Last updated on 2020-2-12…
本文是对《美团机器学习实战》一书中特征工程篇的个人总结,代码实践版见我的另一篇博客:《Python特征工程篇》。文末最后一节为总结出的实际经验。
竞赛中没灵感时候才会稍微看看的文章…
数值特征
数值类型的数据具有实际测量意义,分为连续型(身高体重等)和离散型(计数等),有如下8种处理方法:
1.截断:超出合理范围的很可能是噪声,需要截断。另外,对于长尾的数据,可以先进行对数转换,然后进行截断。
2.二值化:略。
3.分桶:固定宽度分桶(均匀或者以10的幂)、分位数分桶(基于数据的分布等量分)、使用模型分桶(比如聚类)。
4.缩放:标准化、最大最小值、最大绝对值、基于L1或L2范数、平方根、对数、Box-Cox(简化的幂变换,仅正数)、基于中位数、基于分位数。
5.缺失值处理:补均值、补中位数、用模型预测缺失值、将缺失作为一种信息进行编码喂给模型让其学习。
6.特征交叉:两个数值变量的加减乘除、FM和FFM模型。
7.非线性编码:多项式核与高斯核、将随机森林模型的叶节点进行编码喂给线性模型、基因算法、局部线性嵌入、谱嵌入、t-SNE。
8.行统计量:如空值的个数、0的个数、正值个数与负值个数,以及均值、方差、最小值、最大值、偏度、峰度。
类别特征
类别数据表示的量可以是人的性别、婚姻状况、家乡、喜欢的电影类型等,其取值可是数值(如1代表男,0代表女),但是作为数值没有任何数值意义。
1.自然数编码:每个类别分配一个编号。对类别编号进行洗牌,训练多个模型进行融合可以进一步提升模型效果。(弊:简单模型容易欠拟合,复杂模型容易过拟合)
2.独热编码:每个特征取值对应一维特征,从而得到稀疏的特征矩阵。(弊:矩阵稀疏)
3.分层编码:比如邮编、身份证号等,取不同的位数进行分层,然后按层次进行自然数编码。
4.散列编码:对于取值特别多的,可以先散列后独热。可能导致特征取值冲突。
5.计数编码:这种方法对异常值比较敏感,也可能导致特征取值冲突。
6.计数排名编码:这种方法对异常点不敏感,不会导致特征取值冲突。
7.目标编码:有监督的编码方法,需结合交叉验证。(如CTR任务中,可对广告主ID结合过去固定时间段内的点击率进行编码)
8.交叉组合(类别+类别):笛卡儿积操作、基于分组统计。
9.交叉组合(类别+数值):如统计产品在某个区域的销量、价格、平均价差等。
时间特征
1.年、月、日、时、分、秒、星期几。
2.是 否:季度初、季度末、月初、月末、周末、营业时间、节假日。
3.过了多久:产品上线至今多久、顾客上次借款距离现在的时间间隔、两个时间间隔之间是否包含节假日或其他特殊日期等。
4.时间序列分析:滞后特征(又称lag特征,当前时间点之前的信息)、滑动窗口统计特征(如回归问题中计算前n个值的均值,分类问题中前n个值中每个类别的分布)。
空间特征
1.经纬度 -> 散列成类别特征
2.坐标拾取系统:行政区ID、街道ID、城市ID -> 类别特征
3.计算距离:欧式距离、球面距离、曼哈顿距离、真实距离
文本特征
1.预料构建:构建一个由文档或短语组成的矩阵。矩阵每一行为文档,列为单词。通常文档个数与样本个数一致。
2.文本清洗:去除HTML标记、去停用词、转小写、去除噪声、统一编码等。
3.分词:
- 词性标注:名词(人动物概念事物)、动词(动作)、形容词(名词的属性)。
- 词形还原:把任何形式的语言词汇还原为一般形式(能表达完整语义)。
