Last updated on 2020-12-20…
目前工业界主流的分布式训练是基于数据并行方式实现的,其中具有代表性的两种架构是参数服务器(PS)和All-reduce。
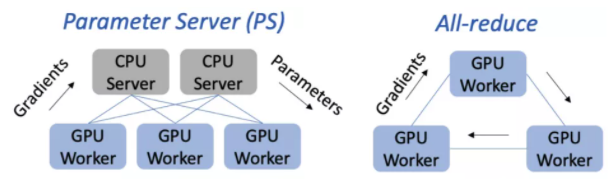
PS 架构则包含 GPU worker 和 CPU server:
- GPU worker将梯度传输至 CPU server
- CPU server将接收到的不同 workers 的梯度做聚合,然后执行 DNN 优化器(如 RMSProp 或 Adam 等)并将更新后的参数传输回 GPU workers
All-reduce 架构中仅用到 GPU 机器:
- 其设计假定了每个节点都是同构节点
- 迭代过程中,GPU 独立计算模型参数的梯度,然后使用 All-reduce 通信聚合梯度
目前的 All-reduce 和 PS 架构在训练性能上距离最优情况都有较大差距。
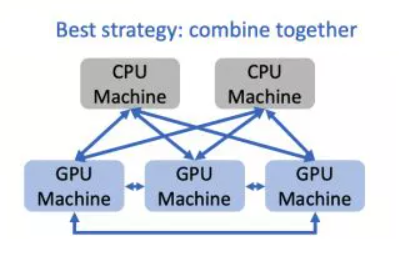
BytePS结合了上述两者架构,其系统架构图如下:
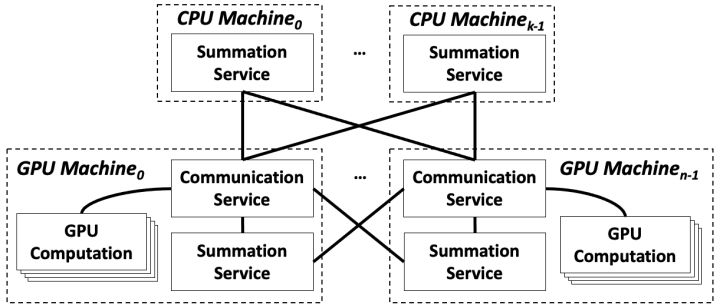
-
每台 GPU 机器上部署了一个
Communication Service模块,负责聚合本地多卡的梯度(即机器内多卡通信),其能充分考虑机器内部复杂的拓扑,避免产生 PCIe 瓶颈。 -
每台 GPU/CPU 机器上部署了一个
Summation Service模块,处理来自其他 GPU 机器的梯度,其能够高效运行在 CPU 上。 -
模块之间通过网络互连,通信策略使用的是前述设计中提到的最优网络通信方案。经证明,该方案不仅有最佳的性能,且能够
从通信角度统一All-reduce 和 PS 两种架构。
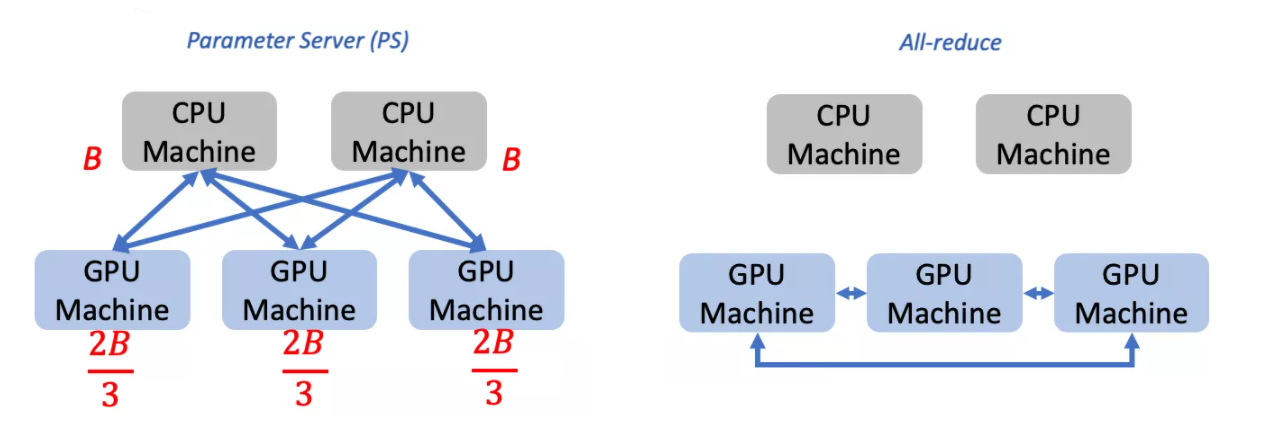
机器间网络通信问题
All-reduce 的同构化设计导致其无法充分利用这种异构资源,即只有 GPU workers 之间通信,而无法利用其他 CPU 和带宽资源。
而 PS 虽然能够利用 CPU 机器作为 server,却可能在 CPU server 数量较少的时候产生流量热点(例如形成多对一的情况),从而导致网络拥塞。
PS仅利用了 GPU 机器与 CPU 机器之间的带宽。在 CPU 机器数量较少时,GPU 机器的带宽 B 无法充分利用(下图给出了一个例子,在这种情况下,GPU 机器仅能达到 2/3 的最大带宽,剩余 1/3 带宽未得到利用)。All-reduce仅利用了 GPU 机器之间的带宽。此时,GPU 机器与 CPU 机器之间的带宽未得到利用。
优化
BytePS 结合两者之长,同时利用了 GPU 与 GPU 之间、GPU 与 CPU 之间的带宽,使得每台机器的带宽都能被充分利用。这就是 BytePS 机器间通信的思路。
该思路在实现过程中,需要考虑如何分配 GPU 与 GPU 之间(设为 x%)、GPU 与 CPU 之间(设为 y%)的流量比例。经过计算,最优比例如下(其中 n 表示 GPU 机器的数量,k 表示 CPU 机器的数量):
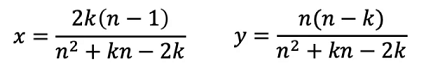
以上即为最优通信策略,对于不同的 n 与 k,采用该策略可使得机器间通信时间最小。
