Last updated on 2020-06-20…
本篇整理自论文《MOBIUS: Towards the Next Generation of Query-Ad Matching in Baidu’s Sponsored Search》, 由百度搜索广告团队(“凤巢”)与百度认知计算实验室联合发表于KDD 2019,是一篇工业风满满的论文,干货很多。
往期相关传送门:《搜索与竞价广告》、《搜索广告之自动化创意》、《知识蒸馏在推荐系统的应用》
主体思路
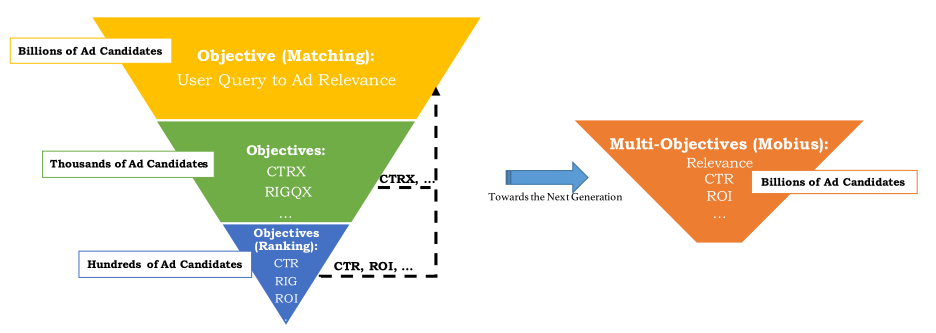
传统的广告匹配系统,一般采用三层漏斗形结构来筛选和分类数十亿个广告候选项中的数百个广告,需要满足低响应延迟的条件与计算资源的限制。 给定用户查询,最上面的召回(匹配)层负责向下一层提供语义相关的广告候选,而最下面的排序层则更多地关注那些广告的业务指标(例如CPM,ROI等)。
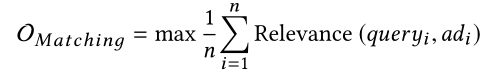
召回目标和排名目标之间的明确分隔会导致较低的商业回报。
凤巢团队提供了一种思路是把召回层和rank层融合,做成一层(Mobius系统),兼顾相关性和商业指标,论文里是Mobius的第一个版本,即Mobius-V1,优化目标如下:
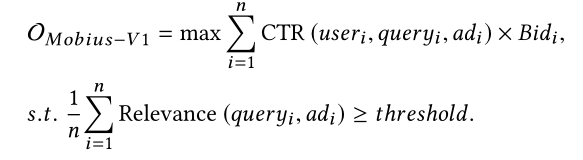
主动学习框架
三层架构变一整体,则馈入模型的样本中很容易有低相关性但高CTR的情况。
例如用户分别查询(搜索)了 Tesla Model 3 与 White Rose ,与广告 Mercedes-Benz 预估的出的CTR都挺高,但 White Rose 与广告的相关性是很低的。

为了解决上述问题,文中受主动学习(Active Learning)思想启发设计了一个“teacher-student”框架(类似知识蒸馏)。
具体而言,离线数据生成器负责在给定数十亿用户查询和广告候选的情况下构造合成查询广告对。
- 这些查询广告对(query-ad pair)由来自原始匹配层的teacher agent不断进行判断,并且擅长于测量查询广告对的语义相关性。它可以帮助检测查询广告对中的bad case(即CTR高但相关性低)。
- student以主动学习的方式从不断扩大的bad case中获得了与相关性有关的其他知识,以提高尾部查询和广告的泛化能力。
作者认为模型的主要的问题是怎么让模型识别出低相关性且高ctr的query-ad pair作为bad case。
为了学习出bad case,那么就需要人工构造出bad case的样本,再通过在模型的目标函数中加上bad case率这个目标来进行学习。
因此,整体分成了2个部分:人工构造样本和模型学习。

结合图中的关键步骤进行说明:
- 拿到一个batch的训练样本
- 拆分出query集合和ad集合
- 基于两个结合做cross join,生成样本