- 词干提取:抽取词的词干和词根(不一定能够表达完整语义)。
- 文本统计特征:文本长度、单词个数、数字个数、字母个数、大小写单词个数、大小写字母个数、标点符号个数、特殊字符个数等;数字占比、字母占比、特殊字符占比等;名词个数、动词个数等。
- N-Gram模型:将文本转换为连续序列,序列的每一项包含n个元素,目的是为了将一个或者多个单词同时出现的信息喂给模型。
4.Skip-Gram模型:(均未考虑词序信息)
- 词集模型:词01矩阵(0代表未出现,1代表出现)
- 词袋模型:词频矩阵(通常需过滤掉词频小的单词)
- TF-IDF模型:如果某个词或短语在一篇文档中出现的频率TF很高,并且在其他文档中很少出现,则认为此词语具有很好的类别区分能力,可以用来分类。
5.余弦相似度:检索词与文档的相关性。
6.Jaccard相似度:两个文档中相交单词个数除以两个文档出现单词的总和。
7.Levenshtein编辑距离:两个字符串由一个转成另外一个所需要的最少编辑操作(插入删除替换)次数。
8.隐性语义分析:把高维的向量空间模型表示的文档映射到低维的潜在语义空间。
- 比如SVD奇异值分解方法,对文档特征进行排序,我们可以通过限制奇异值的个数对数据进行降噪和降维。
9.Word2Vec:将单词所在的空间(高维空间)映射到一个低维的向量空间中。
特征选择
简化模型、改善性能、改善通用性、降低过拟合风险
常见方法比较
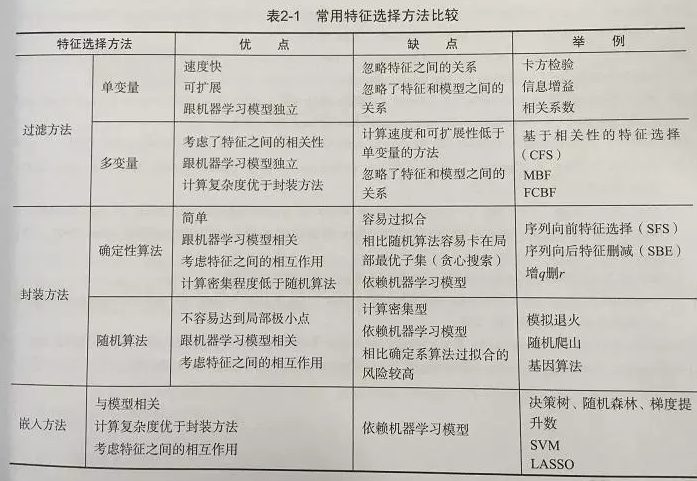
工具介绍
针对过滤方法:
- 若数据量较小,可以使用Sklearn里的feature_selection模块
- 若数据量较大,可以使用Spark MLlib
针对嵌入方法:
- 一般机器学习包的线性模型都支持L1正则,如Spark MLlib和Sklearn
- Sklearn中的随机森林、XGBoost根据增益或者分裂次数对特征进行排序
- Xgbfi提供了多种指标对特征以及特征组合进行排序
实际经验
脱离了label谈特征(重要性)是没有意义的,就如同脱离了业务场景(数据特点)谈模型优劣。
一个常规的经验是,用户花费成本越高的行为,越能体现用户的真实兴趣,比如用户过去一段时间购买商品的类别这个特征,一定强于用户过去一段时间点击商品类别这个特征。但是前者往往较为稀疏,实际效果需要验证。
因此,需要综合考虑特征对label的区分度以及特征泛化能力(稀疏度),来制作特征。
特征可以粗略地分为以下几类:
- 基础属性特征:比如用户的年龄、性别、职业、地域等基础信息;物品的各级类目等基础属性。
- 统计类特征:用户过去不同时间窗口内对物品发生行为的统计,如点击/查看/下载/购买等;同样地,物品在不同时间窗口内的以上行为的统计。
- 上下文特征:如用户当前所处地理位置,当前时刻,当天是否为休息日,发薪日后几天等强时效性特征。
- 高阶交叉特征:两个独立特征交叉在一起的时候,往往会产生奇妙的化学反应,比如“用户所在地域”这个特征为美国,“时间”这个是特征为圣诞前夕,这两个特征组合起来,对“圣诞树”购买的几率就会大幅上升。
- 其他高级特征:如文本特征、图像特征等,用户的评论、签名,物品本身携带的文字内容信息,都携带了用户/物品的特性,通过BoW,Ngram,LDA软聚类,word2vec,fasttext等方式挖掘文本特征;另外,如果用户/物品带有图片,可以通过cnn将图片解析成向量,捕捉到图片特征。