Last updated on 2018-10-5…
原文来自《美团机器学习实践》,Target:真实场景的OCR任务
面临的挑战
成像复杂:噪声、模糊、光线变化、形变
文字复杂:字体、字号、色彩、磨损、笔画宽度任意、方向任意
场景复杂:版面缺失、背景干扰
传统方法
1.文字行提取:版面分析(连通域分析)+行切分(投影分析)
2.单字识别引擎:Maxout网络结构
3.识别流程(两步骤独立):字符切分->单字符识别
4.联合优化:
(1)基于切分的方法
- 过切分模块:将文字行在垂直于基线方向上分割成碎片,使得其中每个碎片至多包含一个字符
- 基于规则:直接在图像
二值化的结果上进行连通域分析和投影分析来确定候补切点的位置 - 基于机器学习:通过离线训练鉴别切点的
二分类器,然后基于该分类器在文字行图像上进行滑窗检测(DeepText、TextBoxes)
- 基于规则:直接在图像
- 动态合并模块:将相邻的笔划根据识别结果组合成可能的字符区域,最优组合方式即对应最佳切分路径和识别结果
- 深度优先策略:全局次优,不适合过长的文字行
- 广度优先策略:Beam Search,剪枝策略(限制扩展的状态数、加入状态约束)
(2)不依赖切分的方法
- 非极大值抑制策略(NMS):
序列学习方法
美团的方法
文字检测
根据版面是否有先验信息,以及文字自身的复杂性(如多角度、多宽度),分为两种场景
1.受控场景的文字检测
如证件、营业执照、卡片
借助图像语义分割来标记文字区域与背景区域(目标检测领域的Faster R-CNN),该框架包含了两个子网络,训练时两个子网络通过端到端的方式联合优化:
- RPN 候选区域生成网络:通过监督学习的方法提取候选区域,给出的是无标签的区域和
粗定位结果 - RCN 区域分类网络:引入类别概念,同时进行候选区域的分类和位置回归,给出
精细的定位结果
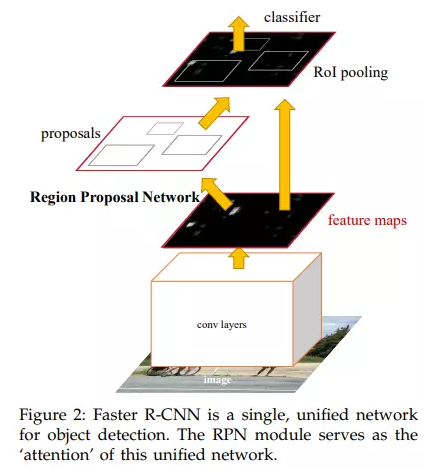
Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks
2.非受控场景的文字检测
如菜单、门头图
利用语义分割中常用的全卷积神经网络(FCN)来进行像素级别的文字/背景标注
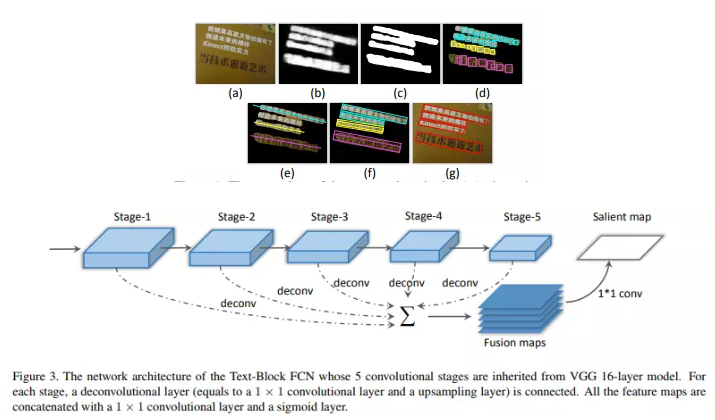
Multi-Oriented Text Detection with Fully Convolutional Networks
文字行识别
我们将整行文字识别问题归结为一个序列学习问题:(卷积层->递归层->解释层)
1.特征提取:卷积神经网络CNN,描述图像的高层语义
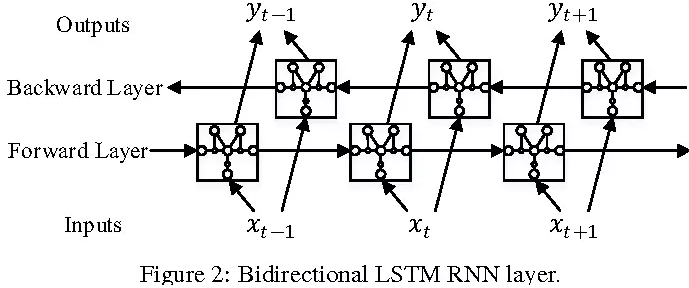
2.序列建模:利用基于双向长短期记忆神经网络(BLSTM)的递归神经网络作为序列学习器,来有效建模序列内部关系
3.损失函数:考虑到输出序列与输入特征帧序列无法对齐,我们直接使用结构化的Loss(序列对序列的损失),另外引入了背景(Blank)类别以吸收相邻字符的混淆性
总结
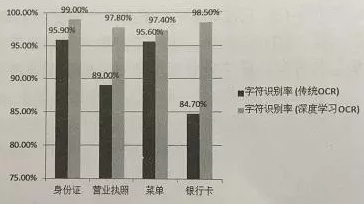
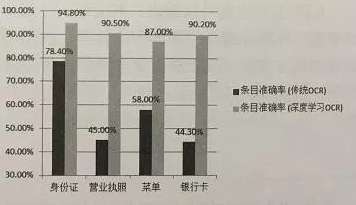
与传统的OCR相比,基于深度学习的OCR在识别率方面有了大幅提升。但对于特定的应用场景(营业执照、菜单、银行卡等),条目准确率还有待提升。