- 用相关性模型(之前的match阶段的模型)对所有生成的样本进行相关性预估
- 设定一个相关性阈值,把低于这个阈值的样本认为是lowRelAugData,用ctr模型进一步进行ctr预估
- 从低相关的样本中,根据ctr预估值筛选出高ctr的样本做为bad case。常规的做法是手工设定一个ctr阈值,选出高于这个阈值的样本。但是为了
balance the exploration and exploitation of the augmented data,这里实现了一个采样器,通过采样选出高ctr样本,保证了一定的探索性。 - 把人工构造的bad case样本跟常规训练样本合并,放出到trainBuffer
- 进行模型训练
模型训练图:
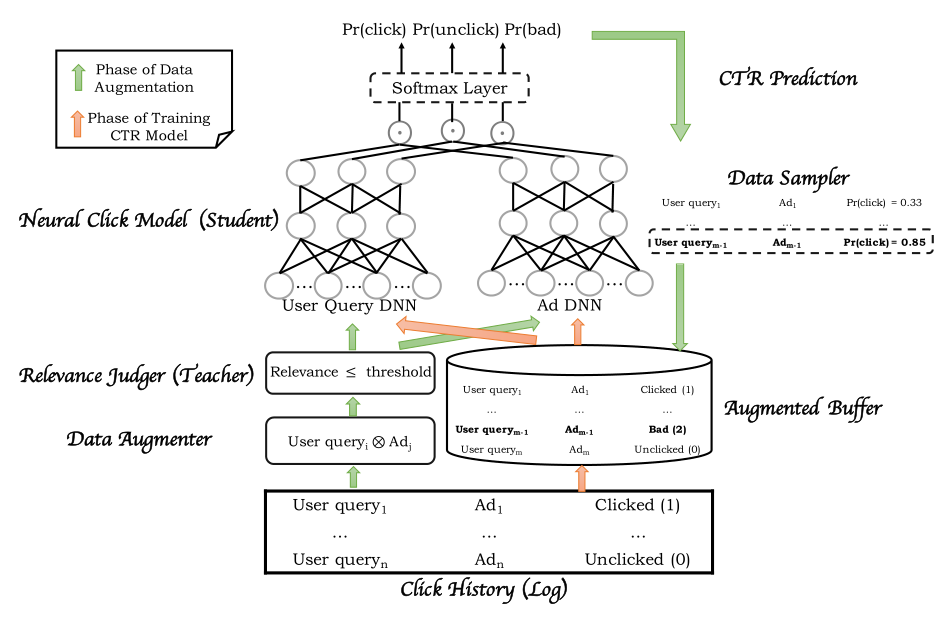
结合图再描述一遍,这个图的观看顺序是先看绿色的线,再看红色的线。绿色的线从底部开始看:
- 获取样本
- 构造低相关性样本
- 样本过一遍模型的ctr预估
- data sampler选出bad case
再看红色的线:
- bad样本跟正常的点击和未点击样本放到一起,因此所有样本有3种label(click\unclick\bad case) ,分别对应0、1、2
- 网络是双塔结构,quert和ad分别各一个网络,到最上面是96维(32 * 3)
- 分别做cos后果softmax,拟合3种label
- 最后学习出的pr(click)可以用于线上ctr预估,pr(bad)可以用来过滤
ctr高但相关性差的样本
检索性能优化
传统多层漏斗架构的优势就是通过多级筛选,逐步减少每一层要预估的资源条数,从而缓解性能问题。 如果mobius要直接从百万级的广告中进行检索,那么在线检索性能就是需要考虑的问题。
为了节省计算资源并满足低响应延迟的要求,文中进一步采用了最新技术的近似最近邻居(ANN)搜索和最大内部乘积搜索(MIPS)技术来对大量索引进行检索和检索广告更有效。
最近邻居搜索 ANN
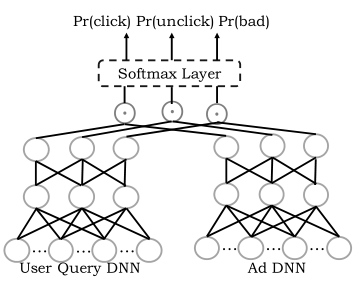
线上实时检索为了处理数百万条候选集,必须采用近邻检索的方式。
- 映射函数通过余弦相似度将用户向量和广告向量组合在一起,然后余弦值穿过softmax层以生成最终的CTR。这样,余弦值和CTR
单调相关。学习了模型后,很明显它们是正相关或负相关的。 - 如果它是负相关的,文中可以通过
取负ad向量轻松将其转换为正相关。这样,文中将CTR排名问题简化为余弦排名问题,这是典型的ANN搜索设置。
近似最近邻(ANN)搜索的目的是通过仅扫描语料库中的一小部分对象,为给定的查询对象从大型语料库中检索“最相似”的对象集。这是一个基本问题,自计算机科学的早期以来就已得到积极研究[12,13]。
通常,用于ANN的流行算法是基于空间划分的思想,包括基于树的方法、随机哈希方法、基于量化的方法、随机分区树方法等。
