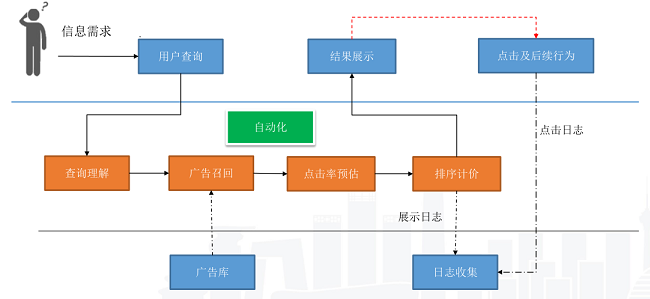
有了广告库,第一步是要从中选出哪些客户的投放诉求跟当前的查询需求匹配,一般称为广告召回。
然后我们会做一个点击率预估,用来评价具体的投放诉求对当前查询的吸引程度,基于它来做后续的排序和计费,并对最终结果进行渲染展示。
用户可能会感兴趣并点击浏览,我们会把整个过程用日志完整记录下来,用于后续优化。
对于一些中小广告主或者说资源不是很充足的客户来说,我们没有精力去维护优化这么庞大的投放系统,更需要广告平台来帮他做一些加快投放效率的工作,我们称之为自动化。
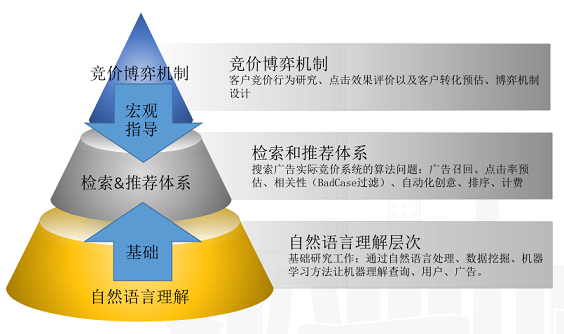
如何把客户表达投放诉求、用户表达查询意图,以及两者的匹配做成一个完整的自动化流程呢?(广告召回、点击率预估、相关性、badcase过滤、排序机制、自动化创意、竞价博弈机制等)
以搜索广告为例,创意就是广告本身的文案,标题怎么写,描述怎么写,配什么图片,配什么子链,目的都是为了带来更多的流量,让用户对商家经营的业务提前有更多的了解,形成更高效的转化。
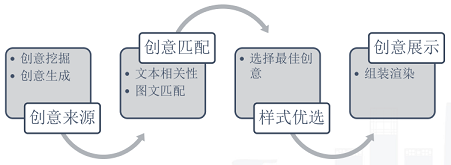
上图这四个步骤其实就是召回、匹配、排序、展示,下面会对各个步骤分别阐述。
召回
数据一般有两个维度,一个是规模,一个是质量,这两个维度通常不可兼得。规模大了之后质量一般会下降,或者质量高规模一般不会太大。如何在有限时间和计算资源情况下选出最佳的广告组合,本质是一种基于贪心的设计。

召回即候选创意集合,有一些比较好的图片、或比较好的文本片段、子链,才能做后续的优化工作。那这个候选创意集合怎么来的呢?大概会有两种方式:
创意挖掘,现在有的东西把它找过来,会有些来源,包括从客户着陆页网站来挖掘,以及从客户行为或用户行为层面来获取;创意生成,就是创造一些之前没有的素材,让系统自动写出一些比较符合当前意图的描述或者片段,这种方式大家应该也听过,比如让机器来自动写一些诗歌,谱一些曲子,或者画一些漫画。
创意挖掘
1、用户行为分析
- 搜索引擎每天都会收到大量查询,每天的查询量一般都是在亿这个数量级之上,这么多用户的行为是有高度价值的。
《 CA-LSTM: Search Task Identification with Context Attention based LSTM》,一种基于LSTM和attention机制的session切分方法。
2、落地页分析
- 就是客户的投放网站分析,比如客户买了一个词,那对应的落地页中通常来讲是有这个词的相关内容的。
3、购买行为分析
- 同一个业务很多时候不止一个商家来做,会有多个厂家同时做一块业务,他们的关键词购买既有竞争关系也有关联关系,如何利用这种行为数据来做一个拆解,获得我们想要的东西。
创意生成
使用基于生成式思想的模型,典型的比如GAN,这也是前几年刚出现的;还有一些基于seq2seq的翻译模型;CVAE也是生成式模式的一种变种。这几种方法的目标就是基于给定物料形成一种模式,而后根据输入来动态的定制化结果。
在生成的同时又不希望输出和输入完全一样。以“鲜花速递”为例,如果输出的结果还是“鲜花速递”,对我们是没有价值的,这两个是一样的、重叠的,我们希望能得到一些类似“蛋糕”这样的结果,一般来说送鲜花可能过生日,用户可能有购买蛋糕的需求,所以我们需要有些变化,但又不能变化太多,这就涉及到一些度的控制,这个系统里的一些模块就是做这个事情。
比如 Domain Classifiier 就是表达这个诉求的一个分类器:“生成的结果,是不是属于同样的一个域”,最后还会用强化学习的思想,也就是 Reward Estimator 来做这个工作,来评价生成结果的离散程度,生成结果的集中度越低,我认为效果可能越好,因为后边还会有相似性来保证结果里面到底有哪些合格哪些不好。
匹配
文本相关性

1、字符串匹配阶段
- 在经典的数据挖掘类书籍中多半都有介绍,比如 TF-IDF、BM25 以及后续的一些升级等典型检索算法。
