Last updated on 2021-03-21…
图分析使用基于图的方法来分析连接的数据。我们可以: 查询图数据,使用基本统计信息,可视化地探索图、展示图,或者将图信息预处理后合并到机器学习任务中。
图的查询通常用于局部数据分析,而图计算通常涉及整张图和迭代分析。图算法基于图论,利用节点之间的关系来推断复杂系统的结构和变化。我们可以使用这些算法来发现隐藏的信息,验证业务假设,并对行为进行预测。
因为此部分偏基础内容,大家都比较熟悉,所以着重讲应用。
路径搜索
路径搜索(Pathfinding)算法建立在图搜索算法的基础上,并探索节点之间的路径。 这些路径从一个节点开始,遍历关系,直到到达目的地。 路径搜索算法识别最优路径,用于物流规划,最低成本呼叫或者叫IP路由问题,以及游戏模拟等。
1. 遍历 BFS 、DFS
最短路径问题和中心性问题都使用了 BFS 算法;而 DFS 可以用于模拟场景中的可能路径,因为按照 DFS 访问节点的顺序,我们总能在两个节点之间找到相应的路径
2. 最短路径 Dijkstra、A star、K-Shortest
算法可以快速给出两点之间的最短距离,可以计算两点之间成本最低的路线等等。例如:
- 导航:谷歌、百度、高德地图均提供了导航功能,它们就使用了最短路径算法
- 社交网络关系:当我们在 LinkedIn、人人等社交平台上查看某人的简介时,平台会展示你们之间有多少共同好友,并列出你们之间的关系
3. 最小生成树 Prim、Kruskal
算法可以用于优化连接系统(如水管和电路设计)的路径。它还用于近似一些计算时间未知的问题,如旅行商问题。 虽然该算法不一定总能找到绝对最优解,但它使得复杂度极高和计算密集度极大的分析变得更加可能。例如:
- 旅行计划:尽可能降低探索一个国家的旅行成本
- 追踪流感传播的历史:有人使用最小生成树模型对丙型肝炎病毒感染的医院暴发进行分子流行病学调查
4. 随机游走 Random Walk
算法一般用于随机生成一组相关的节点数据,作为后续数据处理或者其他算法使用。
- 作为 node2vec 和 graph2vec 算法的一部分,用于节点向量的生成,从而作为后续深度学习模型的输入
- 作为 Walktrap 和 Infomap 算法的一部分,用于社群发现。如果随机游走总是返回同一组节点,表明这些节点可能在同一个社群
- 其他机器学习模型的一部分,用于随机产生相关联的节点数据,以便用于数据分析
中心性
中心性算法(Centrality Algorithms)用于识别图中特定节点的角色及其对网络的影响。 中心性算法能够帮助我们识别最重要的节点,帮助我们了解组动态,例如可信度、可访问性、事物传播的速度以及组与组之间的连接。 尽管这些算法中有许多是为社会网络分析而发明的,但它们已经在许多行业和领域中得到了应用。
1. 度中心性 Degree Centrality
表示连接到某节点的边数。在有向图中,我们可以有2个度中心性度量:流入和流出。一个节点的节点度越大就意味着该节点在网络中就越重要。应用场景例如,区分在线拍卖的合法用户和欺诈者,欺诈者由于尝尝人为太高拍卖价格,拥有更高的加权中心性(weighted centrality)。
2. 接近中心性 Closeness Centrality
从某节点到所有其他节点的最短路径的平均长度。反映在网络中某一节点与其他节点之间的接近程度。当我们希望关注网络中传播信息最快的节点,我们就可以使用紧密性中心性。
3. 介中心性 Betweenness Centrality
某节点在多少对节点的最短路径上。介数中心性是比较能体现节点在图中桥梁作用的中心性度量方法。介数反映了相应的节点或者边在整个网络中的作用和影响力,具有很强的现实意义。例如,在交通网络中,介数较高的道路拥挤的概率很大;在电力网络中,介数较高的输电线路和节点容易发生危险。
4. k-核中心性 k-Core Centrality
网络的k-核(k-Core)是指反复去掉度小于或等于k的节点及其连接的边之后,所剩余的子网。算法输出每个结点所对应的最大阶数。
5. 影响力排名 PageRank
用于测量节点传递影响的能力。PageRank 不但节点的直接影响,也考虑 “邻居” 的影响力,统计到节点的传入关系的数量和质量,从而决定该节点的重要性。 PageRank 算法已经不仅限于网页排名。例如:
- 寻找最重要的基因:我们要寻找的基因可能不是与生物功能联系最多的基因,而是与重要功能有紧密联系的基因