对于这个特定问题(处理稠密和相对短的向量),随机分区树方法相当有效。除其他变体外,还有一种称为 “ANNOY” 的随机分区树方法的已知实现。
相关论文:Random projection trees and low dimensional manifolds、Randomized Partition Trees for Nearest Neighbor Search
最大内部乘积搜索 MIPS
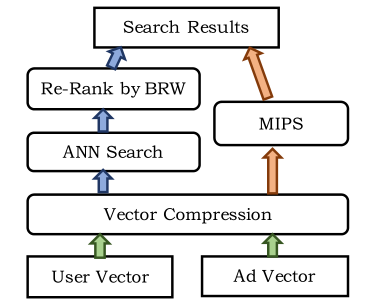
常规的做法是左边那条通路——user和ad向量生成后做向量压缩,通过ann检索后结果再根据business weight进行调整。
文中的做法是把business weight调整融合到ann的cos检索中,通过加权余弦问题对快速排名过程进行了形式化,如下所示:
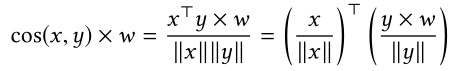
其中w是与业务相关的权重,x是用户查询嵌入,y是广告向量。 请注意,加权余弦构成了一个内部乘积搜索问题,通常被称为最大内部乘积搜索(MIPS)。
相关论文:Asymmetric LSH (ALSH) for Sublinear Time Maximum Inner Product Search (MIPS)
向量压缩方法 OPQ
为数十亿个广告中的每一个存储高维浮点特征向量会占用大量磁盘空间,如果这些特征需要存储在内存中以进行快速排名,则会带来更多问题。
通用解决方案是将浮点特征向量压缩为随机的二进制(或整数)哈希码或量化码。
压缩过程可以在一定程度上减少检索的召回率,但可以带来显着的存储效益。
对于当前的实现,文中采用了基于量化的方法(例如K-Means)对索引向量进行聚类,而不是对索引中的所有广告向量进行排名。
- 当查询到来时,文中首先找到为其分配查询向量的集群,然后从索引中获取属于同一集群的广告。
乘积量化(PQ)的想法进一步迈出了一步,将向量拆分为几个子向量,并对每个拆分分别进行聚类。
在文中的点击率模型中,文中将查询嵌入和广告嵌入都分为三个子向量。
然后,可以将每个向量分配给群集质心的三元组。
例如,如果文中为每组子向量选择1000个质心,则可以利用10^9个可能的聚类质心,这足以满足广告的十亿规模多索。
在Mobius-V1中,文中采用了一种称为优化乘积量化(OPQ)的变体算法。
相关论文:Optimized Product Quantization for Approximate Nearest Neighbor Search
实验部分
相比原始点击和未点击样本训练的模型,新模型在auc上有一定下降,但是相关性有大幅提升。

文中提出新的检索方案,比传统ANN方案在广告检索覆盖率和性能方面都有很大的提升。

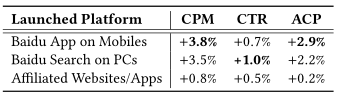
最终上线,广告收益CPM等也有很大的提升。