- 例如基于广告库的字符串赋权算法,根据样本库可以得到每个分词片段的权重,来了两个 query 之后,可以对两者做一个匹配,如果匹配的权重高,相关度就高,权重低,相关度就低,可以得到得分,据此进行排序,定义阈值之后就会得到一个相关性算法。
- 但这个算法是有缺陷的,只是基于字面的匹配,例如“英雄联盟”和“LOL”,肯定算不出来,认为相关性是零,但其实是同一个游戏。
2、语义匹配阶段
- 会有些 topic model 的主题模型,比如 LDA,或者统计翻译、同义模板归一化,
- 还有实体识别来做这个工作,就能解决前面的一些问题,但这样也不能做到百分之百全覆盖。
3、意图匹配阶段
- 基于用户行为数据,比如每天的检索总共好几亿次或者上10亿次,每个查询都会有后续的一系列点击行为,两个不同的 query,如果点击的网页列表非常相似,这两个 query 是不是一回事,可以采用二部图挖掘或者 SVD++ 来挖掘这种关联关系。
4、深度学习与传统方法互补阶段
- 自从深度学习出来之后,这个方向就非常火,而且看起来也很酷,大家干的事情都差不多,从网上下一个模型然后跑一下,跑通之后换成这个数据灌一下,然后看结果对不对,如果对就上线,不对就换个模型再试一次,或者把参数调一调。
- 典型的深度学习算法效率一般比较低,如果任务本身是一个 QPS 非常高,计算复杂度非常高的场景,可能会需要有一些比较简单的方法来做一些初级的筛选,包括刚才提到的字符串匹配,这个功能现在还是很有用,只不过需要对它做一些新技术的加持,而不是直接把它抛弃。如果单纯的靠深度学习可能好多任务还是解决不了,或者解决的不够好。
- 具体到这里面涉及到的几个技术, seq2seq 及神经机器翻译,基于一个素材库,在已经有语料的情况下,如何构建一个模型框架,基于数据训练出一些表达网络,而后进行 query 的描述,或者其他内容的描述,然后进行一个匹配计算。
《Skipping Word: A Character-Sequential Representation based Framework for Question Answering》,一种无需分词、基于字符粒度表达的问答系统设计。
《Learning Deep Structured Semantic Models for Web Search using Clickthrough Data》,利用 query 和 title 之间的大量无标签偏序关系进行训练。
图文匹配
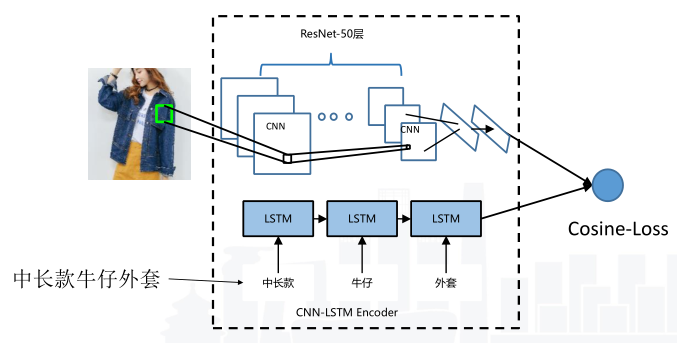
这里以图文匹配竞赛的其中一种常见思路举例:
- 首先用测试文本去训练集找“最近”文本,采用TFIDF余弦距离计算文本距离,找出相似新闻的Top10。
- 然后利用最相似训练样本的图片去搜索测试集中的候选图片,其中图片特征提取使用VGG16,图像相似度同样利用余弦距离。
- 最后将搜索到的图片取Top1为测试文本的匹配图片。
排序
任何一种算法要上线,必须得跟实际的业务场景进行结合,对于搜索广告来讲,它的场景非常典型,位置很有限。
- 例如部门主管规定,一个页面当中广告的占比不能超过 30%。
- 同时有很多种样式,产品经理会做出很多的设计,有些样式独占,有些需要组合。这个流程是一个基于
贪心的设计,本质上来讲,先选首条,再选后续的结果。
理论上应该把所有组合都把它给列出来,挨个计算,选择最优的,但这种方式在线上不可用,计算资源消耗非常高。假设你的 QPS 或一天流量在几个亿这个规模,每次一个 query 过来,可能会召回上百条广告,每天就有百亿以上的计算,所以说不允许采用太过复杂的方式。大家如何能够设计出一种非常清晰的描述,在做什么事情之前要想清楚到底要干什么,只有这样,后面才能做好,而不是说单纯的为了上线,或者单纯的上一个算法。
展示
最后再提一下搜索广告、展示广告、信息流广告的区别:
搜索广告:触发机制是用户搜索关键词,要求是广告主为这则广告所购买的关键词必须匹配到用户搜索的那个关键词。展示广告:大大小小的网站为了赚钱,把自己网站的某些位置拿出来当做广告位卖,出现在这些位置的广告称之为展示广告。信息流广告:内容推送广告,匹配用户以往浏览的兴趣点进行推送。