- 推荐用户:Twitter使用个性化的 PageRank 算法(Personalized PageRank,简称 PPR)向用户推荐他们可能希望关注的其他帐户。该算法通过兴趣和其他的关系连接,为用户展示感兴趣的其他用户
- 交通流量预测:使用 PageRank 算法计算人们在每条街道上停车或结束行程的可能性
- 反欺诈:医疗或者保险行业存在异常或者欺诈行为,PageRank 可以作为后续机器学习算法的输入
社群发现
社群发现算法(Community Detection Algorithms)有助于发现社群中群体行为或者偏好,寻找嵌套关系,或者成为其他分析的前序步骤。 社群发现算法也常用于网络可视化。识别社群对于评估群体行为或突发事件至关重要。 对于一个社群来说,内部节点与内部节点的关系(边)比社群外部节点的关系更多。 识别这些社群可以揭示节点的分群,找到孤立的社群,发现整体网络结构关系。
1. Measuring Algorithm
三角计数(Triangle Count)和聚类系数(Clustering Coefficient)经常被一起使用。
- 三角计数计算图中由节点组成的三角形的数量,要求任意两个节点间有边(关系)连接。
- 聚类系数算法的目标是测量一个组的聚类紧密程度。该算法计算网络中三角形的数量,与可能的关系的比率。
2. Components Algorithm
关联类算法作为图分析的早期算法,用以了解图的结构,或确定可能需要独立调查的紧密集群十分有效。对于推荐引擎等应用程序,也可以用来描述组中的类似行为等等。许多时候,算法被用于查找集群并将其折叠成单个节点,以便进一步进行集群间分析。
3. Label Propagation Algorithm
标签传播算法是一个在图中快速发现社群的算法。在 LPA 算法中,节点的标签完全由它的直接邻居决定。 算法非常适合于半监督学习,你可以使用已有标签的节点来种子化传播进程。
4. Louvain Modularity Algorithm
该算法在给节点分配社群时,会比较社群的密度,而不仅仅是比较节点与社群的紧密程度。算法应用:
- 检测网络攻击:该算可以应用于大规模网络安全领域中的快速社群发现。一旦这些社群被发现,就可以用来预防网络攻击
- 主题建模:从 Twitter 和 YouTube 等在线社交平台中提取主题,基于文档中共同出现的术语,作为主题建模过程的一部分
频繁模式挖掘
频繁模式是在数据集中出现的频率不小于用户指定的阈值的项目集、子序列或子结构(著名例子:尿布和啤酒)。 例如,frequent itemset,如牛奶和面包,就是是频繁项集。子序列,例如先购买PC,然后是数码相机,然后是存储卡,如果它经常出现在购物历史数据库中,是一种(频繁的)顺序模式。 子结构,subsequence可以参考不同的结构形式,例如子图、子树或子格,这些结构形式可能与项目集或子序列相结合。 如果一个子结构经常出现在一个图形数据库中,它被称为(频繁)结构模式 (frequent) structural pattern。 发现频繁模式在挖掘关联、关联和数据之间的许多其他有趣关系中扮演着重要的角色。
其比较典型的有Apriori、FP-growth、Eclat三个算法:
- Aprior算法的基本思想是循环由K项频繁项集产生K+1项频繁项集,直到满足条件的频繁项集发现为止。(存在两个问题:生成大量候选集;反复扫描数据库并检查模式匹配对候选对象)
- FP-growth算法只需要扫描两次数据集。该算法包含两部分内容,首先需要构造FP-tree,它高度压缩了数据库中的信息。然后在FP-tree上挖掘出频繁模式
- Eclat算法仅需要一次扫描数据集。该算法加入了倒排的思想,具体就是将事务数据中的项作为key,每个项对应的事务ID作为value
模式匹配
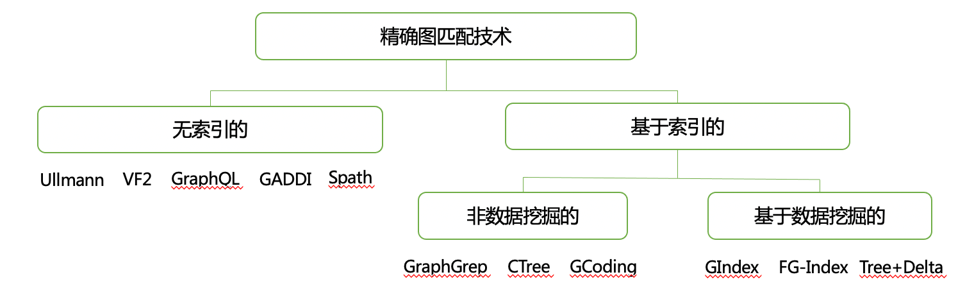
图模式匹配旨在寻找与给定模式图相似的数据图的子图, 在过去的几十年中得到了广泛的实际应用。 例如在社交媒体流计算、计算机网络流量数据应用中高效分析这种流图数据 对于诸如检测异常事件(例如在 Twitter 中)和检测计算机网络中的对抗性活动等任务具有重要意义。 (匹配问题复杂,判断图数据中是否包含用户搜索的模式图是一种子图同构问题,属于NP完全问题)
模式图和“匹配”语义的不同会形成不同的图匹配查询语言。按照模式图结构的不同可分为:点查询(如可达性查询、邻居节点查询等)、路经查询(如最短路查询等)以及子图结构查询(如子图同构、图模拟、强模拟等)。