机器内多卡 PCIe 带宽竞争问题
如今一台训练机器通常都具备有多张 GPU 卡(例如 4 或 8 卡,目前市面上主流有两种机器拓扑:PCIe-only 型 8 卡机器和 NVLink-based 型 8 卡机器)。在做机器间的通信前,机器内部的多 GPU 之间需要首先做一次本地通信,该通信过程一般是基于 PCIe 或 NVLink 链路。
我们观察到,目前的网卡如 Mellanox CX5 带宽已达 100Gbps,已经很接近 PCIe 3.0 x16 的 128Gbps 链路带宽。
而不幸的是,现在流行的机器内聚合方式(例如 8 卡直接做 all-reduce)会使 PCIe 成为瓶颈,导致网卡无法达到其 100Gbps 带宽上限。
即使对含有 NVLink 的拓扑,我们也能发现类似的 PCIe 竞争 导致的瓶颈问题。
BytePS 针对PCIe-only 型 8 卡机器和 NVLink-based 型 8 卡机器这两类拓扑提出了通用的解决方案和设计原则。
PCIe-only 型拓扑优化
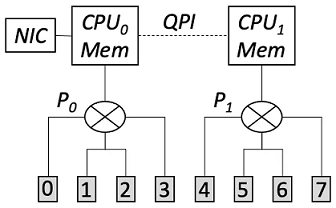
如上图所示,标记 0-7 的灰框表示 GPU,P0 和 P1 表示 PCIe switch。现实当中, P0-CPU0 以及 P1-CPU1 是带宽最小的链路,因此优化目标是最小化这条链路上传输的数据量。目前主流的做法是对这 8 卡做一次全局 All-reduce,这样 P0-CPU0 需要传输的数据量是 7M/4(根据 All-reduce 的通信量计算得出),其中 M 是每张卡上的梯度大小。注意到该做法并没有利用 CPU 的计算能力。
BytePS 的核心思想是利用 CPU 的计算能力减少瓶颈链路的传输数据量。如下图所示:
- 首先每个 PCIe switch 下的 4 张卡先进行一次 Local Reduce-scatter。该步骤之后,每张卡上已聚合的梯度大小为 M/4。
- 接着每张卡将自身已聚合的 M/4 梯度拷贝到主机的内存上。注意这个过程使得 P0-CPU0 只传输了 M/4*4=M 的流量。
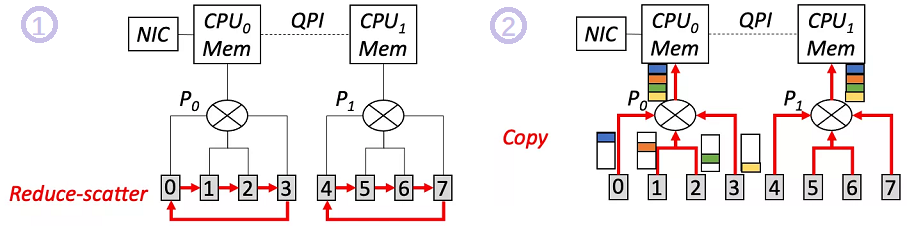
此时,两个 NUMA node 的主机内存上各自有一份大小为 M 的梯度。我们再利用 CPU 将这两份梯度做一次聚合。 但是这个过程的传输只发生在带宽较大的 QPI 上(>300Gbps),并不会产生瓶颈。 于是这一系列步骤不但实现了预期中的梯度聚合效果,还使瓶颈链路的传输量从 7M/4 降低为 M,显著降低了通信时间。 这里的核心设计原则是:尽量避免跨 NUMA GPU 的直接通信,而可以利用 CPU 的聚合能力来间接完成。
PCIe-only 型拓扑优化
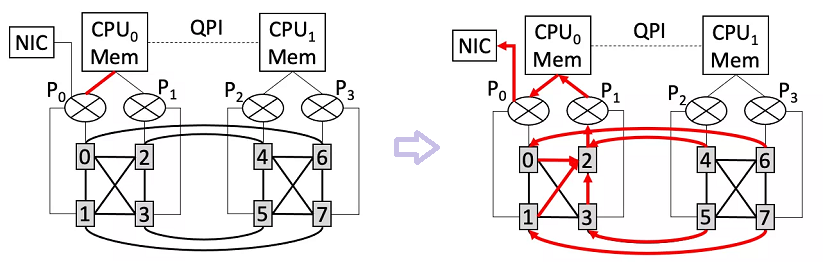
上图(左)是 NVLink-based 机型的示意图。对于这种拓扑,GPU 之间可以通过超高带宽的 NVLink 链路进行通信。
由于 NVLink 带宽显著大于 PCIe 带宽,PCIe 瓶颈问题显得更加严重。可以看到,图中 P0-CPU0 链路(标红色的线段)会同时被以下两种传输同时竞争:
- CPU0 的内存往 GPU0/GPU1 拷贝数据;
- CPU0 的内存往网卡 NIC 发送数据。由于 P0-CPU0 链路的带宽与网卡带宽很接近,这种竞争会导致网卡无法发挥最大带宽。