动态查询:由于数据图经常动态变化,其结构(顶点和边)和属性都可能出现变动。动态查询研究的是当数据图的顶点和边增加或减少后,如何在利用原有的匹配查询结果来快速得到数据图变化后的结果,而不需要从“零”开始重新进行计算非确定查询:造成图的不确定性的原因有两个:由于数据采样或者数据丢失造成的数据本身的质量问题,以及数据自身的内在的动态变化特性,采用合理的模型描述图的不确定性,并设计有效的非确定性图匹配查询分布式查询:当数据图规模大到无法在单台机器上处理时,就需要将数据图分布在多台机器上,以便进行分布式查询。衡量分布式查询好坏的指标包括查询过程中的节点访问次数、数据传输量和查询完成时间
图分析系统发展
由于图分析算法的多样性和分布式计算的复杂性,分布式图分析算法往往需要遵循一定的编程模型。当前的编程模型有点中心模型“Think-like-vertex”,基于矩阵的模型和基于子图的模型等。在这些模型下,涌现出各种图分析系统,如 Pregel、 Apache Giraph、 PowerGraph、Spark GraphX等。

1. Pregel
Google 于 2010 年在 SIGMOD 上发表论文《Pregel: a system for large-scale graph processing 》,Pregel在相当长一段时间是Google PageRank的主要计算系统,但没有开源。
2. Apache Giraph
Apache Giraph 是Pregel论文的开源实现,以 Hadoop 为基础开发的上层应用,其系统架构和计算模型与 Pregel 保持了一致,同时也在 Pregel 模型上增加了一些新的特性。
3. PowerGraph
CMU 于 2012 年在 OSDI 上发表论文《PowerGraph: Distributed Graph-Parallel Computation on Natural Graphs》,PowerGraph后来被集成到GraphLab后成为GraphLab的一个主要底层框架,GraphLab实际上是一个机器学习框架,里面实现了非常多的机器学习算法,之前GraphLab是一个开源项目,但它在接受了两轮投资之后已经由原来的免费项目变成了一个付费试用的项目。
4. Spark GraphX
UC Berkeley 于2014年在USENIX上发表论文《 GraphX: Graph Processing in a Distributed Dataflow Framework 》,是Spark 中用于图形和图形并行计算的新组件。在高层次上, GraphX 通过引入一个新的图形抽象来扩展 Spark RDD:一种具有附加到每个顶点和边缘的属性的定向多重图形。为了支持图计算,GraphX 公开了一组基本运算符(例如: subgraph、joinVertices 和 aggregateMessages )以及 Pregel API 的优化变体。
从图分析系统思考分布式计算系统发展
Google发表于SOSP‘03的GFS和OSDI ‘04的MapReduce两篇论文向大家展现了如何通过较为廉价的普通服务器集群进行大规模数据的管理和处理。基于这两篇论文的核心想法,Hadoop于2006年诞生,并一直以开源的模式发展至今。自此,“大数据”不再像以前那样高高在上,而我们也有了处理大规模图数据的原始武器:Hadoop。
尽管MapReduce的处理模型十分简洁易懂,但它并不适合图数据分析。这是由图分析算法的特点导致的:它们通常都是迭代式的计算过程,且每一轮计算涉及的数据会随着算法的进度不断发生变化。使用Hadoop实现图分析算法时,我们不得不反复地将中间结果序列化到磁盘,从而产生了不必要的开销。
事实上,凡是需要迭代式计算的场景如很多机器学习问题用到的算法都不适合用Hadoop来完成。Spark针对这一点,提出了将中间结果缓存到内存中的想法,尽可能地避免中间结果落地到外存上;通过用户自定义的划分方法,还可以极大地减少机器之间的通信。相比Hadoop,Spark能够在图数据的规模能够容纳到集群的内存中时获得显著的性能提升。
但是,Spark的RDD模型还是限制了它的发挥:Spark在计算过程中产生的RDD都是不可变(immutable)的,因此产生的大量中间结果依然会导致不必要的内存占用从而影响能够处理的图数据规模和图计算效率。
需要指出的是,尽管使用通用的大数据处理系统如Hadoop/Spark等进行图计算的效率较低,但它们在图数据分析的预处理/后处理等场景上依然有不可或缺的作用。