为解决这一竞争问题,BytePS 利用了 NVLink 带宽显著高于 PCIe 链路的事实,利用 Reduce(而非 Reduce-scatter)方式避免 PCIe 竞争。上图(右)中红线所示:
- 所有卡先将其梯度通过 NVLink 传输至 GPU2 上并做 Reduce
- 接着 GPU2 将聚合后的梯度拷贝到 CPU0 内存,再经由网卡发送出去
由于 NVLink 带宽很高,这种做法不会导致 GPU2 产生流量热点问题,但却能够避免在 P0-CPU0 链路上发生的竞争。
通信链路中的 CPU 瓶颈问题
从前面的第一个问题中可以看出,相比于 All-reduce 而言,PS 架构实际上是存在更大的潜力的,因为它能充分利用异构 GPU/CPU 资源。 然而,目前的 PS 甚至比 All-reduce 性能显著低,似乎与之矛盾。这是因为 PS 架构中还存在另外一种瓶颈限制了其性能——CPU 瓶颈。 顾名思义,PS (参数服务器)需要将参数存储在 CPU server 上,这就意味着需要将优化器 (如 Adam/RMSProp 等) 放在 Server 上去执行。 然而,优化器通常包含复杂的数学运算,将会消耗大量的 CPU 内存带宽(在 100Gbps 的网络输入情况下,CPU 将无法满足将完整优化器放置在其上运行的需求)。
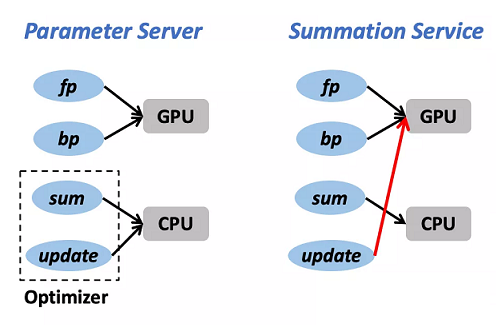
Summation Service 优化
前文提到,优化器对于 CPU 而言是比较重的任务,这也是 PS 架构的性能缺陷之一。然而,如何高效利用 CPU 的异构计算能力是 BytePS 的核心诉求之一,这就需要克服数据同步过程中的 CPU 瓶颈。 经分析,优化器可被拆解为两部分:
Sum:将来自其他 GPU workers 的梯度求和并得到一份聚合后的新梯度Update:利用新梯度对参数进行更新。后者对于 CPU 而言的确是非常消耗内存带宽的操作,但前者却能够在 CPU 上高效实现(例如 AVX 指令集)。
如下图所示,求和操作在 CPU 上可以达到远超网络带宽的吞吐率,即不会引入 CPU 瓶颈:
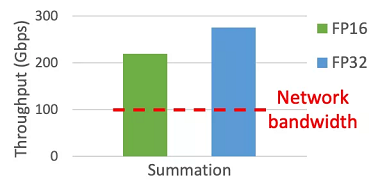
受到这个发现的启发,BytePS 提出了 Summation Service 概念,对传统 PS 的 CPU 瓶颈问题做了改进。 如下图所示,不同于 PS 将完整优化器放置在 CPU 上的设计,Summation Service 只将 Sum 操作放置在 CPU 上,而将 Update 操作交由计算能力更强大、内存带宽更充足的 GPU 来执行。这种设计能够避免同步过程中的 CPU 瓶颈。
性能评估
BytePS 对多种 CV 类(包括 ResNet-50,VGG-16 ,GAN)和 NLP 类(Transformer,BERT-Large,GPT-2)模型都做了分布式性能评测,规模从 8 卡 - 256 卡。所使用的硬件是 V100 GPU 和 100Gbps RDMA 网络。对照组为目前广泛使用的 All-reduce 和原生 PS 实现。
下面两张图分别展示了 CV 和 NLP 模型上的评估结果。总体而言,BytePS 在各类模型上都取得了正向收益,且相比于 All-reduce 和 PS 能够达到的最大提升幅度达 84% 和 245%。

